溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
使用python爬蟲庫requests,urllib爬取今日頭條街拍美圖
代碼均有注釋
import re,json,requests,os
from hashlib import md5
from urllib.parse import urlencode
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
from multiprocessing import Pool
#請求索引頁
def get_page_index(offset,keyword):
#傳送的數據
data={
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 1
}
#自動編碼為服務器可識別的url
url="https://www.toutiao.com/search_content/?"+urlencode(data)
#異常處理
try:
#獲取返回的網頁
response=requests.get(url)
#判斷網頁的狀態碼是否正常獲取
if response.status_code==200:
#返回解碼后的網頁
return response.text
#不正常獲取,返回None
return None
except RequestException:
#提示信息
print("請求索引頁出錯")
return None
#解析請求的索引網頁數據
def parse_page_index(html):
#json加載轉換
data=json.loads(html)
#數據為真,并且data鍵值存在與數據中
if data and 'data' in data.keys():
#遍歷返回圖集所在的url
for item in data.get('data'):
yield item.get('article_url')
#圖集詳情頁請求
def get_page_detail(url):
#設置UA,模擬瀏覽器正常訪問
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#異常處理
try:
response=requests.get(url,headers=head)
if response.status_code==200:
return response.text
return None
except RequestException:
print("請求詳情頁出錯")
return None
#解析圖集詳情頁的數據
def parse_page_detail(html,url):
#異常處理
try:
#格式轉換與圖集標題提取
soup=BeautifulSoup(html,'lxml')
title=soup.select('title')[0].get_text()
print(title)
#正則查找圖集鏈接
image_pattern = re.compile('gallery: (.*?),\n', re.S)
result = re.search(image_pattern, html)
if result:
#數據的優化
result=result.group(1)
result = result[12:]
result = result[:-2]
#替換
result = re.sub(r'\\', '', result)
#json加載
data = json.loads(result)
#判斷數據不為空,并確保sub——images在其中
if data and 'sub_images' in data.keys():
#sub_images數據提取
sub_images=data.get('sub_images')
#列表數據提取
images=[item.get('url') for item in sub_images]
#圖片下載
for image in images:download_images(image)
#返回字典
return {
'title':title,
'url':url,
'images':images
}
except Exception:
pass
#圖片url請求
def download_images(url):
#提示信息
print('正在下載',url)
#瀏覽器模擬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#異常處理
try:
response = requests.get(url, headers=head)
if response.status_code == 200:
#圖片保存
save_image(response.content)
return None
except RequestException:
print("請求圖片出錯")
return None
#圖片保存
def save_image(content):
#判斷文件夾是否存在,不存在則創建
if '街拍' not in os.listdir():
os.makedirs('街拍')
#設置寫入文件所在文件夾位置
os.chdir('E:\python寫網路爬蟲\CSDN爬蟲學習\街拍')
#路徑,名稱,后綴
file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
#圖片保存
with open(file_path,'wb') as f:
f.write(content)
f.close()
#主函數
def mian(offset):
#網頁獲取
html=get_page_index(offset,'街拍')
#圖集url
for url in parse_page_index(html):
if url!=None:
#圖集網頁詳情
html=get_page_detail(url)
#圖集內容
result=parse_page_detail(html,url)
if __name__ == '__main__':
#創建訪問的列表(0-9)頁
group=[i*10 for i in range(10)]
#創建多線程進程池
pool=Pool()
#進程池啟動,傳入的數據
pool.map(mian,group)
爬取圖片如下
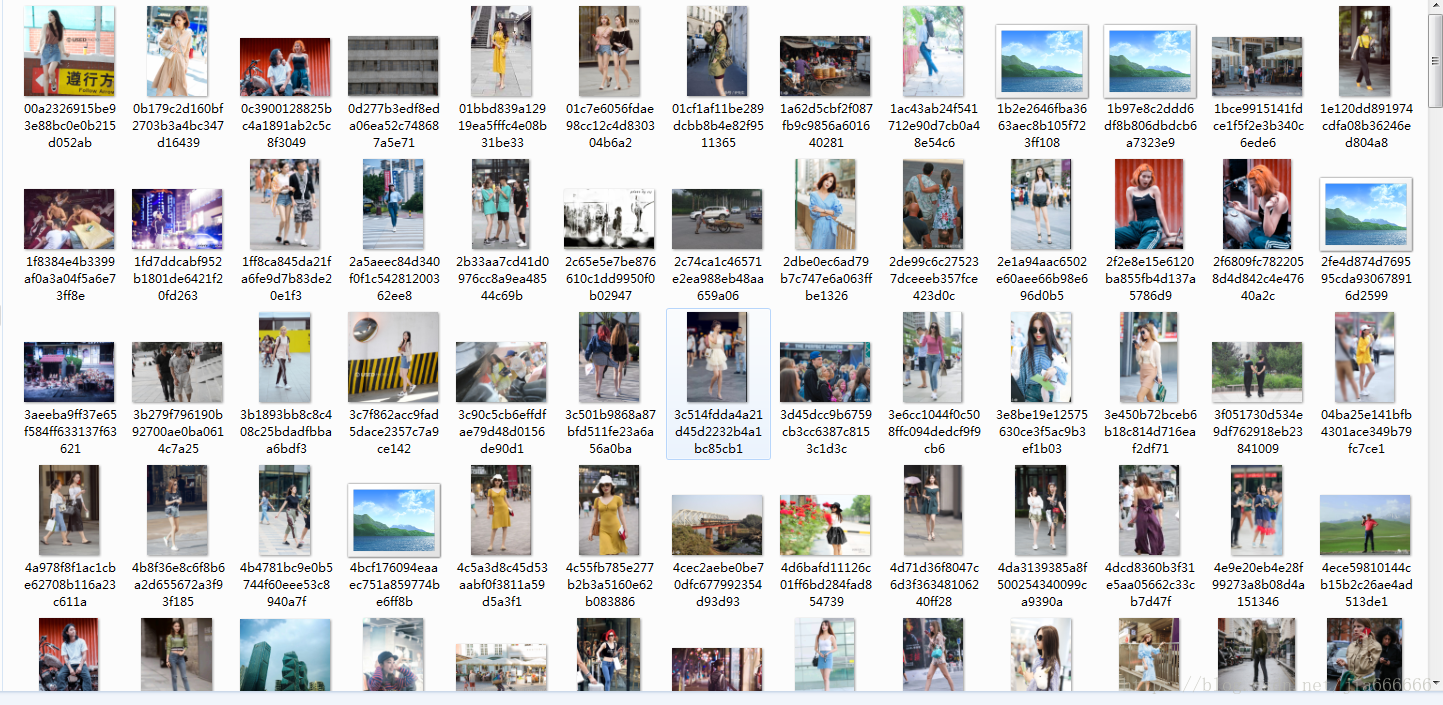
本文主要講解了python爬蟲庫requests、urllib與OS模塊結合使用爬取今日頭條搜索內容的實例,更多關于python爬蟲相關知識請查看下面的相關鏈接
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





