溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用Glide的LruCache”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
使用方法及結果
在項目中直接導入Glide的庫,調用內部的LruCache來看看效果。
LruCache lruCache = new LruCache<String, Integer>(2); lruCache.put("1", 1); lruCache.put("2", 2); lruCache.put("1", 1); lruCache.put("3", 3); System.out.println(lruCache.get("1")); System.out.println(lruCache.get("2")); System.out.println(lruCache.get("3"));簡要說明代碼內容,創建一個空間為2的存儲空間(這里先不透漏內部結構),用put()方法對數據進行存儲,再通過get()對每個數據進行一次獲取操作,然后我們再來看看結果。
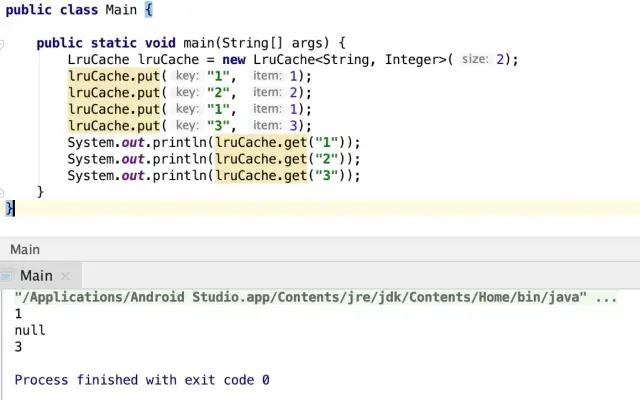
我的天!!2沒了? 這是怎么一回事??為了知道答案,那我們只好進入Glide的庫中看看原因了。
LruCache源碼導讀
先看看LruCache的變量家庭里有哪些小家伙把。
public class LruCache<T, Y> { // 容量為100的雙向鏈表 private final Map<T, Y> cache = new LinkedHashMap<>(100, 0.75f, true); private final long initialMaxSize; // 初始化最大容量 private long maxSize; // 最大容量 private long currentSize; // 已存在容量 }同樣對于LruCache來說不也和HashMap一樣只有三步驟要走嘛,那我就從這三個步驟入手探索一下LruCache好了,但是我們要帶上一個問題出發,initialMaxSize的作用是什么?
new LruCache
public LruCache(long size) { this.initialMaxSize = size; this.maxSize = size; }到這里想來讀者都已經知道套路了,也就初始化了初始化最大容量和最大容量,那就直接下一步。
put(key, value)
public synchronized Y put(@NonNull T key, @Nullable Y item) { // 返回值就是一個1 final int itemSize = getSize(item); // 如果1大于等于最大值就無操作 // 也就說明整個初始化的時候并不能將size設置成1 if (itemSize >= maxSize) { //用于重寫的保留方法 onItemEvicted(key, item); return null; } // 對當前存在數據容量加一 if (item != null) { currentSize += itemSize; } @Nullable final Y old = cache.put(key, item); if (old != null) { currentSize -= getSize(old); if (!old.equals(item)) { onItemEvicted(key, old); } } evict(); // 1 --> return old; } // 由注釋1直接調用的方法 private void evict() { trimToSize(maxSize); // 2 --> } // 由注釋2直接調用的方法 protected synchronized void trimToSize(long size) { Map.Entry<T, Y> last; Iterator<Map.Entry<T, Y>> cacheIterator; // 說明當前的容量大于了最大容量 // 需要對最后的數據進行一個清理 while (currentSize > size) { cacheIterator = cache.entrySet().iterator(); last = cacheIterator.next(); final Y toRemove = last.getValue(); currentSize -= getSize(toRemove); final T key = last.getKey(); cacheIterator.remove(); onItemEvicted(key, toRemove); } }這是一個帶鎖機制的方法,通過對當前容量和最大容量的判斷,來抉擇是否需要把我們的數據進行一個刪除。但是問題依舊存在,initialMaxSize的作用是什么?,我們能夠知道的是maxSize是一個用于控制容量大小的值。
get()
public synchronized Y get(@NonNull T key) { return cache.get(key); }那這就是調用了LinkedHashMap中的數據,但是終究還是沒有說出initialMaxSize的作用。
關于initialMaxSize
這里就不買關子了,因為其實就我的視角來看這個initialMaxSize確實是沒啥用處的。哈哈哈哈哈!!!但是,又一個地方用到了它。
public synchronized void setSizeMultiplier(float multiplier) { if (multiplier < 0) { throw new IllegalArgumentException("Multiplier must be >= 0"); } maxSize = Math.round(initialMaxSize * multiplier); evict(); }也就是用于調控我們的最大容量大小,但是我覺得還是沒啥用,可是是我太菜了吧,這個方法沒有其他調用它的方法,是一個我們直接在使用過程中使用的,可能和數據多次使用的一個保存之類的問題相關聯把,場景的話也就類似Glide的圖片緩存加載把。也希望知道的讀者能給我一個解答。
LinkedHashMap
因為操作方式和HashMap一致就不再復述,就看看他的節點長相。
