溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“SpringBoot HikariCP連接池怎么創建”,在日常操作中,相信很多人在SpringBoot HikariCP連接池怎么創建問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”SpringBoot HikariCP連接池怎么創建”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我們首先來看一下 Java 中公用的池化包 Commons Pool 2,來了解一下對象池的一般結構。
根據我們的業務需求,使用這套 API 能夠很容易實現對象的池化管理。
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.11.1</version> </dependency>
GenericObjectPool 是對象池的核心類,通過傳入一個對象池的配置和一個對象的工廠,即可快速創建對象池。
public GenericObjectPool( final PooledObjectFactory<T> factory, final GenericObjectPoolConfig<T> config)
Redis 的常用客戶端 Jedis,就是使用 Commons Pool 管理連接池的,可以說是一個最佳實踐。下圖是 Jedis 使用工廠創建對象的主要代碼塊。
對象工廠類最主要的方法就是makeObject,它的返回值是 PooledObject 類型,可以將對象使用 new DefaultPooledObject<>(obj) 進行簡單包裝返回。
redis.clients.jedis.JedisFactory,使用工廠創建對象。
@Override
public PooledObject<Jedis> makeObject() throws Exception {
Jedis jedis = null;
try {
jedis = new Jedis(jedisSocketFactory, clientConfig);
//主要的耗時操作
jedis.connect();
//返回包裝對象
return new DefaultPooledObject<>(jedis);
} catch (JedisException je) {
if (jedis != null) {
try {
jedis.quit();
} catch (RuntimeException e) {
logger.warn("Error while QUIT", e);
}
try {
jedis.close();
} catch (RuntimeException e) {
logger.warn("Error while close", e);
}
}
throw je;
}
}我們再來介紹一下對象的生成過程,如下圖,對象在進行獲取時,將首先嘗試從對象池里拿出一個,如果對象池中沒有空閑的對象,就使用工廠類提供的方法,生成一個新的。
public T borrowObject(final Duration borrowMaxWaitDuration) throws Exception {
//此處省略若干行
while (p == null) {
create = false;
//首先嘗試從池子中獲取。
p = idleObjects.pollFirst();
// 池子里獲取不到,才調用工廠內生成新實例
if (p == null) {
p = create();
if (p != null) {
create = true;
}
}
//此處省略若干行
}
//此處省略若干行
}那對象是存在什么地方的呢?這個存儲的職責,就是由一個叫作LinkedBlockingDeque 的結構來承擔的,它是一個雙向的隊列。
接下來看一下 GenericObjectPoolConfig 的主要屬性:
// GenericObjectPoolConfig本身的屬性 private int maxTotal = DEFAULT_MAX_TOTAL; private int maxIdle = DEFAULT_MAX_IDLE; private int minIdle = DEFAULT_MIN_IDLE; // 其父類BaseObjectPoolConfig的屬性 private boolean lifo = DEFAULT_LIFO; private boolean fairness = DEFAULT_FAIRNESS; private long maxWaitMillis = DEFAULT_MAX_WAIT_MILLIS; private long