溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Go分布式鏈路追蹤實現原理是什么”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Go分布式鏈路追蹤實現原理是什么”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
在分布式架構下,當用戶從瀏覽器客戶端發起一個請求時,后端處理邏輯往往貫穿多個分布式服務,這時會浮現很多問題,比如:
請求整體耗時較長,具體慢在哪個服務?
請求過程中出錯了,具體是哪個服務報錯?
某個服務的請求量如何,接口成功率如何?
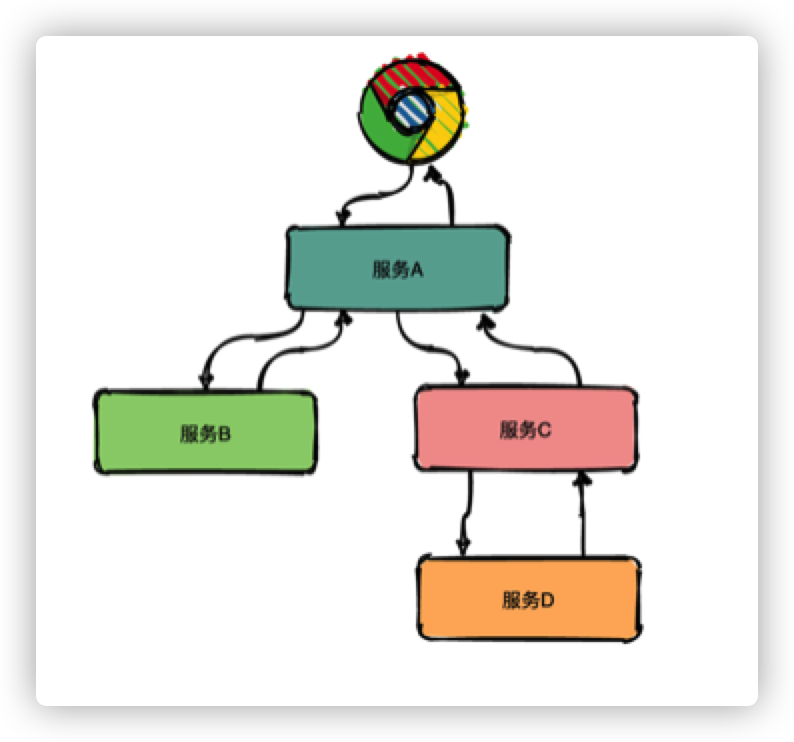
回答這些問題變得不是那么簡單,我們不僅僅需要知道某一個服務的接口處理統計數據,還需要了解兩個服務之間的接口調用依賴關系,只有建立起整個請求在多個服務間的時空順序,才能更好的幫助我們理解和定位問題,而這,正是分布式鏈路追蹤系統可以解決的。
分布式鏈路追蹤技術的核心思想:在用戶一次分布式請求服務的調?過程中,將請求在所有子系統間的調用過程和時空關系追蹤記錄下來,還原成調用鏈路集中展示,信息包括各個服務節點上的耗時、請求具體到達哪臺機器上、每個服務節點的請求狀態等等。
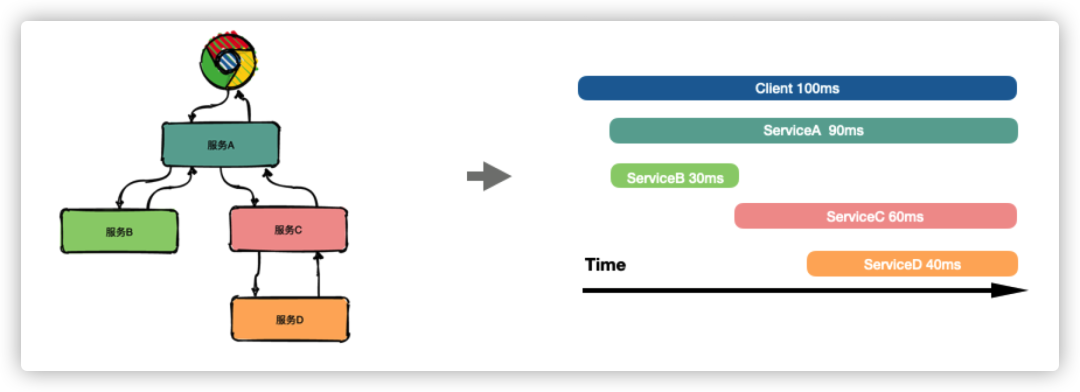
如上圖所示,通過分布式鏈路追蹤構建出完整的請求鏈路后,可以很直觀地看到請求耗時主要耗費在哪個服務環節,幫助我們更快速聚焦問題。
同時,還可以對采集的鏈路數據做進一步的分析,從而可以建立整個系統各服務間的依賴關系、以及流量情況,幫助我們更好地排查系統的循環依賴、熱點服務等問題。
