溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Java實現數據結構中的并查集”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Java實現數據結構中的并查集”吧!
對于一種數據結構,肯定是有自己的應用場景和特性,那么并查集是處理什么問題的呢?
并查集是一種樹型的數據結構,用于處理一些不相交集合(disjoint sets)的合并及查詢問題,常常在使用中以森林來表示。在一些有N個元素的集合應用問題中,我們通常是在開始時讓每個元素構成一個單元素的集合,然后按一定順序將屬于同一組的元素所在的集合合并,其間要反復查找一個元素在哪個集合中。其特點是看似并不復雜,但數據量極大,若用正常的數據結構來描述的話,往往在空間上過大,計算機無法承受;即使在空間上勉強通過,運行的時間復雜度也極高,根本就不可能在比賽規定的運行時間(1~3秒)內計算出試題需要的結果,只能用并查集來描述。
你可能還有點迷糊并查集能怎么玩,看完這篇然后回頭看這兩個問題(分別杭電1232和杭電1272)。
問題1:
某省調查城鎮交通狀況,得到現有城鎮道路統計表,表中列出了每條道路直接連通的城鎮。省政府“暢通工程”的目標是使全省任何兩個城鎮間都可以實現交通(但不一定有直接的道路相連,只要互相間接通過道路可達即可)。問最少還需要建設多少條道路?
這個問題很容易,給定的關系看看需要合并多少次就知道最少的建設道路數量。
問題二:
小希希望任意兩個房間有且僅有一條路徑可以相通(除非走了回頭路)。小希現在把她的設計圖給你,讓你幫忙判斷她的設計圖是否符合她的設計思路。比如下面的例子,前兩個是符合條件的,但是最后一個卻有兩種方法從5到達8。

