溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下flink為什么會成為最火計算引擎,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
我是在兩年前隨公司參加一個會議上知道的Flink,那是一家做大數據安全的公司,利用大數據分析安全威脅預警。當時會議上他們展示了三種流計算技術,大家應該都知道,也就是最常見的Storm、SparkStreaming與Flink。Storm的標記是‘過去’,SparkStreaming的標記是‘現在’,而Flink上的標記是‘未來’。當時我們的業務沒有實時處理,所以對這方面不了解。但是我就記住了‘未來’這兩個字。
后來業務中增加了實時計算相關的處理,那么開始之前就對實時計算的三種技術做了一些調研。Storm,SparkStreaming,FLink。其實本身也沒做什么相關的調研,只是基于當時的那場會議,直接排除了Storm。僅在SparkStreaming與Flink之間做了選型。而最終選擇了FLink。
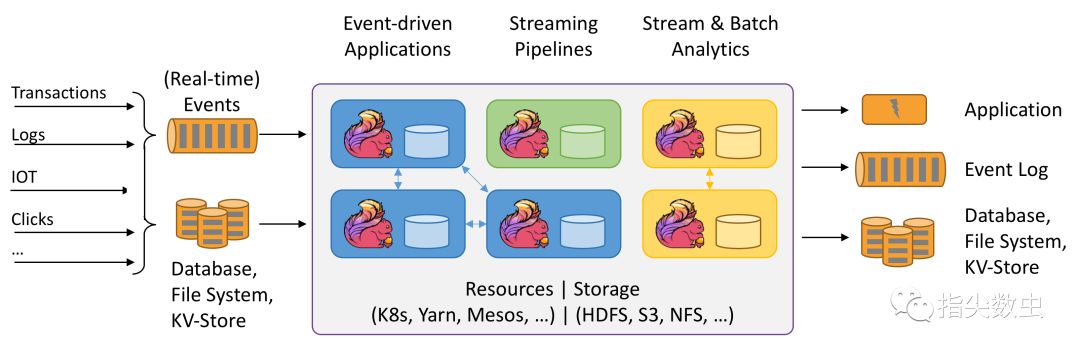
高吞吐,低延遲,高性能
針對于這三個特性,Flink在社區內屬于唯一,也就是唯一一個能夠同時支持三種特性的實時處理框架。而其他的SparkStreaming,Storm等均無法同時支持三個特性,SparkStreaming是micro batch處理的特性,所以本身無法做到低延遲的保障,僅能做到高性能,高吞吐。Storm只能支持高性能與低延遲。
所以在實際業務使用中,同時保證三個特性的框架對于選型來說是至關重要的。
支持event time,process time,igest time
FLink支持事件時間,也就是數據本身的時間,事件時間對于計算、處理等至關重要,能夠防止對于出現亂序到達而造成的數據計算錯誤。保持數據原本的時序性,避免由于網絡、硬件等造成的計算結果的誤差。
而其他系統采用的處理時間,系統時間等可能就會由于網絡、硬件、甚至是系統啟動問題都會造成數據的計算錯誤。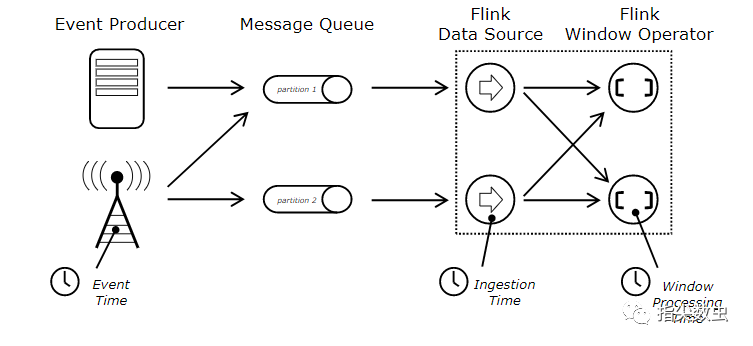
有狀態計算
Flink中包含狀態管理,能夠通過數據計算的中間結果狀態存儲到內存或文件中,等下一批事件到來的時候即可獲取到狀態信息接續統計結果。這樣由于無需再次重新計算將會極大的提升系統的性能。
靈活的窗口機制
在實時處理的場景中,數據是連續不斷的。實時處理的場景中同樣包含對于一段范圍數據的處理,例如一分鐘,100條等場景。那么Flink中提供窗口機制實現靈活的數據切割辦法,對100條數據或一分鐘等計算提供簡單的實現方案。
Flink提供的窗口如上有數據驅動,時間驅動。窗口可以劃分為滾動窗口,翻滾窗口,會話窗口等。窗口自由組合實現不同的數據場景。
高容錯性
Flink提供了容錯機制,對于數據處理過程中由于硬件、網絡等問題造成的集群異常均可以通過容錯機制進行恢復。容錯性保證了數據的exactly-once
其實當時選擇Flink是非常的不合理的,當時主流的實時處理框架還是SparkStreaming,Flink在當時占比還是很低,相關的書籍,文檔完全不足。對于前方有多少的坑多大的坑完全不了解。最終磕磕碰碰的把相關的需求實現。
調研本身對于技術的是市場占比還是很需要關注的,畢竟是小公司很難有阿里云那種能夠專門的抽取一個小團隊對于新技術進行跟進,甚至是拉分支進行開發。調研技術本身可能對于該技術前方有多少坑了解清楚更重要。對于公司,業務來講沒有完美的技術,只有最合適的技術。而對于創業公司來講,能夠實現快速迭代,快速學習,快速掌握,有人給趟平了坑更加重要。
以上是“flink為什么會成為最火計算引擎”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





