溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“MySQL查詢語句執行流程是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“MySQL查詢語句執行流程是什么”文章吧。
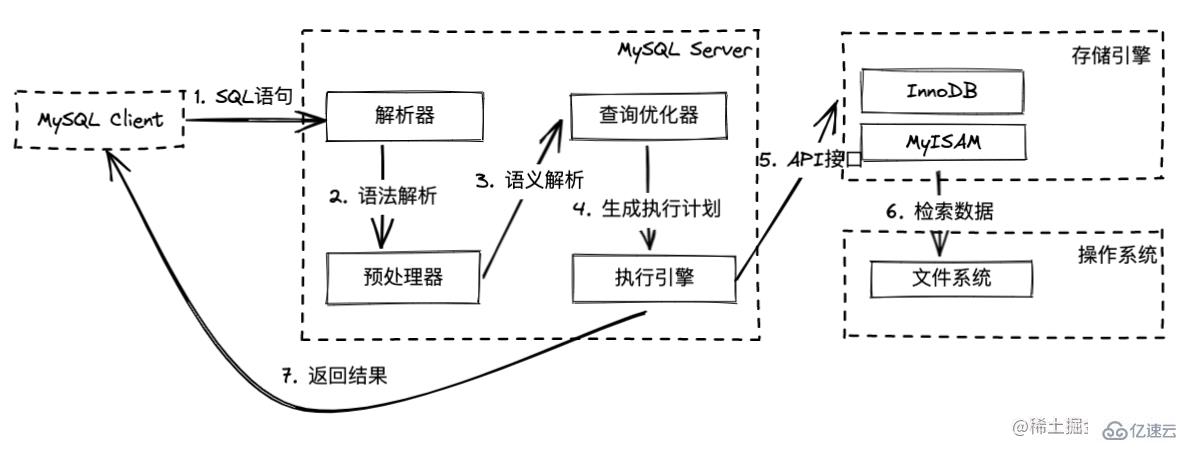
解析器的作用是對客戶端傳來的 SQL 語句進行以下工作:
語法解析:檢查 SQL 語句的語法,括號、引號是否閉合等
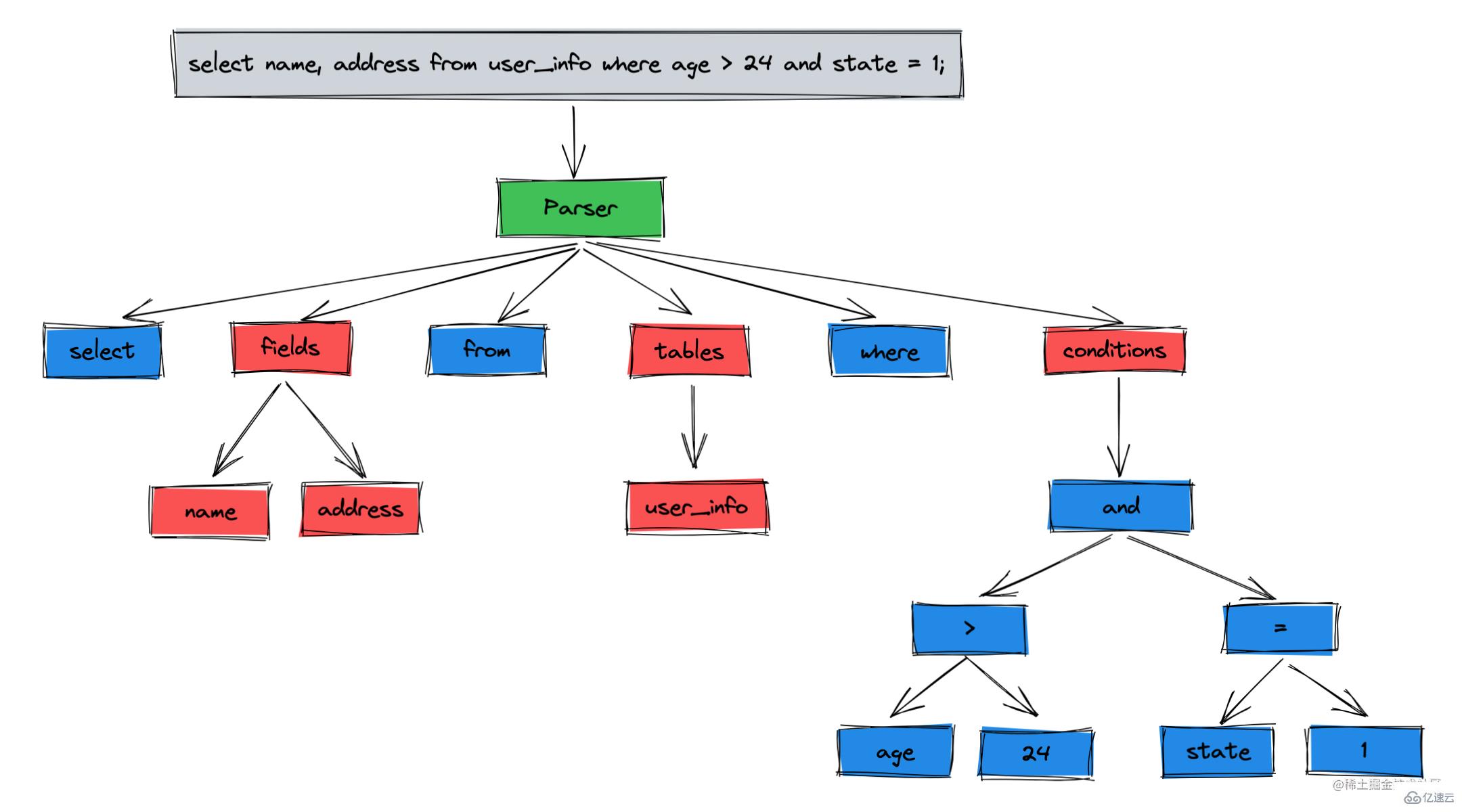
詞法解析:把 SQL 語句中的關鍵詞、表名、字段名拆分成一個個節點,最終得到一顆解析樹
解析器主要是檢查語法詞法方面,但是如果語法詞法都正確,但是表、字段是不存在的,那么這段 SQL 語句也是無法正確執行的。
所以預處理器的作用是:語義解析,判斷解析樹的語義是否正確,表、字段這些是否存在,預處理后會得到一顆新的解析樹。
查詢優化器結構
在 MySQL 中一條 SQL 語句的執行方式有多種,雖然最終都會得到相同的結果,但是存在開銷上的差異,具體選擇哪一種執行方式是由查詢優化器來決定的。比如說:
表中有多個索引可以選擇,具體選擇哪一個索引
當我們對多張表進行關聯查詢時,以哪一張表的數據為基準表
查詢優化器是基于開銷(cost)的優化器,它的工作原理是根據解析樹生成的多種執行計劃,會評估各種執行方式所需的開銷(cost),最終會得到一個開銷最小的執行計劃作為最終方案。
但是這個開銷最小的執行方式不一定是最優的執行方式,比如本該使用索引,卻進行了全表掃描等。雖然查詢優化器中有《優化》兩個字,但是這個優化并不是萬能的,很多時候更加需要考慮 SQL 語句書寫得是否合理。
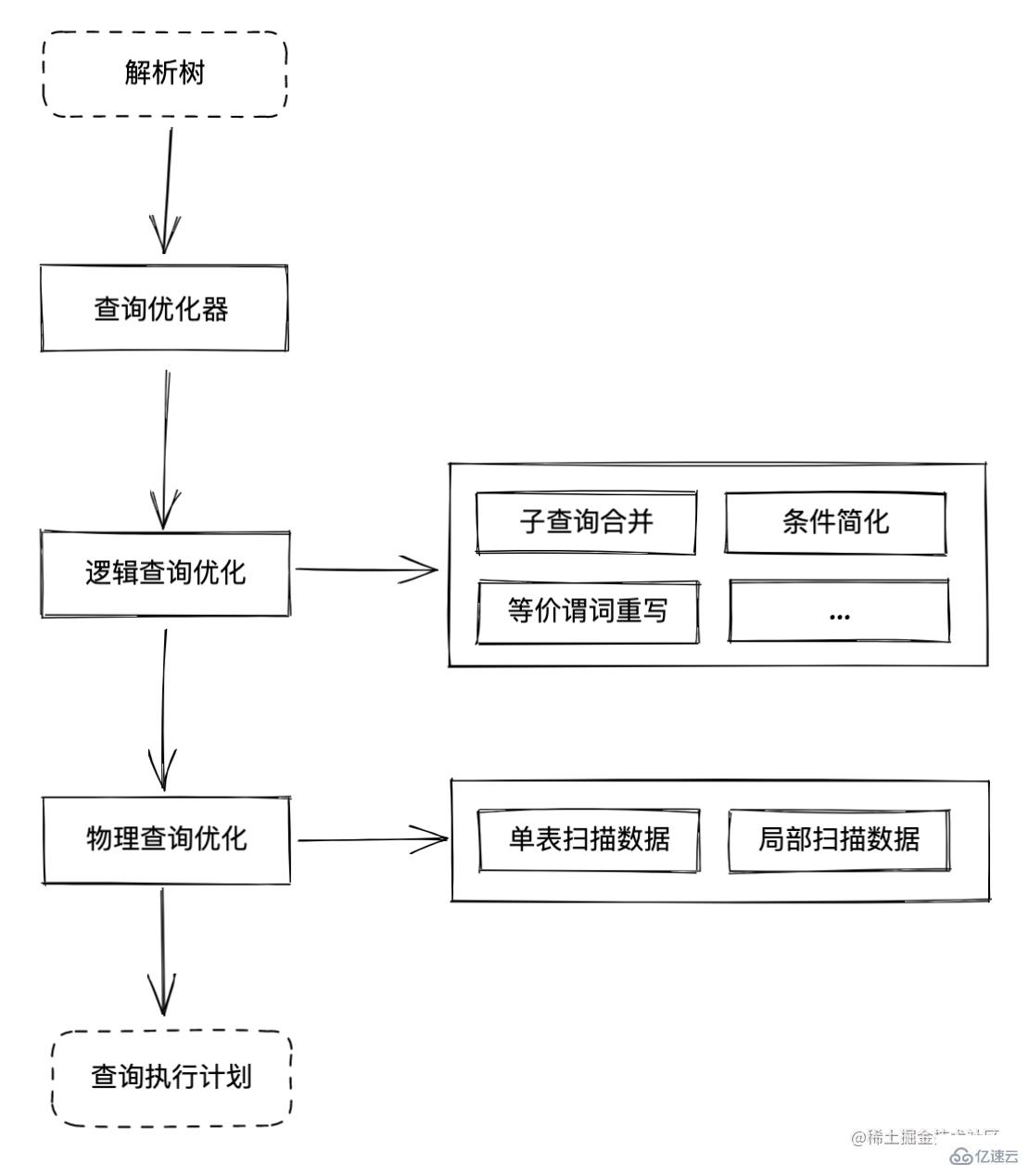
邏輯查詢優化主要負責進行一些關系代數對 SQL 語句進行優化,從而使 SQL 語句執行效率更高
邏輯查詢優化我們可以使用幾個案例來簡單理解