這個問題也很容易了,根據關系集合進行合如果兩個元素已經屬于一個集合,那就說明不滿足要求啦。
通過上面介紹,相信你已經清楚并查集就是解決集合中一些元素的合并和查詢問題,現在就帶你解析這個算法。
開始時候森林中每個元素沒有任何操作,它們之間是相互獨立的。我們通常會使用數組來表示這個森林(數組下標對應第幾個元素),在初始化的時候數組中的各個值為-1,表示各自自己是一個集合(各自為王),你可能會問為啥是-1而不是一個其他的數,那是因為用負數可以代表這個元素是某個集合的根,然后它的權值表示集合中元素的個數。
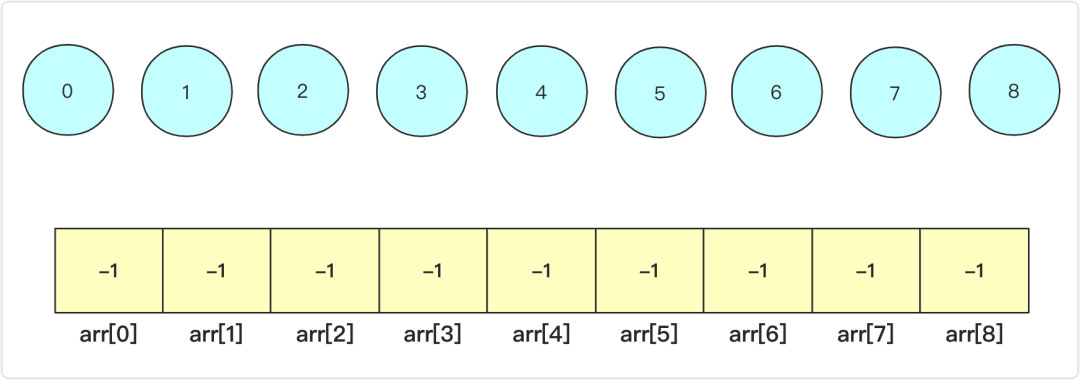
這里合并,并沒有你想象的直接合并那么簡單,這里合并是合并a所在的集合和b所在的集合,但在操作層面a,b可能并不是根節點,所以也要先判斷一下。
為了便于理解,這里羅列一下最初操作可能的情況,初始時候各個元素都是獨立的集合,那么直接a指向b(或者b指向a)即arr[a]=b,同時為了表示這個集合有多少個,原本-1的b再次-1.即arr[b]=-2.表示以b為父根的集合節點有|-2|個。例如進行union(1,4),union(5,7)操作之后如圖所示:
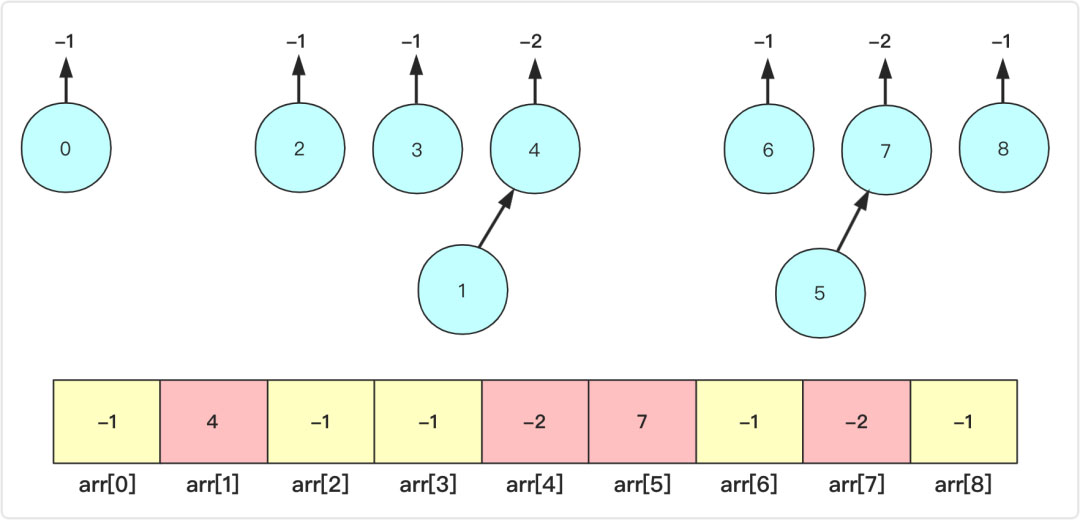
正常情況的union(int a,int b),假設我們就是a合并到b上,把b當成父集合來看。a、b都可能是葉子節點,也可能是根節點。
此時你可以先分別找到a,b的父節點fa,fb(這個根可能是它自己),然后合并fa和fb兩個節點,例如上面如果union(1,5)那么其實就是等價union(4,7)。
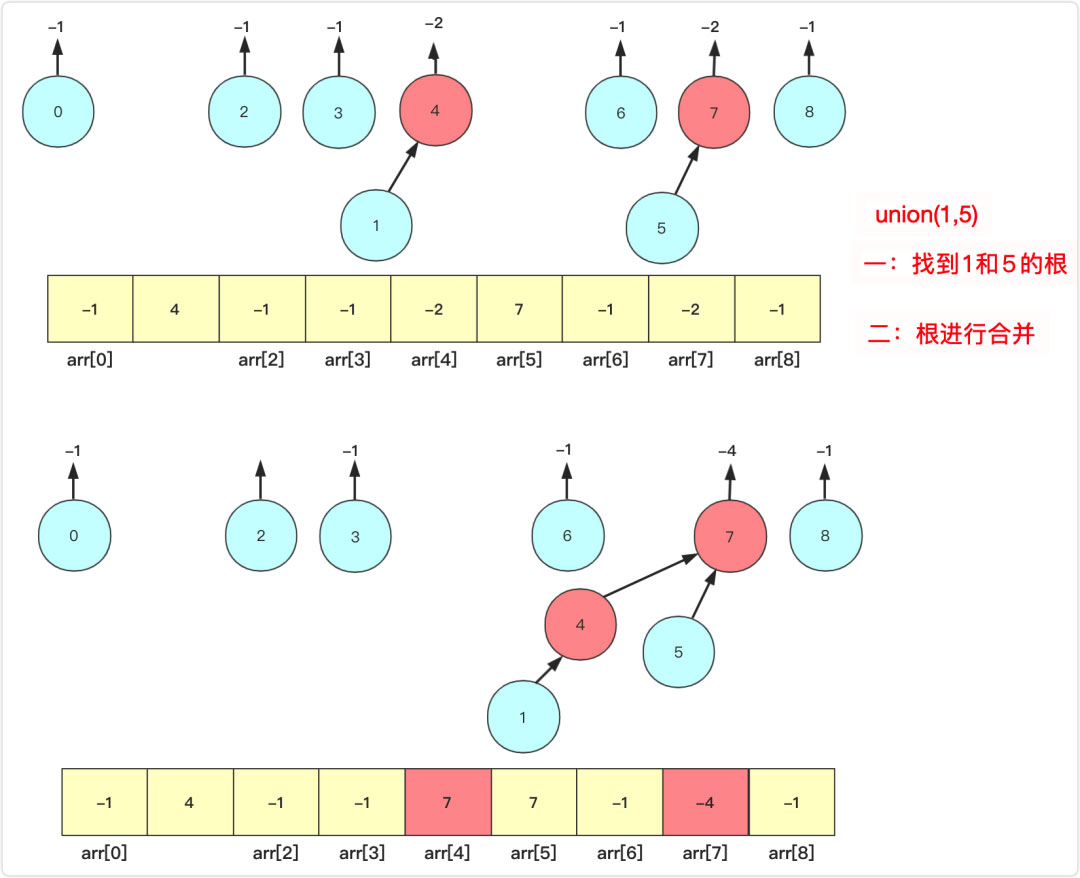
為什么不直接操作a,b而是要找到他們的父親進行操作?
