溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何使用IMPUTE2進行基因型填充”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何使用IMPUTE2進行基因型填充”吧!
提供了以下兩大功能
haplotype phasing,單倍型分析
genotype imputation,基因型填充
基因型填充的基本模型示意如下
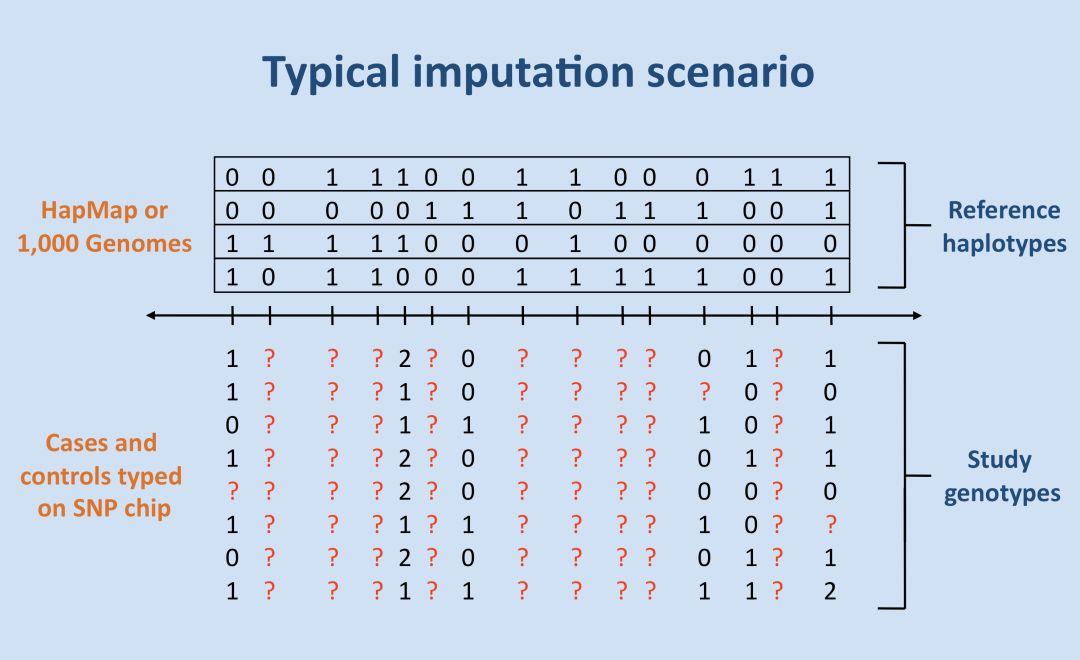
需要兩個基本元素,第一個是檢測樣本的分型結果,即圖中所示的study genotypes, 第二個元素稱之為reference panel, 對應圖中的reference haplotypes, 利用高密度的reference panel對檢驗樣本為覆蓋到的SNP位點,或者缺失的分型結果進行填充,對應圖中問號表示的位點。
該軟件的安裝比較簡單,官網提供了編譯好的可執行文件,下載解壓縮即可
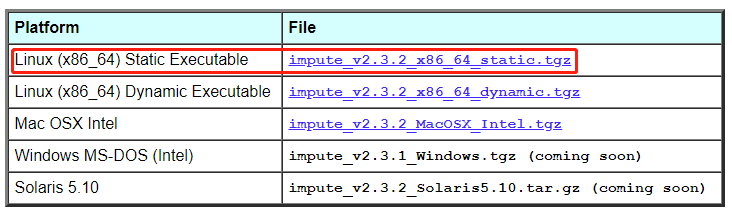
對應的代碼如下
wget https://mathgen.stats.ox.ac.uk/impute/impute_v2.3.2_x86_64_static.tgz
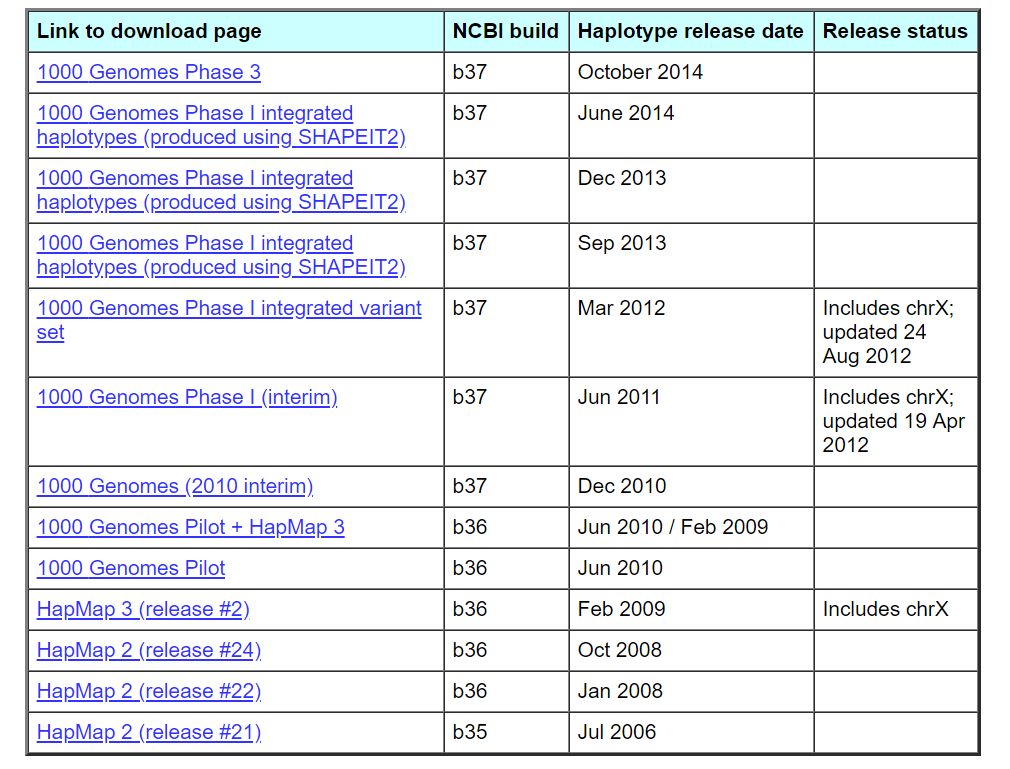
tar xzvf impute_v2.3.2_x86_64_static.tgz除了軟件外,還需要reference panel,官網也提供了對應的下載文件,包括hapmap和1000G兩個常用的reference panel,鏈接如下
https://mathgen.stats.ox.ac.uk/impute/impute_v2.html#download
impute2官方推薦了一套基因型填充的最佳實踐,步驟如下
對檢測樣本的原始分型結果質控,使用GWAS分析的質控條件即可
校正基因組版本,hapmap和1000G都是基于hg19版本,必須保證和reference panel的基因組版本一致,才可以準確填充,如果不一致,可以使用UCSC的liftOver工具進行轉換
校正鏈的方向, hapmap和1000G的結果都是基于參考基因組的正鏈表示的,為了和reference panel進行匹配,必須將芯片的分型結果也統計校正到正鏈
選擇reference panel,1000G比hapmap的snp位點數量更多,密度更大,是目前最常用的reference panel, 其中又分成了不同的人群,對于某些研究,可以選擇更加契合自己的人群,比如選擇亞洲人群進行分析
基因型填充
填充后的質控,對填充后的分型結果進行過濾,同樣基于GWAS的質控條件
關聯分析,填充后的snp位點數量更多,有助于檢測陽性的信號
顯著關聯區域的重新填充,對于GWAS篩選出來的陽性區域,可以使用更加嚴格的參數重新填充,再進行關聯分析,確保分析的可靠性
impute2提供了以下兩種用法
填充準確率最高的方法,基本用法如下
impute2 \
-m ./Example/example.chr22.map \
-h ./Example/example.chr22.1kG.haps \