minEvictableIdleTimeMillis = DEFAULT_MIN_EVICTABLE_IDLE_TIME_MILLIS; private long evictorShutdownTimeoutMillis = DEFAULT_EVICTOR_SHUTDOWN_TIMEOUT_MILLIS; private long softMinEvictableIdleTimeMillis = DEFAULT_SOFT_MIN_EVICTABLE_IDLE_TIME_MILLIS; private int numTestsPerEvictionRun = DEFAULT_NUM_TESTS_PER_EVICTION_RUN; private EvictionPolicy<T> evictionPolicy = null; // Only 2.6.0 applications set this private String evictionPolicyClassName = DEFAULT_EVICTION_POLICY_CLASS_NAME; private boolean testOnCreate = DEFAULT_TEST_ON_CREATE; private boolean testOnBorrow = DEFAULT_TEST_ON_BORROW; private boolean testOnReturn = DEFAULT_TEST_ON_RETURN; private boolean testWhileIdle = DEFAULT_TEST_WHILE_IDLE; private long timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS; private boolean blockWhenExhausted = DEFAULT_BLOCK_WHEN_EXHAUSTED;
參數很多,要想了解參數的意義,我們首先來看一下一個池化對象在整個池子中的生命周期。
如下圖所示,池子的操作主要有兩個:一個是業務線程,一個是檢測線程。
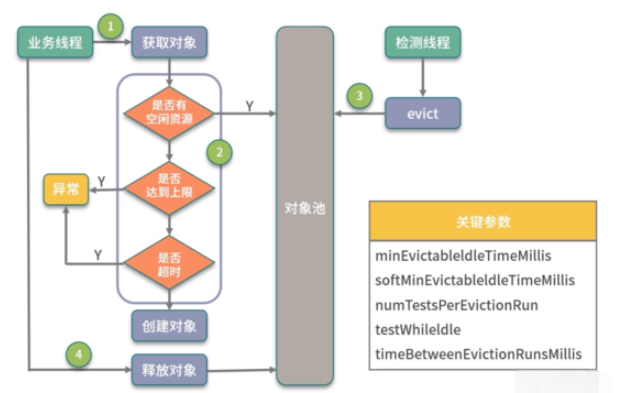
對象池在進行初始化時,要指定三個主要的參數:
maxTotal 對象池中管理的對象上限
maxIdle 最大空閑數
minIdle 最小空閑數
其中 maxTotal 和業務線程有關,當業務線程想要獲取對象時,會首先檢測是否有空閑的對象。
如果有,則返回一個;否則進入創建邏輯。此時,如果池中個數已經達到了最大值,就會創建失敗,返回空對象。
對象在獲取的時候,有一個非常重要的參數,那就是最大等待時間(maxWaitMillis),這個參數對應用方的性能影響是比較大的。該參數默認為 -1,表示永不超時,直到有對象空閑。
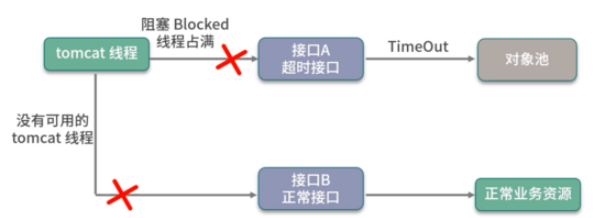
如下圖,如果對象創建非常緩慢或者使用非常繁忙,業務線程會持續阻塞 (blockWhenExhausted 默認為 true),進而導致正常服務也不能運行。
面試題
一般面試官會問:你會把超時參數設置成多大呢?我一般都會把最大等待時間,設置成接口可以忍受的最大延遲。
比如,一個正常服務響應時間 10ms 左右,達到 1 秒鐘就會感覺到卡頓,那么這個參數設置成 500~1000ms 都是可以的。
超時之后,會拋出 NoSuchElementException 異常,請求會快速失敗,不會影響其他業務線程,這種 Fail Fast 的思想,在互聯網應用非常廣泛。
帶有 evcit 字樣的參數,主要是處理對象逐出的。池化對象除了初始化和銷毀的時候比較昂貴,在運行時也會占用系統資源。
比如,連接池會占用多條連接,線程池會增加調度開銷等。業務在突發流量下,會申請到超出正常情況的對象資源,放在池子中。等這些對象不再被使用,我們就需要把它清理掉。
超出 minEvictableIdleTimeMillis 參數指定值的對象,就會被強制回收掉,這個值默認是 30 分鐘;softMinEvictableIdleTimeMillis 參數類似,但它只有在當前對象數量大于 minIdle 的時候才會執行移除,所以前者的動作要更暴力一些。
還有 4 個 test 參數:testOnCreate、testOnBorrow、testOnReturn、testWhileIdle,分別指定了在創建、獲取、歸還、空閑檢測的時候,是否對池化對象進行有效性檢測。
開啟這些檢測,能保證資源的有效性,但它會耗費性能,所以默認為 false。
生產環境上,建議只將 testWhileIdle 設置為 true,并通過調整空閑檢測時間間隔(timeBetweenEvictionRunsMillis),比如 1 分鐘,來保證資源的可用性,同時也保證效率。
使用連接池和不使用連接池,它們之間的性能差距到底有多大呢?