在分布式鏈路追蹤系統中,最核心的概念,便是鏈路追蹤的數據模型定義,主要包括 Trace 和 Span。
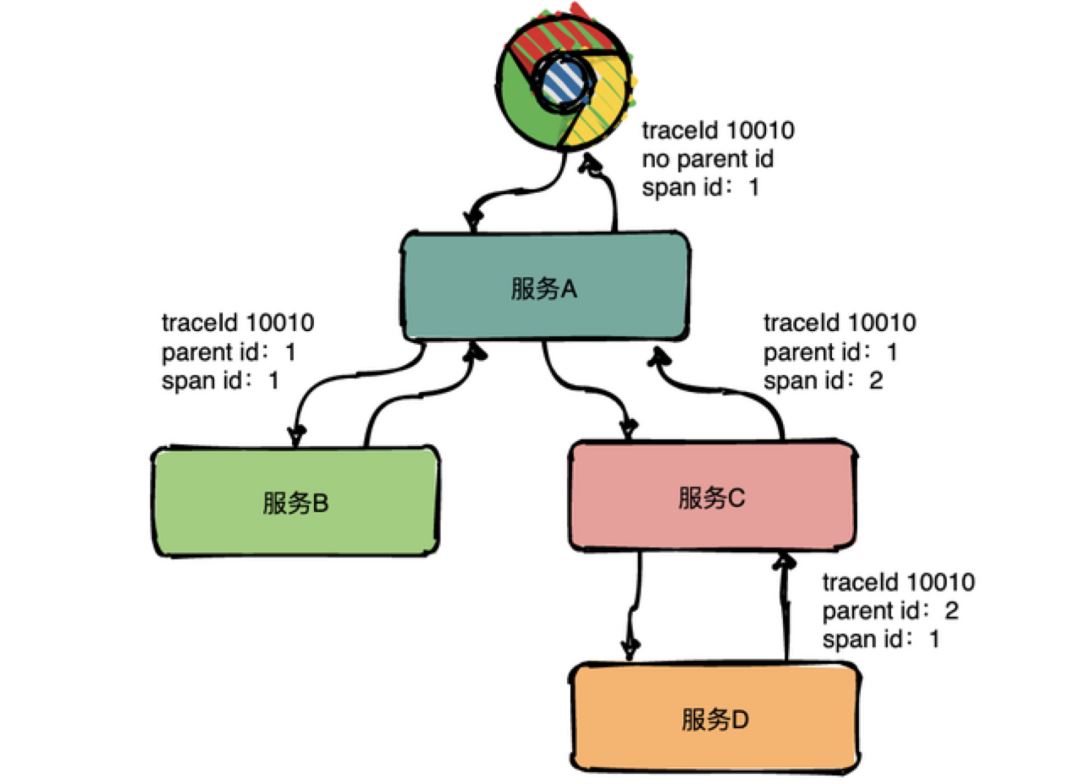
其中,Trace 是一個邏輯概念,表示一次(分布式)請求經過的所有局部操作(Span)構成的一條完整的有向無環圖,其中所有的 Span 的 TraceId 相同。
Span 則是真實的數據實體模型,表示一次(分布式)請求過程的一個步驟或操作,代表系統中一個邏輯運行單元,Span 之間通過嵌套或者順序排列建立因果關系。Span 數據在采集端生成,之后上報到服務端,做進一步的處理。其包含如下關鍵屬性:
Name:操作名稱,如一個 RPC 方法的名稱,一個函數名
StartTime/EndTime:起始時間和結束時間,操作的生命周期
ParentSpanId:父級 Span 的 ID
Attributes:屬性,一組 <K,V> 鍵值對構成的集合
Event:操作期間發生的事件
SpanContext:Span 上下文內容,通常用于在 Span 間傳播,其核心字段包括 TraceId、SpanId
分布式鏈路追蹤系統的核心任務是:圍繞 Span 的生成、傳播、采集、處理、存儲、可視化、分析,構建分布式鏈路追蹤系統。其一般的架構如下如所示:
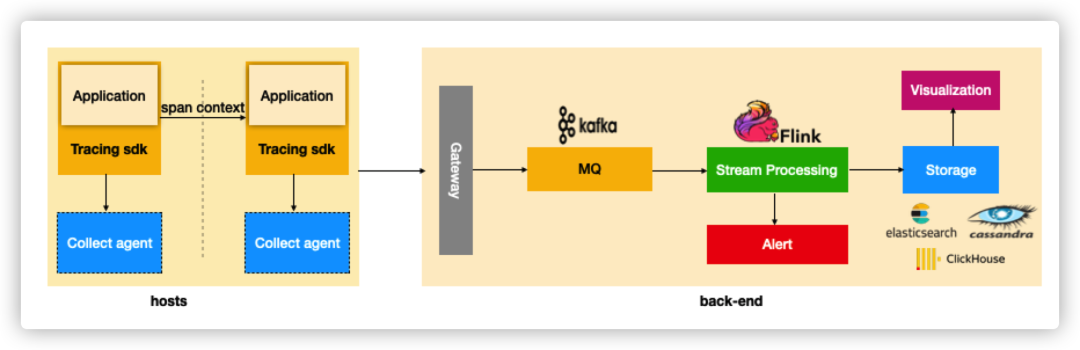
我們看到,在應用端需要通過侵入或者非侵入的方式,注入 Tracing Sdk,以跟蹤、生成、傳播和上報請求調用鏈路數據;
Collect agent 一般是在靠近應用側的一個邊緣計算層,主要用于提高 Tracing Sdk 的寫性能,和減少 back-end 的計算壓力;