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> { // 存在前后節點,也就是我們所說的雙向鏈表 LinkedHashMapEntry<K,V> before, after; LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }但是到這里,我又出現了一個問題,為什么我沒有看到整個數據的移動?也就是最近使用的數據應該調換到最后開始的位置,他到底實在哪里進行處理的呢?做一個猜想好了,既然是使用了put()才會造成雙向鏈表中數據的變換,那我們就應該是需要進入對LinkedHashMap.put()方法中進行查詢。
當然有興趣探索的讀者們,我需要提一個醒,就是這次的調用不可以直接進行對put()進行查詢,那樣只會調用到一個接口函數,或者是抽象類函數,最適合的方法還是使用我們的斷點來進行探索查詢。
但是經過一段努力后,不斷深度調用探索發現這樣的問題,他最后會調用到這樣的問題。
// Callbacks to allow LinkedHashMap post-actions void afterNodeAccess(Node<K,V> p) { } // 把數據移動到最后一位 void afterNodeInsertion(boolean evict) { } void afterNodeRemoval(Node<K,V> p) { }這是之前我們在了解HashMap是并沒有發現幾個方法,上面也明確寫著為LinkedHashMap保留。哇哦!!那我們的操作肯定實在這些里面了。
// --> HashMap源碼第656行附近調用到下方方法 // 在putVal()方法內部存在這個出現 afterNodeAccess(e); // --> LinkedHashMap對其具體實現 // 就是將當前數據直接推到最后一個位置 // 也就是成為了最近剛使用過的數據 void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMapEntry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMapEntry<K,V> p = (LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }好了,自此我們也就清楚了整個鏈表的變換過程了。
實戰:手擼LruCache
這是一個非常緊張刺激的環節了,擼代碼前,我們來找找思路好了。
(1)存儲容器用什么? 因為LinkedHashMap的思路太過冗長,我們用數組來重新完成整個代碼的構建
(2)關鍵調用方法put()、get()以及put()涉及的已存在變量移位。
哇哦!看來要做的事情也并沒有這么多,那我們就先來看看第一次構造出來的框架好了。
public class LruCache { private Object objects[]; private int maxSize; private int currentSize; public LruCache(int size){ objects = new Object[size]; maxSize = size; } /** * 插入item * @param item */ public void put(Object item){ } /** * 獲取item * @param item */ public Object get(Object item){ return null; } /** * 根據下標對應,將后續數組移位 * @param index */ public void move(int index){ } }因為只要是數組變換就存在移位,所以移位操作是必不可少的。那我們現在的工作也就是把數據填好了,對應的移位是怎么樣的操作的思路了。
public class LruCache { public Object objects[]; private int maxSize; public int currentSize; public LruCache(int size) { objects = new Object[size]; maxSize = size; } /** * 插入item * * @param item */ public void put(Object item) { // 容量未滿時分成兩種情況 // 1。 容器內存在 // 2。 容器內不存在 int index = search(item); if (index == -1) { if (currentSize < maxSize) { //容器未滿,直接插入 objects[currentSize] = item; currentSize++; } else { // 容器已滿,刪去頭部插入 move(0); objects[currentSize - 1] = item; } }else { move(index); } } /** * 獲取item * * @param item */ public Object get(Object item) { int index = search(item); return index == -1 ? null : objects[index]; } /** * 根據下標對應,將后續數組移位 * * @param index */ public void move(int index) { Object temp = objects[index]; // 將后續數組移位 for (int i = index; i < currentSize - 1; i++) { objects[i] = objects[i + 1]; } objects[currentSize - 1] = temp; } /** * 搜尋數組中的數組 * 存在則返回下標 * 不存在則返回 -1 * @param item * @return */ private int search(Object item) { for (int i = 0; i < currentSize; i++) { if (item.equals(objects[i])) return i; } return -1; }因為已經真的寫的比較詳細了,也沒什么難度的擼了我的20分鐘,希望讀者們能夠快入入門,下面給出我的一份測試樣例,結束這個話題。

“怎么使用Glide的LruCache”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





