溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Python爬蟲之requests如何使用”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Python爬蟲之requests如何使用”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
requests 庫是一個常用的用于 http 請求的模塊,它使用 python 語言編寫,可以方便的對網頁進行爬取,是學習 python 爬蟲的較好的http請求模塊。 它基于 urllib 庫,但比 urllib 方便很多,能完全滿足我們 HTTP 請求以及處理 URL 資源的功能。
如果已經安裝了 anaconda ,就已經自帶了 requets 庫(建議新手安裝 Python 的話直接安裝 anaconda 就好了,可以省去很多繁瑣的安裝過程的)。如果確實沒有安裝,可以通過以下兩種方式來進行安裝
在有pip的情況下直接客戶端輸入命令下載
pip install requests
由于 pip 命令可能安裝失敗所以有時我們要通過下載第三方庫文件來進行安裝。
下載文件到本地之后,解壓到 python 安裝目錄。
之后打開解壓文件,在此處運行命令行并輸入:
python setup.py install
即可。
之后我們測試 requests 模塊是否安裝正確,在交互式環境中輸入
import requests
如果沒有任何報錯,說明requests模塊我們已經安裝成功了
在時用requests庫要導入requests模塊
import requests
接下來我們就可以嘗試獲取某個頁面
import requests
r = requests.get('http://www.baidu.com')
print(r.text)現在,我們有一個名為 r 的 Response 對象。我們可以從這個對象中獲取所有我們想要的信息
除了get請求我們還有PUT,DELETE,HEAD 以及 OPTIONS 這些http請求方式
接下來我們先看看get請求
上面的例子就是我們用get方法獲取到了百度的首頁,并且輸出打印結果為
<!DOCTYPE html>
<!--STATUS OK--><html> <head>......</body> </html>
Requests 允許你使用 params 關鍵字參數,以一個字符串字典來提供這些參數。舉例來說,如果你想傳遞 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代碼:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)通過print(r.url),可以打印輸出URL
http://httpbin.org/get?key2=value2&key1=value1
注意字典里值為 None 的鍵都不會被添加到 URL 的查詢字符串里。
你還可以將一個列表作為值傳入:
payload = {‘key1’: ‘value1’, ‘key2’: [‘value2’, ‘value3’]}
范例
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(r.text)輸出結果
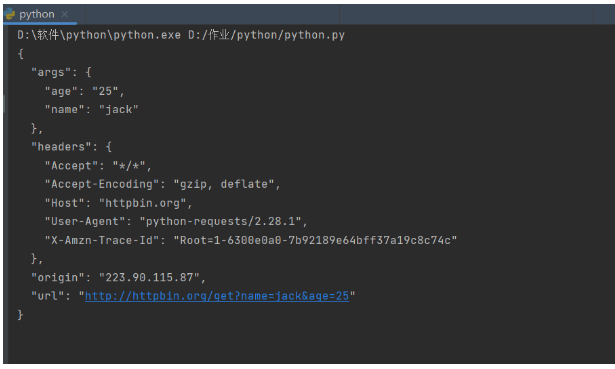
在這里,我們將請求的參數封裝為一個 json 格式的數據,然后在 get 方法中傳給 params 參數,這樣就完成了帶參數的 GET 請求 URL 的拼接,省去了自己拼接 http://httpbin.org/get?age=22&name=jack 的過程,非常的方便。
此外,在上面我們看到返回的r.tetx雖然是個字符串,但是它其實是個JSON格式的字符串,我們可以通過 r.json() 方法來將其直接轉換為JSON格式數據,從而可以直接解析,省去了引入 json 模塊的麻煩。示例如下
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(type(r.json()))
print(r.json())
print(r.json().get('args').get('age'))輸出結果
<class 'dict'>
{'args': {'age': '25', 'name': 'jack'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.28.1', 'X-Amzn-Trace-Id': 'Root=1-6300e24d-71111778036e3f8339b55886'}, 'origin': '223.90.115.87', 'url': 'http://httpbin.org/get?name=germey&age=25'}
25
從上面的例子中我們發現我們可以輕松獲取網頁的html文檔,但是如果我們在瀏覽網址時想要獲取的是圖片、視頻、音頻這些內容的話又該怎么辦呢?