采集的鏈路跟蹤數據上報到后端時,首先經過 Gateway 做一個鑒權,之后進入 kafka 這樣的 MQ 進行消息的緩沖存儲;
在數據寫入存儲層之前,我們可能需要對消息隊列中的數據做一些清洗和分析的操作,清洗是為了規范和適配不同的數據源上報的數據,分析通常是為了支持更高級的業務功能,比如流量統計、錯誤分析等,這部分通常采用flink這類的流處理框架來完成;
存儲層會是服務端設計選型的一個重點,要考慮數據量級和查詢場景的特點來設計選型,通常的選擇包括使用 Elasticsearch、Cassandra、或 Clickhouse 這類開源產品;
流處理分析后的結果,一方面作為存儲持久化下來,另一方面也會進入告警系統,以主動發現問題來通知用戶,如錯誤率超過指定閾值發出告警通知這樣的需求等。
剛才講的,是一個通用的架構,我們并沒有涉及每個模塊的細節,尤其是服務端,每個模塊細講起來都要很花些功夫,受篇幅所限,我們把注意力集中到靠近應用側的 Tracing Sdk,重點看看在應用側具體是如何實現鏈路數據的跟蹤和采集的。
剛才我們提到 Tracing Sdk,其實這只是一個概念,具體到實現,選擇可能會非常多,這其中的原因,主要是因為:
不同的編程語言的應用,可能采用不同技術原理來實現對調用鏈的跟蹤
不同的鏈路追蹤后端,可能采用不同的數據傳輸協議
當前,流行的鏈路追蹤后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供應用集成的 sdk,導致我們在切換后端時應用側可能也需要做較大的調整。
社區也出現過不同的協議,試圖解決采集側的這種亂象,比如 OpenTracing、OpenCensus 協議,這兩個協議也分別有一些大廠跟進支持,但最近幾年,這兩者已經走向了融合統一,產生了一個新的標準 OpenTelemetry,這兩年發展迅猛,已經逐漸成為行業標準。
