溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了GO并發模型的實現原理是什么的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇GO并發模型的實現原理是什么文章都會有所收獲,下面我們一起來看看吧。
請記住下面這句話:
DO NOT COMMUNICATE BY SHARING MEMORY; INSTEAD, SHARE MEMORY BY COMMUNICATING.
“不要以共享內存的方式來通信,相反,要通過通信來共享內存。”
普通的線程并發模型,就是像Java、C++、或者Python,他們線程間通信都是通過共享內存的方式來進行的。非常典型的方式就是,在訪問共享數據(例如數組、Map、或者某個結構體或對象)的時候,通過鎖來訪問,因此,在很多時候,衍生出一種方便操作的數據結構,叫做“線程安全的數據結構”。例如Java提供的包”java.util.concurrent”中的數據結構。Go中也實現了傳統的線程并發模型。
Go的CSP并發模型,是通過goroutine和channel來實現的。
goroutine 是Go語言中并發的執行單位。有點抽象,其實就是和傳統概念上的”線程“類似,可以理解為”線程“。
channel是Go語言中各個并發結構體(goroutine)之前的通信機制。 通俗的講,就是各個goroutine之間通信的”管道“,有點類似于Linux中的管道。
生成一個goroutine的方式非常的簡單:Go一下,就生成了。
go f();
通信機制channel也很方便,傳數據用channel <- data,取數據用<-channel。
在通信過程中,傳數據channel <- data和取數據<-channel必然會成對出現,因為這邊傳,那邊取,兩個goroutine之間才會實現通信。
而且不管傳還是取,必阻塞,直到另外的goroutine傳或者取為止。
示例如下:
package main
import "fmt"
func main() {
messages := make(chan string)
go func() { messages <- "ping" }()
msg := <-messages
fmt.Println(msg)
}注意 main()本身也是運行了一個goroutine。
messages:= make(chan int) 這樣就聲明了一個阻塞式的無緩沖的通道
chan 是關鍵字 代表我要創建一個通道
我們先從線程講起,無論語言層面何種并發模型,到了操作系統層面,一定是以線程的形態存在的。而操作系統根據資源訪問權限的不同,體系架構可分為用戶空間和內核空間;內核空間主要操作訪問CPU資源、I/O資源、內存資源等硬件資源,為上層應用程序提供最基本的基礎資源,用戶空間呢就是上層應用程序的固定活動空間,用戶空間不可以直接訪問資源,必須通過“系統調用”、“庫函數”或“Shell腳本”來調用內核空間提供的資源。
我們現在的計算機語言,可以狹義的認為是一種“軟件”,它們中所謂的“線程”,往往是用戶態的線程,和操作系統本身內核態的線程(簡稱KSE),還是有區別的。
線程模型的實現,可以分為以下幾種方式:
用戶級線程模型