我們知道視頻音頻這些不過就是二進制碼,所以我們獲取二進制碼就能夠獲取到這些形形色色的圖片視頻了,接下來我們看看如何獲取這些二進制碼
接下來以baidu的站點圖標為例:
import requests
r = requests.get('https://baidu.com/favicon.ico')
print(r.text)
print(r.content)
......
b'\x00\......x00'使用content我們可以輸出獲取的文檔的二進制碼,但是我們又該如何處理這些二進制碼呢?
其實很簡單直接將其保留到本地就可以了
import requests
r = requests.get('https://baidu.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)運行之后就發現我們成功爬取了圖片,其實其他之類的視頻也是這樣操作的

接下來就是另外一種請求方式post請求
先看看是如何進行請求的
import requests
data = {'name': 'jack', 'age': '25'}
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)輸出結果
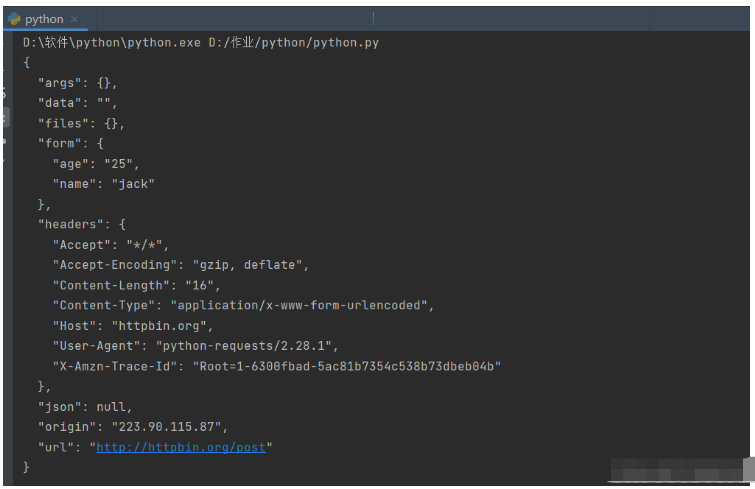
在這里我們將需要的表單數據通過data進行提交,完成一次post請求
同時,你還可以為 data 參數傳入一個元組列表。在表單中多個元素使用同一 key 的時候,這種方式尤其有效:
data = (('key1', 'value1'), ('key1', 'value2'))范例
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
print(r.text)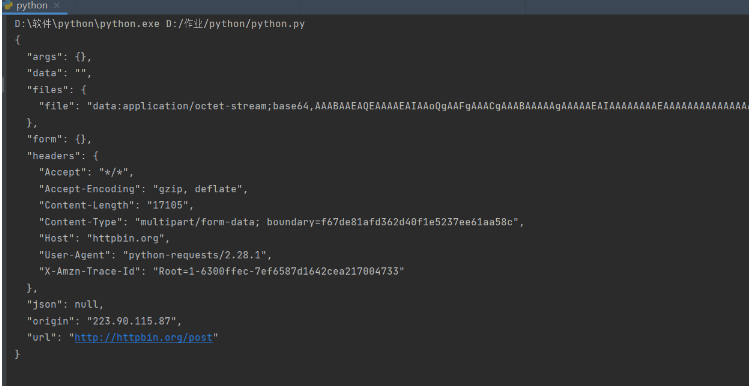
我們通過傳入files參數來實現文件上傳,不過前提是open方法中的文件需要存在(這里我上傳的文件就是在get請求里面獲取的百度圖標),在這里不寫路徑表示該文件在當前目錄下, 否則需要寫上完整的路徑。這個網站會返回響應,里面包含 files 這個字段,而 form 字段是空的,這證明文件上傳部分會單獨有一個 files 字段來標識。
r.status_code:獲得返回的響應狀態碼
r.status_code == requests.codes.ok:內置狀態碼查詢
Response.raise_for_status():拋出異常的響應狀態
利用前兩個方法我們可以獲得響應的狀態
r = requests.get('http://httpbin.org/get')
r.status_code
200查詢狀態
r.status_code == requests.codes.ok True
如果我們發送一個錯誤請求獲取,我們就可以使用Response.raise_for_status()來拋出異常
r = requests.get('http://httpbin.org/status/404')
r.status_code
404
bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error如果響應正常就不會拋出異常,返回以None
讀到這里,這篇“Python爬蟲之requests如何使用”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