子查詢合并
合并前
SELECT * FROM t1 WHERE a1<10 AND (
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2)
);
合并后
SELECT * FROM t1 WHERE a1<10 AND (
EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2)
);
把多個子查詢通過合并查詢條件而合并查詢,把多次連接操作減少為單次表掃描和單次連接
等價謂詞重寫
像我們熟悉的 like 模糊查詢,% 寫在條件后面才會進行索引范圍查詢,其實這是查詢優化器的功勞
假設使用的條件都是有建立索引的,重寫前
SELECT * FROM USERINFO WHERE name LIKE 'Abc%';
重寫后
SELECT * FROM USERINFO WHERE name >= 'Abc' AND name < 'Abd';
這就是為什么能進行索引范圍查詢的答案
條件簡化
條件簡化也是利用一些等式、代數關系來實現簡化
去除表達式中的冗余括號,減少語法分析時產生的AND和OR 樹的層 次,比如 ((a AND b) AND (c AND d)) 簡化為 a AND b AND c AND d
常量傳遞,比如 col1 = col2 AND col2 = 3 簡化為 col1 = 3 AND col2 = 3
表達式計算,對于一些可直接求解的表達式會轉換為最終的計算結果,比如 col1 = 1+2 簡化為 col1 = 3
物理查詢優化主要做的工作是根據 SQL 語句分別對多種執行計劃進行開銷的評估
物理查詢優化主要解決以下幾個問題:
單表掃描中采用哪種方式是開銷最小的(掃描索引+回表 or 全表掃描)
存在表連接的時候使用哪種連接方式是開銷最小的
簡單了解一下代價評估,代價評估是基于 CPU 代價和 IO 代價兩個維度的
| 掃描方式 | 代價評估公式 |
|---|---|