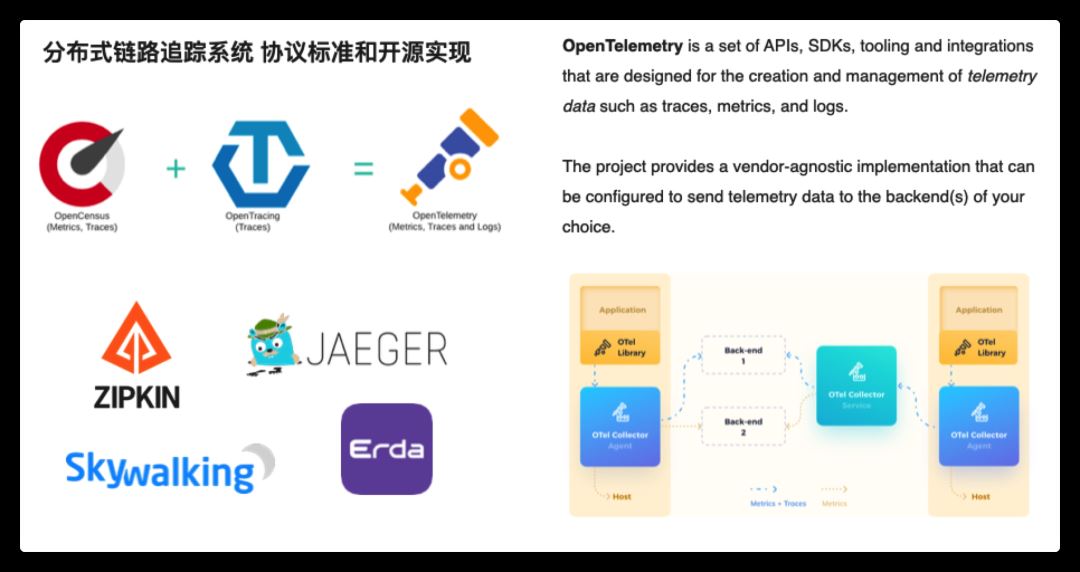
OpenTelemetry 定義了數據采集的標準 api,并提供了一組針對多語言的開箱即用的 sdk 實現工具,這樣,應用只需要與 OpenTelemetry 核心 api 包強耦合,不需要與特定的實現強耦合。
應用側圍繞 Span,有三個核心任務要完成:
生成 Span:操作開始構建 Span 并填充 StartTime,操作完成時填充 EndTime 信息,期間可追加 Attributes、Event 等
傳播 Span:進程內通過 context.Context、進程間通過請求的 header 作為 SpanContext 的載體,傳播的核心信息是 TraceId 和 ParentSpanId
上報 Span:生成的 Span 通過 tracing exporter 發送給 collect agent / back-end server
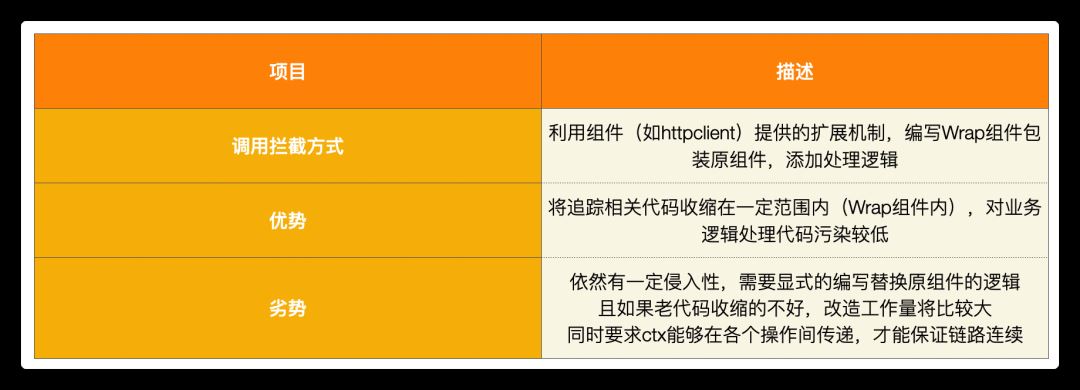
要實現 Span 的生成和傳播,要求我們能夠攔截應用的關鍵操作(函數)過程,并添加 Span 相關的邏輯。實現這個目的會有很多方法,不過,在羅列這些方法之前,我們先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。
OpenTelemetry 的 go sdk 實現調用鏈攔截的基本思路是:基于 AOP 的思想,采用裝飾器模式,通過包裝替換目標包(如 net/http)的核心接口或組件,實現在核心調用過程前后添加 Span 相關邏輯。當然,這樣的做法是有一定的侵入性的,需要手動替換使用原接口實現的代碼調用改為包裝接口實現。