下面是一個簡單的 JMH 測試例子(見倉庫),進行一個簡單的 set 操作,為 redis 的 key 設置一個隨機值。
@Fork(2)
@State(Scope.Benchmark)
@Warmup(iterations = 5, time = 1)
@Measurement(iterations = 5, time = 1)
@BenchmarkMode(Mode.Throughput)
public class JedisPoolVSJedisBenchmark {
JedisPool pool = new JedisPool("localhost", 6379);@Benchmarkpublicvoid testPool() {
Jedis jedis = pool.getResource(); jedis.set("a", UUID.randomUUID().toString());
jedis.close();
}
@Benchmarkpublicvoid testJedis() {
Jedis jedis = new Jedis("localhost",6379);
jedis.set("a", UUID.randomUUID().toString());
jedis.close();
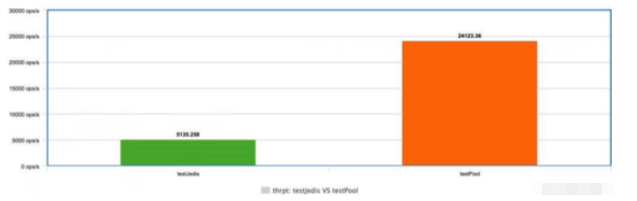
}//此處省略若干行}將測試結果使用 meta-chart 作圖,展示結果如下圖所示,可以看到使用了連接池的方式,它的吞吐量是未使用連接池方式的 5 倍!
HikariCP 源于日語“光る”,光的意思,寓意軟件工作速度和光速一樣快,它是 SpringBoot 中默認的數據庫連接池。
數據庫是我們工作中經常使用到的組件,針對數據庫設計的客戶端連接池是非常多的,它的設計原理與我們在本文開頭提到的基本一致,可以有效地減少數據庫連接創建、銷毀的資源消耗。
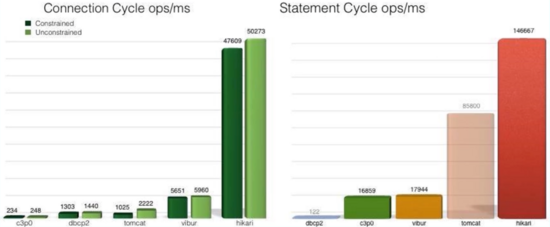
同是連接池,它們的性能也是有差別的,下圖是 HikariCP 官方的一張測試圖,可以看到它優異的性能,官方的 JMH 測試代碼見 Github。
一般面試題是這么問的:HikariCP 為什么快呢?
主要有三個方面:
它使用 FastList 替代 ArrayList,通過初始化的默認值,減少了越界檢查的操作
優化并精簡了字節碼,通過使用 Javassist,減少了動態代理的性能損耗,比如使用 invokestatic 指令代替 invokevirtual 指令
實現了無鎖的 ConcurrentBag,減少了并發場景下的鎖競爭
HikariCP 對性能的一些優化操作,是非常值得我們借鑒的,在之后的博客中,我們將詳細分析幾個優化場景。
數據庫連接池同樣面臨一個最大值(maximumPoolSize)和最小值(minimumIdle)的問題。這里同樣有一個非常高頻的面試題:你平常會把連接池設置成多大呢?
很多同學認為,連接池的大小設置得越大越好,有的同學甚至把這個值設置成 1000 以上,這是一種誤解。
根據經驗,數據庫連接,只需要 20~50 個就夠用了。具體的大小,要根據業務屬性進行調整,但大得離譜肯定是不合適的。
HikariCP 官方是不推薦設置 minimumIdle 這個值的,它將被默認設置成和 maximumPoolSize 一樣的大小。如果你的數據庫Server端連接資源空閑較大,不妨也可以去掉連接池的動態調整功能。
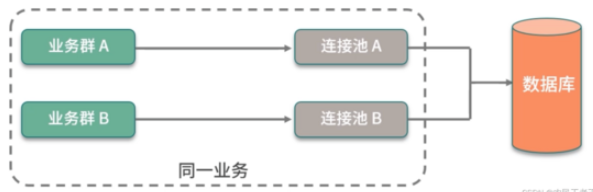
另外,根據數據庫查詢和事務類型,一個應用中是可以配置多個數據庫連接池的,這個優化技巧很少有人知道,在此簡要描述一下。
業務類型通常有兩種:一種需要快速的響應時間,把數據盡快返回給用戶;另外一種是可以在后臺慢慢執行,耗時比較長,對時效性要求不高。
如果這兩種業務類型,共用一個數據庫連接池,就容易發生資源爭搶,進而影響接口響應速度。
雖然微服務能夠解決這種情況,但大多數服務是沒有這種條件的,這時就可以對連接池進行拆分。
如圖,在同一個業務中,根據業務的屬性,我們分了兩個連接池,就是來處理這種情況的。
HikariCP 還提到了另外一個知識點,在 JDBC4 的協議中,通過 Connection.isValid() 就可以檢測連接的有效性。
這樣,我們就不用設置一大堆的 test 參數了,HikariCP 也沒有提供這樣的參數。
到了這里你可能會發現池(Pool)與緩存(Cache)有許多相似之處。
它們之間的一個共同點,就是將對象加工后,存儲在相對高速的區域。我習慣性將緩存看作是數據對象,而把池中的對象看作是執行對象。緩存中的數據有一個命中率問題,而池中的對象一般都是對等的。
