溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Flink流處理引擎之數據怎么抽取”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Flink流處理引擎之數據怎么抽取”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
CDC (Change Data Capture) ,在廣義的概念上,只要能捕獲數據變更的技術,都可以稱為 CDC 。但通常我們說的CDC 技術主要面向數據庫(包括常見的mysql,Oracle, MongoDB等)的變更,是一種用于捕獲數據庫中數據變更的技術。
常見的主要包括Flink CDC,DataX,Canal,Sqoop,Kettle,Oracle Goldengate,Debezium等。
DataX,Sqoop和kettle的CDC實現技術主要是基于查詢的方式實現的,通過離線調度查詢作業,實現批處理請求。這種作業方式無法保證數據的一致性,實時性也較差。
Flink CDC,Canal,Debezium和Oracle Goldengate是基于日志的CDC技術。這種技術,利用流處理的方式,實時處理日志數據,保證了數據的一致性,為其他服務提供了實時數據。
2020年 Flink cdc 首次在 Flink forward 大會上官宣, 由 Jark Wu & Qingsheng Ren 兩位大佬提出。
Flink CDC connector 可以捕獲在一個或多個表中發生的所有變更。該模式通常有一個前記錄和一個后記錄。Flink CDC connector 可以直接在Flink中以非約束模式(流)使用,而不需要使用類似 kafka 之類的中間件中轉數據。
PS:
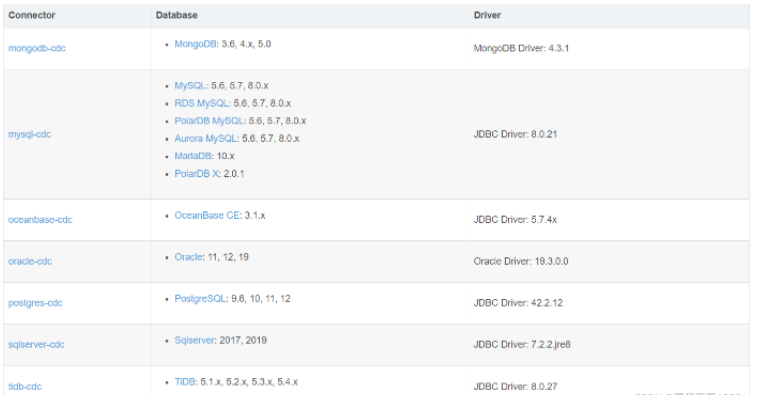
Flink CDC 2.2才新增OceanBase,PolarDB-X,SqlServer,TiDB 四種數據源接入,均支持全量和增量一體化同步。
截止到目前FlinkCDC已經支持12+數據源。
<!-- flink table支持 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 阿里實現的flink mysql CDC -->
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.80</version>
</dependency>
<!-- jackson報錯解決 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-parameter-names</artifactId>
<version>${jackson.version}</version>
</dependency>package spendreport.cdc;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import java.util.List;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
;
/**
* @author zhengwen
**/
public class TestMySqlFlinkCDC {
public static void main(String[] args) throws Exception {
//1.創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.Flink-CDC 將讀取 binlog 的位置信息以狀態的方式保存在 CK,如果想要做到斷點續傳, 需要從 Checkpoint 或者 Savepoint 啟動程序
//2.1 開啟 Checkpoint,每隔 5 秒鐘做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性語義
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 設置任務關閉的時候保留最后一次 CK 數據
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定從 CK 自動重啟策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("127.0.0.1")
.serverTimeZone("GMT+8") //時區報錯增加這個設置
.port(3306)
.username("root")
.password("123456")
.databaseList("wz")
.tableList("wz.user_info") //注意表一定要寫庫名.表名這種,多個,隔開
.startupOptions(StartupOptions.initial())
//自定義轉json格式化
.deserializer(new MyJsonDebeziumDeserializationSchema())
//自帶string格式序列化
//.deserializer(new StringDebeziumDeserializationSchema())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//TODO 可以keyBy,比如根據table或type,然后開窗處理
//3.打印數據
streamSource.print();
//streamSource.addSink(); 輸出
//4.執行任務
env.execute("flinkTableCDC");
}
private static class MyJsonDebeziumDeserializationSchema implements
com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema<String> {