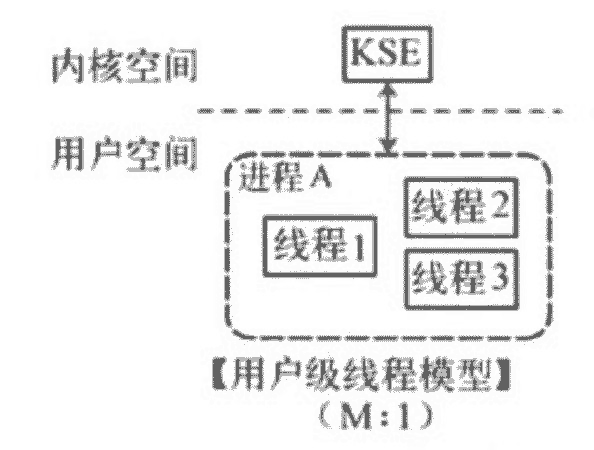
如圖所示,多個用戶態的線程對應著一個內核線程,程序線程的創建、終止、切換或者同步等線程工作必須自身來完成。它可以做快速的上下文切換。缺點是不能有效利用多核CPU。
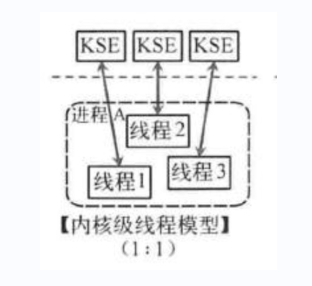
這種模型直接調用操作系統的內核線程,所有線程的創建、終止、切換、同步等操作,都由內核來完成。一個用戶態的線程對應一個系統線程,它可以利用多核機制,但上下文切換需要消耗額外的資源。C++就是這種。
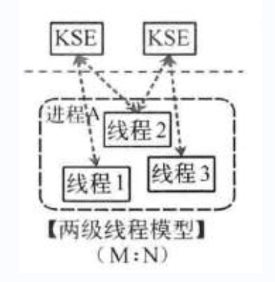
這種模型是介于用戶級線程模型和內核級線程模型之間的一種線程模型。這種模型的實現非常復雜,和內核級線程模型類似,一個進程中可以對應多個內核級線程,但是進程中的線程不和內核線程一一對應;這種線程模型會先創建多個內核級線程,然后用自身的用戶級線程去對應創建的多個內核級線程,自身的用戶級線程需要本身程序去調度,內核級的線程交給操作系統內核去調度。
M個用戶線程對應N個系統線程,缺點增加了調度器的實現難度。
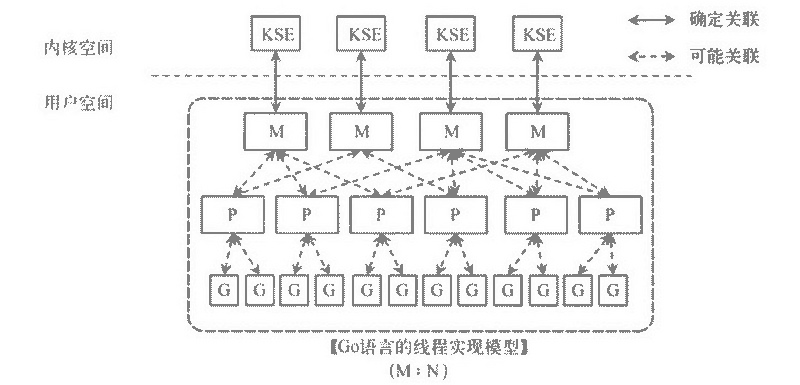
Go語言的線程模型就是一種特殊的兩級線程模型(GPM調度模型)。
M指的是Machine,一個M直接關聯了一個內核線程。由操作系統管理。
P指的是”processor”,代表了M所需的上下文環境,也是處理用戶級代碼邏輯的處理器。它負責銜接M和G的調度上下文,將等待執行的G與M對接。
G指的是Goroutine,其實本質上也是一種輕量級的線程。包括了調用棧,重要的調度信息,例如channel等。
P的數量由環境變量中的GOMAXPROCS決定,通常來說它是和核心數對應,例如在4Core的服務器上回啟動4個線程。G會有很多個,每個P會將Goroutine從一個就緒的隊列中做Pop操作,為了減小鎖的競爭,通常情況下每個P會負責一個隊列。
三者關系如下圖所示:
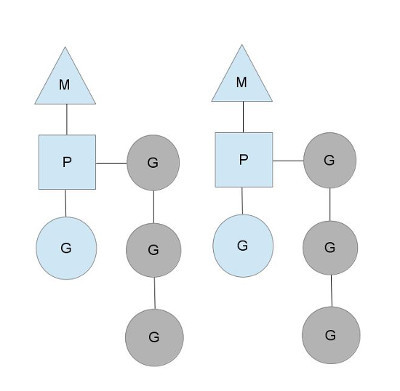
以上這個圖講的是兩個線程(內核線程)的情況。一個M會對應一個內核線程,一個M也會連接一個上下文P,一個上下文P相當于一個“處理器”,一個上下文連接一個或者多個Goroutine。為了運行goroutine,線程必須保存上下文。
上下文P(Processor)的數量在啟動時設置為GOMAXPROCS環境變量的值或通過運行時函數GOMAXPROCS()。通常情況下,在程序執行期間不會更改。上下文數量固定意味著只有固定數量的線程在任何時候運行Go代碼。我們可以使用它來調整Go進程到個人計算機的調用,例如4核PC在4個線程上運行Go代碼。
圖中P正在執行的Goroutine為藍色的;處于待執行狀態的Goroutine為灰色的,灰色的Goroutine形成了一個隊列runqueues。
Go語言里,啟動一個goroutine很容易:go function 就行,所以每有一個go語句被執行,runqueue隊列就在其末尾加入一個goroutine,一旦上下文運行goroutine直到調度點,它會從其runqueue中彈出goroutine,設置堆棧和指令指針并開始運行goroutine。
拋棄P(Processor)