-l ./Example/example.chr22.1kG.legend \
-g ./Example/example.chr22.study.gens \
-strand_g ./Example/example.chr22.study.strand \
-int 20.4e6 20.5e6 \
-Ne 20000 \
-o ./Example/example.chr22.one.phased.impute2基因型填充計算量非常大,所以需要先拆分染色體,對每條染色體進行填充。上述是官方自帶的一個例子,對22號染色體進行填充,-m參數指定連鎖圖譜,-h和-l參數指定reference panel的單倍型結果,對應后綴為haps和legend,-g參數指定study樣本的分型結果,格式為GEN, -strand_g參數指定snp位點的正負鏈信息,用于校正鏈的方向,-int參數指定需要填充的染色體區域,包含了起始和終止兩個位置的值,對應的長須推薦小于5Mb, -Ne參數官方推薦取值為20000,-o參數指定輸出的填充結果。
增加了對study樣本的pre-phasing, 運行速度更快,pre-phasing基本用法如下
impute2 \
-prephase_g \
-m ./Example/example.chr22.map \
-g ./Example/example.chr22.study.gens \
-int 20.4e6 20.5e6 \
-Ne 20000 \
-o ./Example/example.chr22.prephasing.impute2-prephase_g參數表示對study樣本進行pre-phasing, -m參數可以提高單倍型分析的準確性。
基于pre-phasing的結果進行填充的基本用法如下
./impute2 \
-use_prephased_g \
-m ./Example/example.chr22.map \
-h ./Example/example.chr22.1kG.haps \
-l ./Example/example.chr22.1kG.legend \
-known_haps_g ./Example/example.chr22.prephasing.impute2_haps \
-strand_g ./Example/example.chr22.study.strand \
-int 20.4e6 20.5e6 \
-Ne 20000 \
-o ./Example/example.chr22.one.phased.impute2
-phase即使采用兩步法,基因型填充仍然是一個運行時間很長的步驟,在實際操作中,可以同時結合染色體拆分和染色體劃分窗口兩種方式,再加上并行來提升運行效率。
官方提供了更多的用法示例,鏈接如下
https://mathgen.stats.ox.ac.uk/impute/impute_v2.html#examples
感謝各位的閱讀,以上就是“如何使用IMPUTE2進行基因型填充”的內容了,經過本文的學習后,相信大家對如何使用IMPUTE2進行基因型填充這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