我們以一個 http server 的例子來說明,在 go 語言中,具體是如何做的:
假設有兩個服務 serverA 和 serverB,其中 serverA 的接口收到請求后,內部會通過 httpclient 進一步發起到 serverB 的請求,那么 serverA 的核心代碼可能如下圖所示:
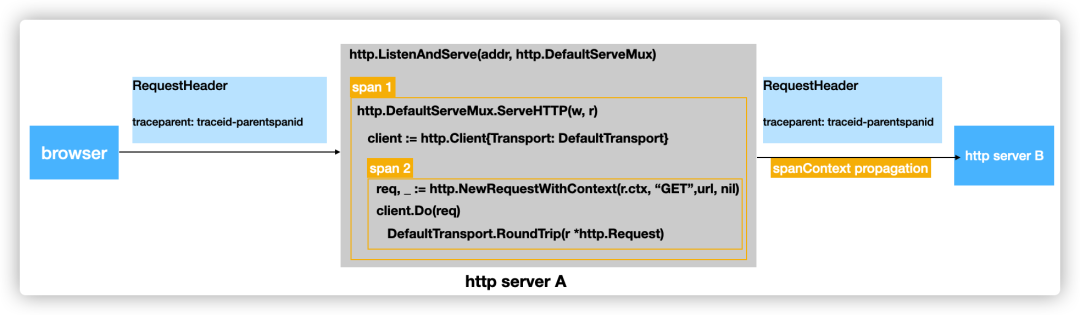
以 serverA 節點為例,在 serverA 節點應該產生至少兩個 Span:
Span1,記錄 httpServer 收到一個請求后內部整體處理過程的一個耗時情況
Span2,記錄 httpServer 處理請求過程中,發起的另一個到 serverB 的 http 請求的耗時情況
并且 Span1 應該是 Span2 的 ParentSpan
我們可以借助 OpenTelemetry 提供的 sdk 來實現 Span 的生成、傳播和上報,上報的邏輯受篇幅所限我們不再詳述,重點來看看如何生成這兩個 Span,并使這兩個 Span 之間建立關聯,即 Span 的生成和傳播 。
對于 httpserver 來講,我們知道其核心就是 http.Handler 這個接口。因此,可以通過實現一個針對 http.Handler 接口的攔截器,來負責 Span 的生成和傳播。
package http
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 裝飾器,需要如下調整 http.ListenAndServe 方法:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...)