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector)
throws Exception {
Struct value = (Struct) sourceRecord.value();
Struct source = value.getStruct("source");
//獲取數據庫名稱
String db = source.getString("db");
String table = source.getString("table");
//獲取數據類型
String type = Envelope.operationFor(sourceRecord).toString().toLowerCase();
if (type.equals("create")) {
type = "insert";
}
JSONObject jsonObject = new JSONObject();
jsonObject.put("database", db);
jsonObject.put("table", table);
jsonObject.put("type", type);
//獲取數據data
Struct after = value.getStruct("after");
JSONObject dataJson = new JSONObject();
List<Field> fields = after.schema().fields();
for (Field field : fields) {
String field_name = field.name();
Object fieldValue = after.get(field);
dataJson.put(field_name, fieldValue);
}
jsonObject.put("data", dataJson);
collector.collect(JSONObject.toJSONString(jsonObject));
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
}運行效果
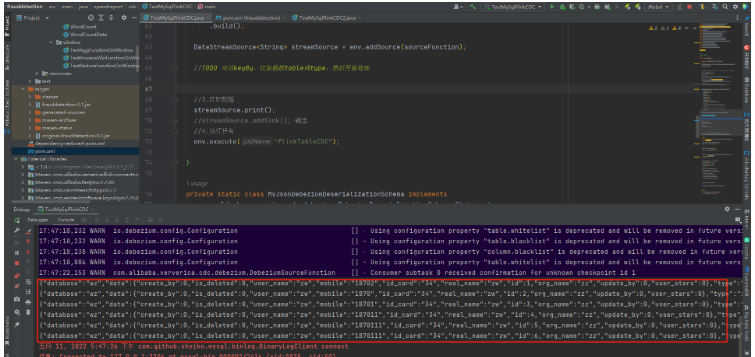
PS:
操作數據庫的增刪改就會立馬觸發
這里是自定義的序列化轉json格式字符串,自帶的字符串序列化也是可以的(可以自己試試打印的內容)
package spendreport.cdc;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @author zhengwen
**/
public class TestMySqlFlinkCDC2 {
public static void main(String[] args) throws Exception {
//1.創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.創建 Flink-MySQL-CDC 的 Source
String connectorName = "mysql-cdc";
String dbHostName = "127.0.0.1";
String dbPort = "3306";
String dbUsername = "root";
String dbPassword = "123456";
String dbDatabaseName = "wz";
String dbTableName = "user_info";
String tableSql = "CREATE TABLE t_user_info ("
+ "id int,mobile varchar(20),"
+ "user_name varchar(30),"
+ "real_name varchar(60),"
+ "id_card varchar(20),"
+ "org_name varchar(100),"
+ "user_stars int,"
+ "create_by int,"
// + "create_time datetime,"
+ "update_by int,"
// + "update_time datetime,"
+ "is_deleted int) "
+ " WITH ("
+ " 'connector' = '" + connectorName + "',"
+ " 'hostname' = '" + dbHostName + "',"
+ " 'port' = '" + dbPort + "',"
+ " 'username' = '" + dbUsername + "',"
+ " 'password' = '" + dbPassword + "',"
+ " 'database-name' = '" + dbDatabaseName + "',"
+ " 'table-name' = '" + dbTableName + "'"
+ ")";
tableEnv.executeSql(tableSql);
tableEnv.executeSql("select * from t_user_info").print();
env.execute();
}
}運行效果:

既然是基于日志,那么數據庫的配置文件肯定要開啟日志功能,這里mysql需要開啟內容
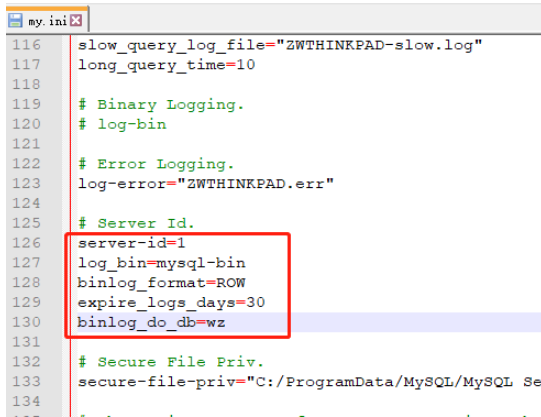
server-id=1
log_bin=mysql-bin
binlog_format=ROW #目前還只能支持行
expire_logs_days=30
binlog_do_db=wz #這里binlog的庫如果有多個就再寫一行,千萬不要寫成用,隔開
實時性確實高,比那些自動任務定時取體驗號百倍
流示的確實絲滑
讀到這里,這篇“Flink流處理引擎之數據怎么抽取”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