原因1是因為a,b可能是葉子節點,其值是正的表示已經有父親了,如果直接操作會使其與原來的集合分離開。另外集合中的數量(負數)也不能有效疊加。
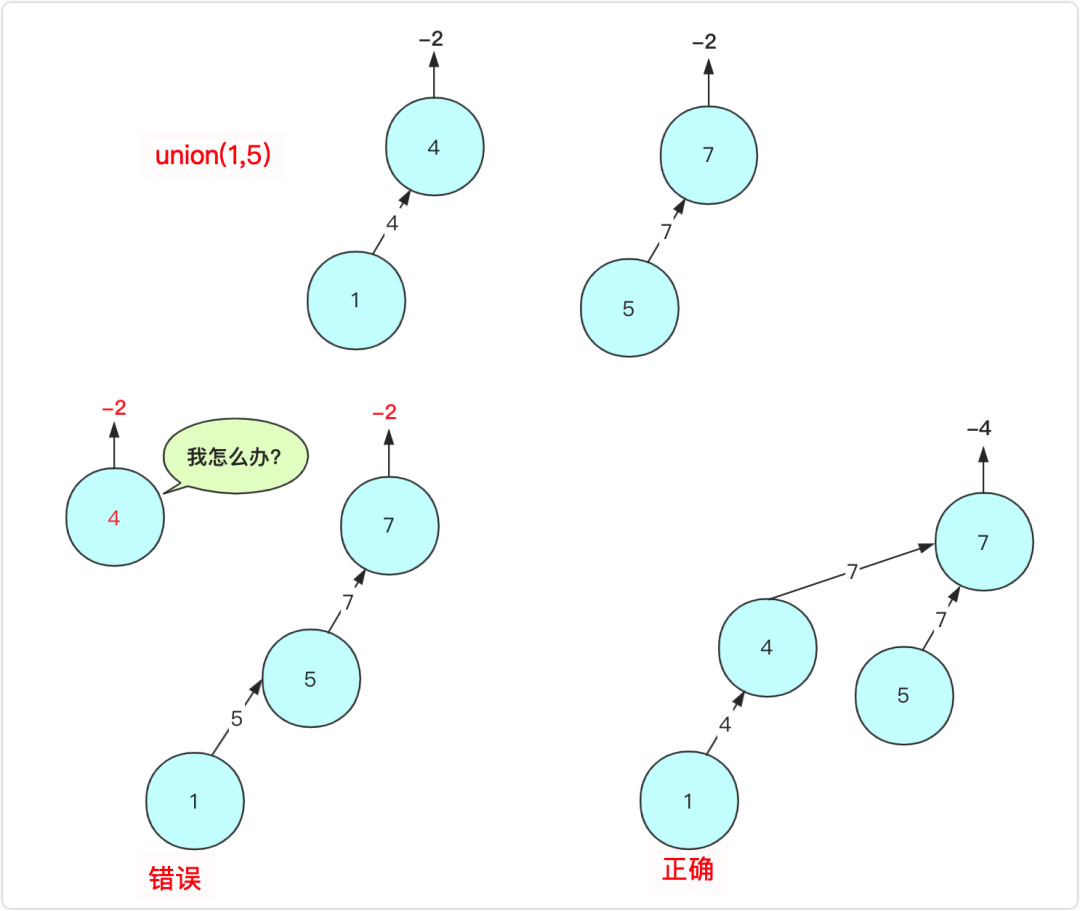
原因2是因為合并的時候如果合并如果a,b是非根節點操作,可能會造成這個樹的深度太大,不利于集合a中的查詢效率。

查詢,其實就是查詢這個節點的根節點是啥(也稱代表元),這個過程也有點類似遞歸的過程,葉子節點值如果為正,那么就繼續查找這個值得位置的結果,一直到值為負數的時候說明找到根節點,可以直接返回。
不過在查詢的過程中可以順便路徑優化,這樣在頻繁查詢能夠大大降低時間復雜度。
你以為上面的就是并查集的全部?不不不,并查集還有不少需要掌握嘞,估計細心的人可能也會發現一些問題。
你可能會有疑問:
如何查看a,b是否在同一個集合?
查看是否在一個集合,只需要查看節點根祖先的結果是否相同即可。因為只有根的數值是負的,而其他都是正數表示指向的元素。所以只需要一直尋找直到不為正數進行比較即可!
a,b合并,究竟是a的祖先合并在b的祖先上,還是b的祖先合并在a上?
這里會遇到兩種情況,這個選擇也是非常重要的。你要弄明白一點:樹的高度+1的化那么整個元素查詢的效率都會降低!
所以我們通常是:小樹指向大樹(或者低樹指向高樹),這個使得查詢效率能夠增加!
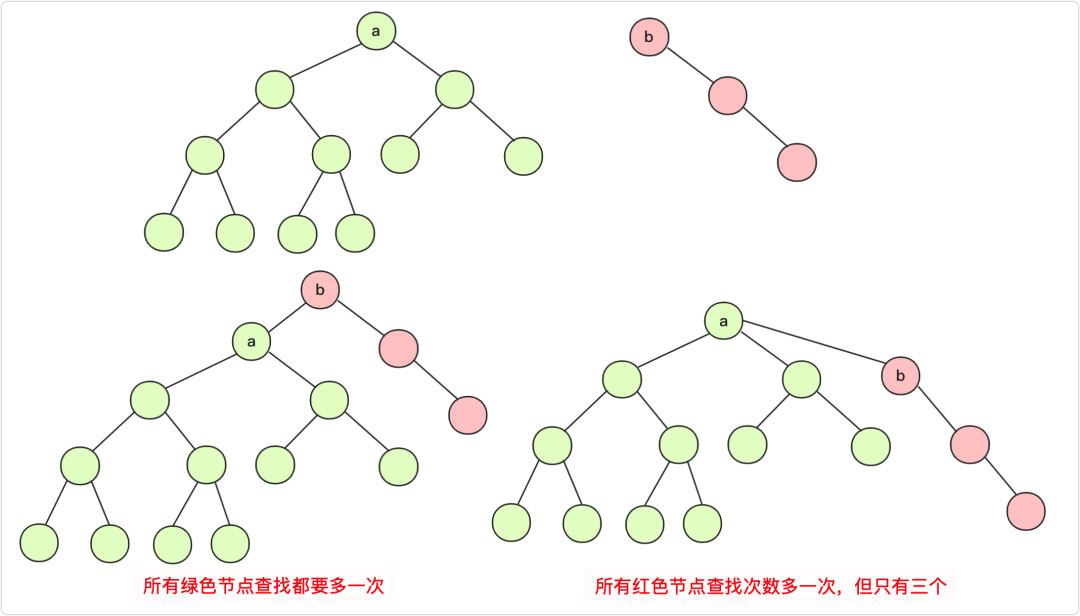
當然,在高度和數量的選擇上,還需要你自己選擇和考慮。
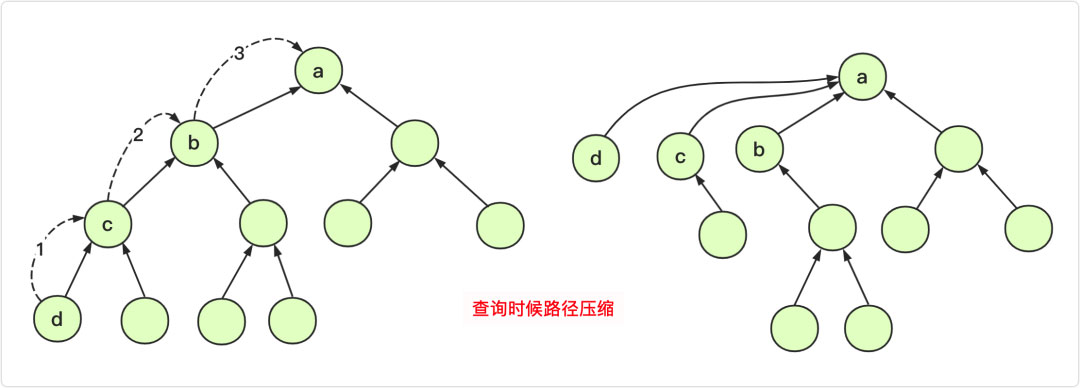
查找途中能不能路徑壓縮:
每次查詢,自下向上。當我們調用遞歸的時候,可以順便壓縮路徑(將當前數組的值等于遞歸返回的根節點的值),我們查找一個元素只需要直接找到它的祖先,所以當它距離祖先近那么下次查詢就很快。并且壓縮路徑的代價并不大!
試想一下,如果一個分支的深度為1000,不壓縮路徑那么這個分支每個節點平均查找次數為500,壓縮一次下次再查找就是1次。
學會路徑壓縮,你基本可以秒殺大部分并查集的題。
并查集實現起來較為簡單,直接貼代碼!
import java.util.Scanner;
public class DisjointSet {
static int tree[]=new int[100000];//假設有500個值
public DisjointSet() {set(this.tree);}
public DisjointSet(int tree[])
{
this.tree=tree;
set(this.tree);
}
//初始化所有都是-1 有兩個好處,這樣他們指向-1說明是自己,
//第二,-1代表當前森林有-(-1)個
public void set(int a[])
{
int l=a.length;
for(int i=0;i<l;i++)
{
a[i]=-1;
}
}
public int search(int a)//返回頭節點的數值
{
if(tree[a]>0)//說明是子節點
{
return tree[a]=search(tree[a]);//路徑壓縮
}
else
return a;
}
public int value(int a)//返回a所在樹的大小(個數)
{
if(tree[a]>0)
{
return value(tree[a]);
}
else
return -tree[a];
}
public void union(int a,int b)//表示 a,b所在的樹合并
{
int a1=search(a);//a根
int b1=search(b);//b根
if(a1==b1) {System.out.println(a+"和"+b+"已經在一棵樹上");}
else {
if(tree[a1]<tree[b1])//這個是負數,為了簡單減少計算,不在調用value函數
{
tree[a1]+=tree[b1];//個數相加 注意是負數相加
tree[b1]=a1; //b樹成為a的子樹,直接指向a;
}
else
{
tree[b1]+=tree[a1];//個數相加 注意是負數相加
tree[a1]=b1; //b樹成為a的子樹,直接指向a;
}
}
}
public static void main(String[] args)
{
DisjointSet d=new DisjointSet();
d.union(1,2);
d.union(3,4);
d.union(5,6);
d.union(1,6);
d.union(22,24);
d.union(3,26);
d.union(36,24);
System.out.println(d.search(6)); //頭
System.out.println(d.value(6)); //大小
System.out.println(d.search(22)); //頭
System.out.println(d.value(22)); //大小
}
}并查集屬于簡單但是很高效率的數據結構。在集合中經常會遇到。如果不采用并查集而傳統暴力效率太低,而不被采納。
到此,相信大家對“Java實現數據結構中的并查集”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