http.ListenAndServe(":8090", wrappedHttpHandler)
如圖所示,wrppedHttpHandler 中將主要實現如下邏輯(精簡考慮,此處部分為偽代碼):
① ctx := tracer.Extract(r.ctx, r.Header):從請求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,進而構建 SpanContext 對象,并最終存儲在 ctx 中;
② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟蹤當前請求處理過程的 Span(即前文所述的Span1),并記錄開始時間,這時會從 ctx 中讀取 SpanContext,將 SpanContext.TraceId 作為當前 Span 的TraceId,將 SpanContext.SpanId 作為當前 Span的ParentSpanId,然后將自己作為新的 SpanContext 寫入返回的 ctx 中;
③ r.WithContext(ctx):將新生成的 SpanContext 添加到請求 r 的 context 中,以便被攔截的 handler 內部在處理過程中,可以從 r.ctx 中拿到 Span1 的 SpanId 作為其 ParentSpanId 屬性,從而建立 Span 之間的父子關系;
④ span.End():當 innerHttpHandler.ServeHTTP(w,r) 執行完成后,就需要對 Span1 記錄一下處理完成的時間,然后將它發送給 exporter 上報到服務端。
我們再接著看 serverA 內部去請求 serverB 時的 httpclient 請求是如何生成 Span 的(即前文說的 Span2)。我們知道,httpclient 發送請求的關鍵操作是 http.RoundTriper 接口:
package http
type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}OpenTelemetry 提供了基于這個接口的一個攔截器實現,我們需要使用這個實現包裝一下 httpclient 原來使用的 RoundTripper 實現,代碼調整如下:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
wrappedTransport := otelhttp.NewTransport(http.DefaultTransport)
client := http.Client{Transport: wrappedTransport}
如圖所示,wrappedTransport 將主要完成以下任務(精簡考慮,此處部分為偽代碼):
① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :這里我們將上一步 http.Handler 的請求的 ctx,傳遞到 httpclient 要發出的 request 中,這樣在之后我們就可以從 request.Context() 中提取出 Span1 的信息,來建立 Span 之間的關聯;
② ctx, span := tracer.Start(r.Context(), url):執行 client.Do() 之后,將首先進入 WrappedTransport.RoundTrip() 方法,這里生成新的 Span(Span2),開始記錄 httpclient 請求的耗時情況,與前文一樣,Start 方法內部會從 r.Context() 中提取出 Span1 的 SpanContext,并將其 SpanId 作為當前 Span(Span2)的 ParentSpanId,從而建立了 Span 之間的嵌套關系,同時返回的 ctx 中保存的 SpanContext 將是新生成的 Span(Span2)的信息;
③ tracer.Inject(ctx, r.Header):這一步的目的是將當前 SpanContext 中的 TraceId 和 SpanId 等信息寫入到 r.Header 中,以便能夠隨著 http 請求發送到 serverB,之后在 serverB 中與當前 Span 建立關聯;
④ span.End():等待 httpclient 請求發送到 serverB 并收到響應以后,標記當前 Span 跟蹤結束,設置 EndTime 并提交給 exporter 以上報到服務端。
我們比較詳細的介紹了使用 OpenTelemetry 庫,是如何實現鏈路的關鍵信息(TraceId、SpanId)是如何在進程間和進程內傳播的,我們對這種跟蹤實現方式做個小的總結:
如上分析所展示的,使用這種方式的話,對代碼還是有一定的侵入性,并且對代碼有另一個要求,就是保持 context.Context 對象在各操作間的傳遞,比如,剛才我們在 serverA 中創建 httpclient 請求時,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外開啟 goroutine 的異步場景也需要注意 ctx 的傳遞。

我們剛才詳細展示了基于常規的一種具有一定侵入性的實現,其侵入性主要表現在:我們需要顯式的手動添加代碼使用具有跟蹤功能的組件包裝原代碼,這進一步會導致應用代碼需要顯式的引用具體版本的 OpenTelemetry instrumentation 包,這不利于可觀測代碼的獨立維護和升級。
那我們有沒有可以實現非侵入跟蹤調用鏈的方案可選?