| 順序掃描 | N_page * a_page_IO_time + N_tuple * a_tuple_CPU_time |
| 索引掃描 | C_index + N_page_index * a_page_IO_time |
上述參數說明如下:
a_page_IO_time, 一個數據頁加載的IO耗時
N_page,數據頁數量
N_tuple,元組數(元組理解為一行數據)
a_tuple_CPU_time,一個元組從數據頁中解析的CPU耗時
C_index,索引的IO耗時
N_page_index,索引頁數量
關于索引成本計算可以參考這篇文章:MySQL查詢為什么選擇使用這個索引?——基于MySQL 8.0.22索引成本計算
執行計劃是查詢優化器的產物,最終會交給存儲引擎進行執行。執行計劃可以幫助我們得知 MySQL 會怎么執行這條 SQL 語句。
使用 explain 關鍵字查看 SQL 語句的執行計劃,可以得到以下信息:
id:嵌套查詢中查詢的執行順序
possible_keys:本次查詢可能用到的索引
Key:實際用到的索引
rows:得到結果大概要檢索多少行數據
select_type多表之間的連接類型
extra:額外的信息,是否有索引覆蓋、索引下推等
MySQL 服務端規定了數據如何存儲、如何提取、如何更新的規范,這個規范由存儲引擎來實現,不同的存儲引擎的實現方式不同,所以不同的存儲引擎會呈現其獨特的功能和特點。其中最常用的存儲引擎是 InnoDB 和 MyISAM
簡單說說這兩款存儲引擎的特點
InnoDB:
支持外鍵、事務,保證了數據的完整性和一致性
支持更細的鎖粒度,對鎖的控制更好,讀寫效率更高
MyISAM
不支持事務,只支持行鎖,適合數據只讀的場景
存儲引擎方面暫時先不展開,會在其他文章繼續穿插他們的對比,以及會詳細分析 InnoDB 更新數據的流程
以上就是關于“MySQL查詢語句執行流程是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





