溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要給大家分享的是keras如何處理欠擬合和過擬合,文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
baseline
import tensorflow.keras.layers as layers
baseline_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
baseline_history = baseline_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)小模型
small_model = keras.Sequential(
[
layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
small_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
small_model.summary()
small_history = small_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)大模型
big_model = keras.Sequential(
[
layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(512, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
big_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
big_model.summary()
big_history = big_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)繪圖比較上述三個模型
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('small', small_history),
('big', big_history)])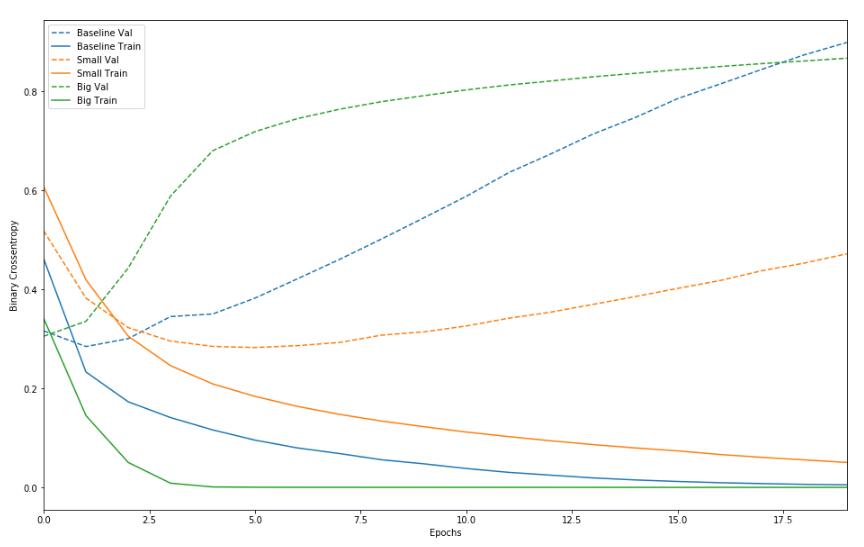
三個模型在迭代過程中在訓練集的表現都會越來越好,并且都會出現過擬合的現象
大模型在訓練集上表現更好,過擬合的速度更快
l2正則減少過擬合
l2_model = keras.Sequential(
[
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model.summary()
l2_history = l2_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
plot_history([('baseline', baseline_history),
('l2', l2_history)])
可以發現正則化之后的模型在驗證集上的過擬合程度減少
添加dropout減少過擬合
dpt_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dropout(0.5),
layers.Dense(16, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
]
)
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
dpt_model.summary()
dpt_history = dpt_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
plot_history([('baseline', baseline_history),
('dropout', dpt_history)])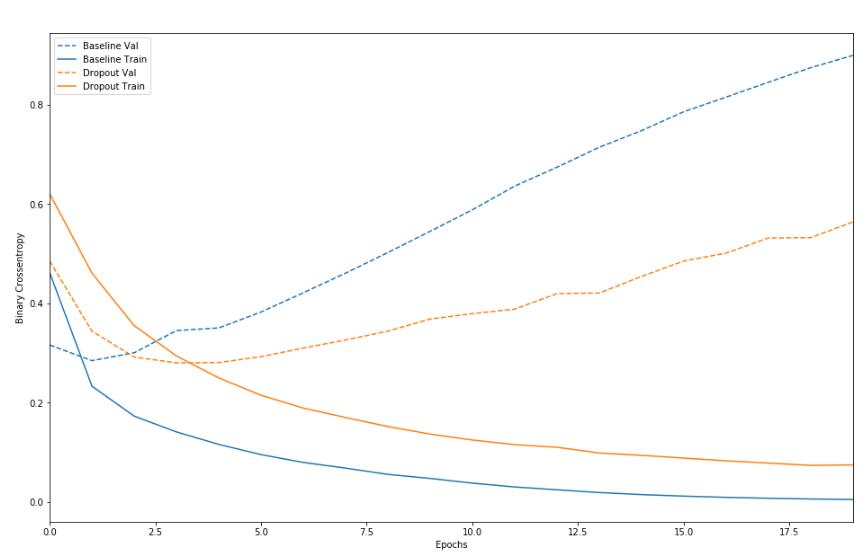
批正則化
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()看完這篇關于keras如何處理欠擬合和過擬合的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