所謂無侵入,其實也只是集成的方式不同,集成的目標其實是差不多的,最終都是要通過某種方式,實現對關鍵調用函數的攔截,并加入特殊邏輯,無侵入重點在于代碼無需修改或極少修改。

上圖列出了現在可能的一些無侵入集成的實現思路,與 .net、java 這類有 IL 語言的編程語言不同,go 直接編譯為機器碼,導致無侵入的方案實現起來相對比較麻煩,具體有如下幾種思路:
編譯階段注入:可以擴展編譯器,修改編譯過程中的ast,插入跟蹤代碼,需要適配不同編譯器版本。啟動階段注入:修改編譯后的機器碼,插入跟蹤代碼,需要適配不同 CPU 架構。如 monkey, gohook。運行階段注入:通過內核提供的 eBPF 能力,監聽程序關鍵函數執行,插入跟蹤代碼,前景光明!如,tcpdump,bpftrace。
Erda 項目的核心代碼主要是基于 golang 編寫的,我們基于前文所述的 OpenTelemetry sdk,采用基于修改機器碼的的方式,實現了一種無侵入的鏈路追蹤方式。
前文提到,使用 OpenTelemetry sdk 需要代碼做一些調整,我們看看這些調整如何以非侵入的方式自動的完成:

我們以 httpclient 為例,做簡要的解釋。
gohook 框架提供的 hook 接口的簽名如下:
// target 要hook的目標函數
// replacement 要替換為的函數
// trampoline 將源函數入口拷貝到的位置,可用于從replcement跳轉回原target
func Hook(target, replacement, trampoline interface{}) error對于 http.Client,我們可以選擇 hook DefaultTransport.RoundTrip() 方法,當該方法執行時,我們通過 otelhttp.NewTransport() 包裝起原 DefaultTransport 對象,但需要注意的是,我們不能將 DefaultTransport 直接作為 otelhttp.NewTransport() 的參數,因為其 RoundTrip() 方法已經被我們替換了,而其原來真正的方法被寫到了 trampoline 中,所以這里我們需要一個中間層,來連接 DefaultTransport 與其原來的 RoundTrip 方法。具體代碼如下:
//go:linkname RoundTrip net/http.(*Transport).RoundTrip
//go:noinline
// RoundTrip .
func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error)
//go:noinline
func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) {
return RoundTrip(t, req)
}
type wrappedTransport struct {
t *http.Transport
}
//go:noinline
func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) {
return originalRoundTrip(t.t, req)
}
//go:noinline
func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) {
req = contextWithSpan(req)
return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req)
}
//go:noinline
func contextWithSpan(req *http.Request) *http.Request {
ctx := req.Context()
if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() {
pctx := injectcontext.GetContext()
if pctx != nil {
if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() {
ctx = trace.ContextWithSpan(ctx, span)
req = req.WithContext(ctx)
}
}
}
return req
}
func init() {
gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip)
}我們使用 init() 函數實現了自動添加 hook,因此用戶程序里只需要在 main 文件中 import 該包,即可實現無侵入的集成。
值得一提的是 req = contextWithSpan(req) 函數,內部會依次嘗試從 req.Context() 和 我們保存的 goroutineContext map 中檢查是否包含 SpanContext,并將其賦值給 req,這樣便可以解除了必須使用 http.NewRequestWithContext(...) 寫法的要求。
讀到這里,這篇“Go分布式鏈路追蹤實現原理是什么”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