考慮下面一個場景,jsp 提供了網頁的動態功能,它可以在執行后,編譯成 class 文件,加快執行速度;再或者,一些媒體平臺,會將熱門文章,定時轉化成靜態的 html 頁面,僅靠 nginx 的負載均衡即可應對高并發請求(動靜分離)。
這些時候,你很難說清楚,這是針對緩存的優化,還是針對對象進行了池化,它們在本質上只是保存了某個執行步驟的結果,使得下次訪問時不需要從頭再來。
我通常把這種技術叫作結果緩存池(Result Cache Pool),屬于多種優化手段的綜合。
下面我來簡單總結一下本文的內容重點:我們從 Java 中最通用的公用池化包 Commons Pool 2 說起,介紹了它的一些實現細節,并對一些重要參數的應用做了講解。
Jedis 就是在 Commons Pool 2 的基礎上封裝的,通過 JMH 測試,我們發現對象池化之后,有了接近 5 倍的性能提升。
接下來介紹了數據庫連接池中速度很快的 HikariCP ,它在池化技術之上,又通過編碼技巧進行了進一步的性能提升,HikariCP 是我重點研究的類庫之一,我也建議你加入自己的任務清單中。
總體來說,當你遇到下面的場景,就可以考慮使用池化來增加系統性能:
對象的創建或者銷毀,需要耗費較多的系統資源
對象的創建或者銷毀,耗時長,需要繁雜的操作和較長時間的等待
對象創建后,通過一些狀態重置,可被反復使用
將對象池化之后,只是開啟了第一步優化。要想達到最優性能,就不得不調整池的一些關鍵參數,合理的池大小加上合理的超時時間,就可以讓池發揮更大的價值。和緩存的命中率類似,對池的監控也是非常重要的。
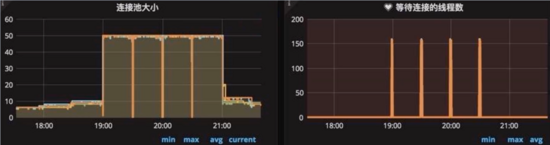
如下圖,可以看到數據庫連接池連接數長時間保持在高位不釋放,同時等待的線程數急劇增加,這就能幫我們快速定位到數據庫的事務問題。
平常的編碼中,有很多類似的場景。比如 Http 連接池,Okhttp 和 Httpclient 就都提供了連接池的概念,你可以類比著去分析一下,關注點也是在連接大小和超時時間上。
在底層的中間件,比如 RPC,也通常使用連接池技術加速資源獲取,比如 Dubbo 連接池、 Feign 切換成 httppclient 的實現等技術。
你會發現,在不同資源層面的池化設計也是類似的。比如線程池,通過隊列對任務進行了二層緩沖,提供了多樣的拒絕策略等,線程池我們將在后續的文章中進行介紹。
線程池的這些特性,你同樣可以借鑒到連接池技術中,用來緩解請求溢出,創建一些溢出策略。
現實情況中,我們也會這么做。那么具體怎么做?有哪些做法?這部分內容就留給大家思考了。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.12.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.ykq</groupId> <artifactId>qy151-springboot-vue</artifactId> <version>0.0.1-SNAPSHOT</version> <name>qy151-springboot-vue</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.5.2</version> </dependency> <dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.31</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.2</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency> <dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>swagger-bootstrap-ui</artifactId> <version>1.9.6</version> </dependency> <dependency> <groupId>com.spring4all</groupId> <artifactId>swagger-spring-boot-starter</artifactId> <version>1.9.1.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.2.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
到此,關于“SpringBoot HikariCP連接池怎么創建”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