你可能會想,為什么一定需要一個上下文,我們能不能直接除去上下文,讓Goroutine的runqueues掛到M上呢?答案是不行,需要上下文的目的,是讓我們可以直接放開其他線程,當遇到內核線程阻塞的時候。
一個很簡單的例子就是系統調用sysall,一個線程肯定不能同時執行代碼和系統調用被阻塞,這個時候,此線程M需要放棄當前的上下文環境P,以便可以讓其他的Goroutine被調度執行。
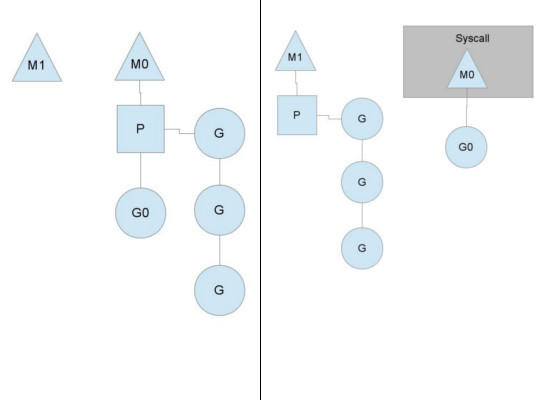
如上圖左圖所示,M0中的G0執行了syscall,然后就創建了一個M1(也有可能來自線程緩存),(轉向右圖)然后M0丟棄了P,等待syscall的返回值,M1接受了P,將·繼續執行Goroutine隊列中的其他Goroutine。
當系統調用syscall結束后,M0會“偷”一個上下文,如果不成功,M0就把它的Gouroutine G0放到一個全局的runqueue中,將自己置于線程緩存中并進入休眠狀態。全局runqueue是各個P在運行完自己的本地的Goroutine runqueue后用來拉取新goroutine的地方。P也會周期性的檢查這個全局runqueue上的goroutine,否則,全局runqueue上的goroutines可能得不到執行而餓死。
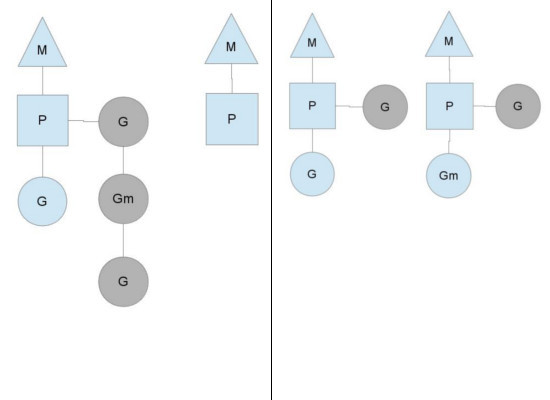
均衡的分配工作
按照以上的說法,上下文P會定期的檢查全局的goroutine 隊列中的goroutine,以便自己在消費掉自身Goroutine隊列的時候有事可做。假如全局goroutine隊列中的goroutine也沒了呢?就從其他運行的中的P的runqueue里偷。
每個P中的Goroutine不同導致他們運行的效率和時間也不同,在一個有很多P和M的環境中,不能讓一個P跑完自身的Goroutine就沒事可做了,因為或許其他的P有很長的goroutine隊列要跑,得需要均衡。
該如何解決呢?
Go的做法倒也直接,從其他P中偷一半!
1、開銷小
POSIX的thread API雖然能夠提供豐富的API,例如配置自己的CPU親和性,申請資源等等,線程在得到了很多與進程相同的控制權的同時,開銷也非常的大,在Goroutine中則不需這些額外的開銷,所以一個Golang的程序中可以支持10w級別的Goroutine。
每個 goroutine (協程) 默認占用內存遠比 Java 、C 的線程少(goroutine:2KB ,線程:8MB)
2、調度性能好
在Golang的程序中,操作系統級別的線程調度,通常不會做出合適的調度決策。例如在GC時,內存必須要達到一個一致的狀態。在Goroutine機制里,Golang可以控制Goroutine的調度,從而在一個合適的時間進行GC。
在應用層模擬的線程,它避免了上下文切換的額外耗費,兼顧了多線程的優點。簡化了高并發程序的復雜度。
協程調度機制無法實現公平調度。
關于“GO并發模型的實現原理是什么”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“GO并發模型的實現原理是什么”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





