溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python爬蟲的起點是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
好好的講爬蟲和HTTP有什么關系?其實我們常說的爬蟲(也叫網絡爬蟲)就是使用一些網絡協議發起的網絡請求,而目前使用最多的網絡協議便是HTTP/S網絡協議簇。
在真實瀏覽網頁我們是通過鼠標點擊網頁然后由瀏覽器幫我們發起網絡請求,那在Python中我們又如何發起網絡請求的呢?答案當然是庫,具體哪些庫?豬哥給大家列一下:
Python2: httplib、httplib2、urllib、urllib2、urllib3、requests
Python3: httplib2、urllib、urllib3、requests
Python網絡請求庫有點多,而且還看見網上還都有用過的,那他們之間有何關系?又該如何選擇?
httplib/2:
這是一個Python內置http庫,但是它是偏于底層的庫,一般不直接用。
而httplib2是一個基于httplib的第三方庫,比httplib實現更完整,支持緩存、壓縮等功能。
一般這兩個庫都用不到,如果需要自己 封裝網絡請求可能會需要用到。
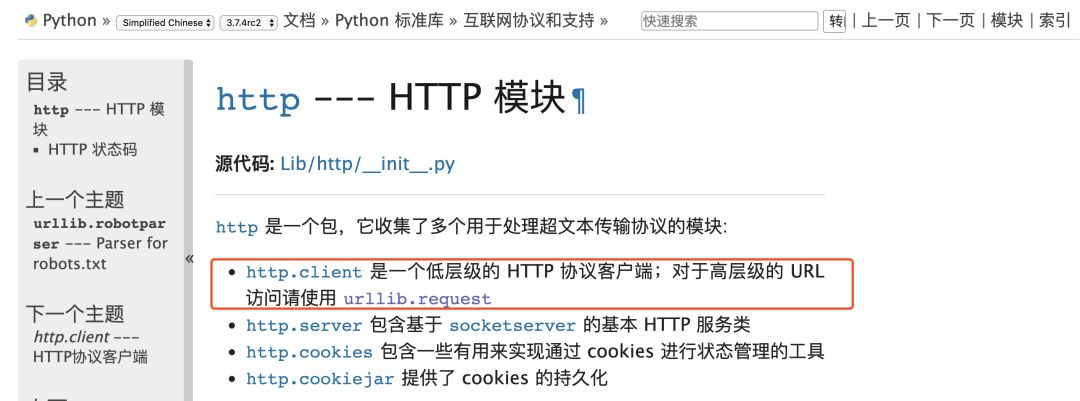
urllib/urllib2/urllib3:
urlliib是一個基于httplib的上層庫,而urllib2和urllib3都是第三方庫,urllib2相對于urllib增加一些高級功能,如:
HTTP身份驗證或Cookie等,在Python3中將urllib2合并到了urllib中。
urllib3提供線程安全連接池和文件post等支持,與urllib及urllib2的關系不大。
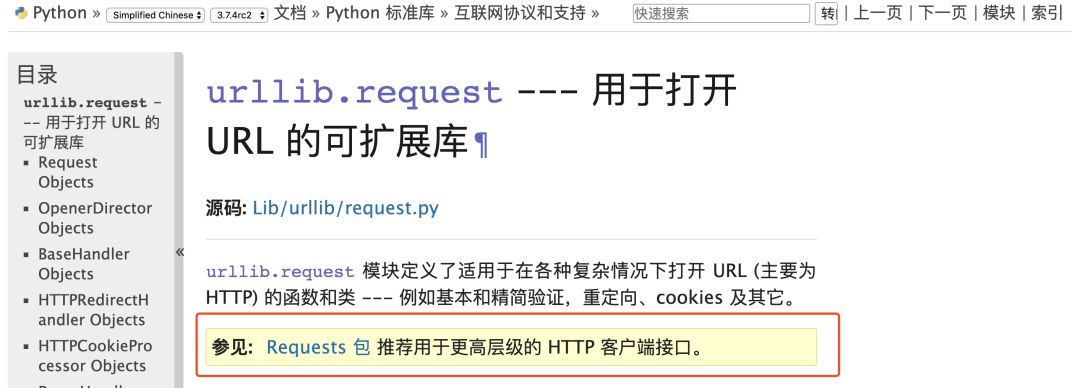
requests:
requests庫是一個基于urllib/3的第三方網絡庫,它的特點是功能強大,API優雅。
由上圖我們可以看到,對于http客戶端python官方文檔也推薦我們使用requests庫,實際工作中requests庫也是使用的比較多的庫。
綜上所述,我們選擇選擇requests庫作為我們爬蟲入門的起點。另外以上的這些庫都是同步網絡庫,如果需要高并發請求的話可以使用異步網絡庫:aiohttp,這個后面豬哥也會為大家講解。
希望大家永遠記住:學任何一門語言,都不要忘記去看看官方文檔。也許官方文檔不是最好的入門教程,但絕對是最新、最全的教學文檔!
