溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下大數據開發中欠擬合、過擬合的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
這里先介紹一個名詞,模型容量:通俗的講,模型的容量或表達能力,是指模型擬合復雜函數的能力。當模型的容量越大時,函數的假設空間就越大,就越有可能找到一個函數更逼近真實分布的函數模型。
注:在卷積神經網絡中,模型容量通常由網絡層數、待優化參數的量來衡量。
(1)當模型的容量過大時,網絡模型除了學習到訓練集數據的模態之外,還把額外的觀測誤差也學習進來,導致學習的模型在訓練集上面表現較好,但是在未見的樣本上表現不佳,也就是泛化能力偏弱,我們把這種現象叫做過擬合(Overfitting)。
(2)當模型的容量過小時,模型不能夠很好的學習到訓練集數據的模態,導致訓練集上表現不佳,同時在未見的樣本上表現也不佳,我們把這種現象叫做欠擬合(Underfitting)。
那么在深度學習過程中,如何去選擇合適的模型的容量呢?
統計學習理論很難給出神經網絡所需要的最小容量,但是我們卻可以根據奧卡姆剃刀原理(Occam’s razor)來指導神經網絡的設計(也就是模型容量的選擇)。
奧卡姆剃刀原理是由 14 世紀邏輯學家、圣方濟各會修士奧卡姆的威廉(William of Occam)提出的一個解決問題的法則 。用在神經網絡設計過程中,也就是說,如果兩層的神經網絡結構能夠很好的表達真實模型,那么三層的神經網絡也能夠很好的表達,但是我們應該優先選擇使用更簡單的兩層神經網絡,因為它的參數量更少,更容易訓練、更容易通過較少的訓練樣本獲得不錯的泛化誤差。
通過驗證集可以判斷網絡模型是否過擬合或者欠擬合,從而為調整網絡模型的容量提供判斷依據。
對于神經網絡來說,網絡的層數和參數量是網絡容量很重要的參考指標。
因此,在模型設計過程中,解決過(欠)擬合的一般方法是:
(1)當發現模型過擬合時,需要減小網絡的容量。可以通過減少網絡的層數,減少每層中網絡參數量的規模實現。
(2)當發現模型欠擬合時,需要增大網絡的容量。可以通過增加網絡的層數,減少每層網絡參數來實現。
為了演示網絡層數對網絡容量的影響,我們做了一個可視化的決策邊界的而分類實驗,實驗效果如下:
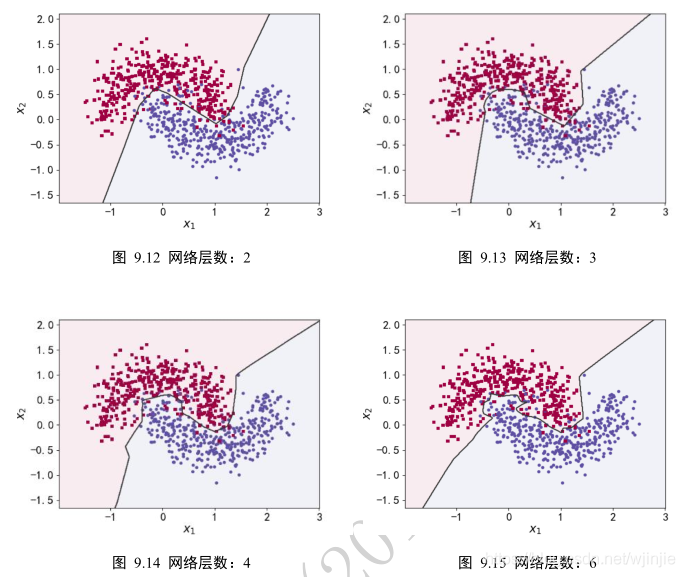
實驗結論:
如圖中所示,可以看到,隨著網絡層數的加深,學習到的模型決策邊界越來越逼近訓練樣本,出現了過擬合現象。對于此任務,2 層的神經網絡即可獲得不錯的泛化能力,更深層數的網絡并沒有提升性能,反而過擬合,泛化能力變差,同時計算代價更高。
以上是“大數據開發中欠擬合、過擬合的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