requests的官方文檔(目前已支持中文)鏈接:http://cn.python-requests.org
源代碼地址:https://github.com/kennethreitz/requests
從首頁中讓HTTP服務人類這幾個字中我們便能看出,requests核心宗旨便是讓用戶使用方便,間接表達了他們設計優雅的理念。
注:PEP 20便是鼎鼎大名的Python之禪。
警告:非專業使用其他 HTTP 庫會導致危險的副作用,包括:安全缺陷癥、冗余代碼癥、重新發明輪子癥、啃文檔癥、抑郁、頭疼、甚至死亡。
都說requests功能強大,那我們來看看requests到底有哪些功能特性吧:
Keep-Alive & 連接池
國際化域名和 URL
帶持久 Cookie 的會話
瀏覽器式的 SSL 認證
自動內容解碼
基本/摘要式的身份認證
優雅的 key/value Cookie
自動解壓
Unicode 響應體
HTTP(S) 代理支持
文件分塊上傳
流下載
連接超時
分塊請求
支持 .netrc
requests 完全滿足今日 web 的需求。Requests 支持 Python 2.6—2.7以及3.3—3.7,而且能在 PyPy 下完美運行
pip install requests
如果是pip3則使用
pip3 install requests
如果你使用anaconda則可以
conda install requests
如果你不想用命令行,可在pycharm中這樣下載庫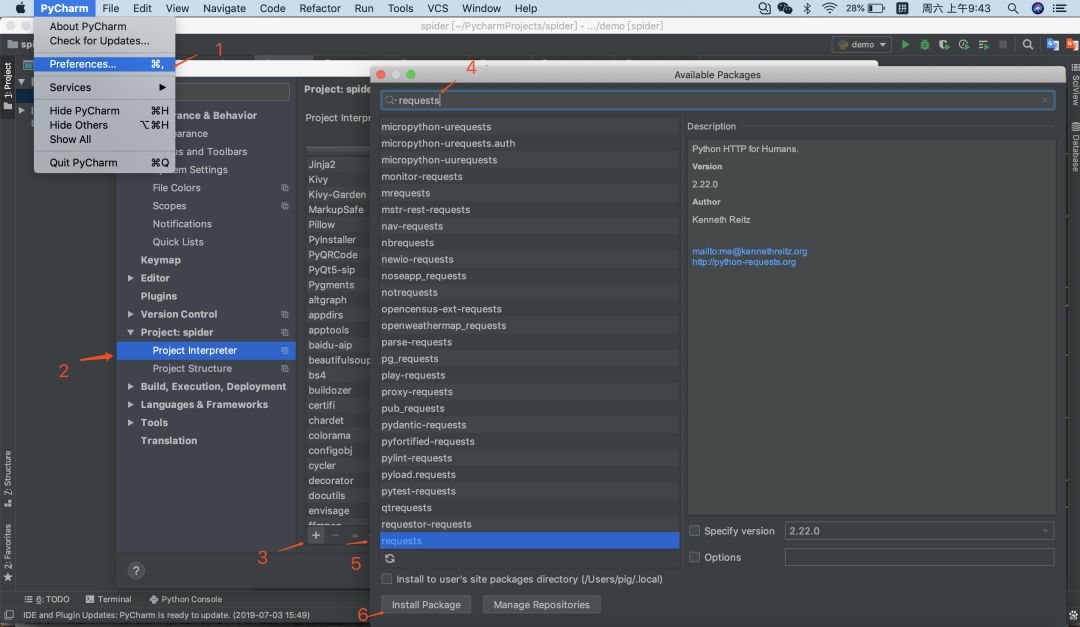
下圖是豬哥之前工作總結的一個項目開發流程,算是比較詳細,在開發一個大型的項目真的需要這么詳細,不然項目上線出故障或者修改需求都無法做項目復盤,到時候程序員就有可能背鍋祭天。。。
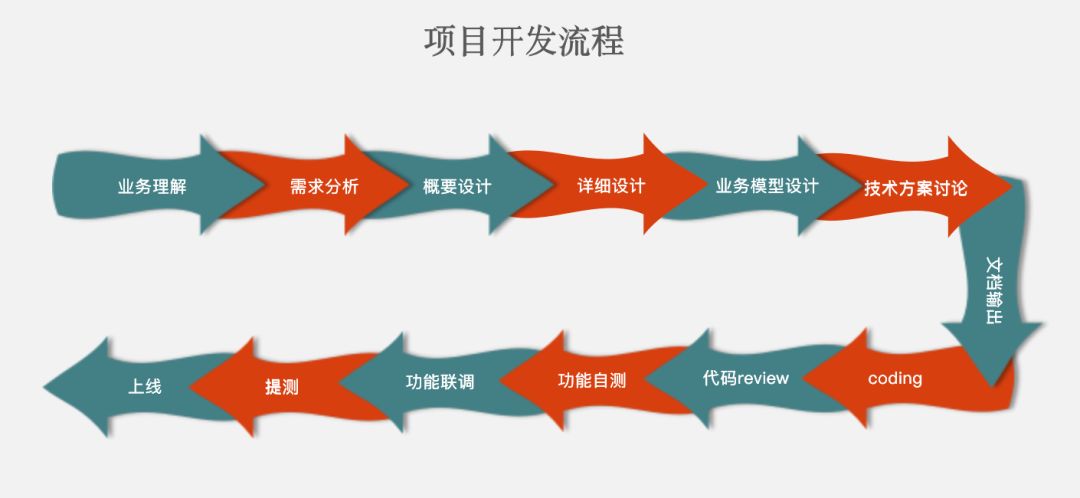
言歸正傳,給大家看項目的開發流程是想引出爬蟲爬取數據的流程:
確定需要爬取的網頁
瀏覽器檢查數據來源(靜態網頁or動態加載)
尋找加載數據url的參數規律(如分頁)
代碼模擬請求爬取數據
豬哥就以某東商品頁為例子帶大家學習爬蟲的簡單流程,為什么以某東下手而不是某寶?因為某東瀏覽商品頁不需要登錄,簡單便于大家快速入門!
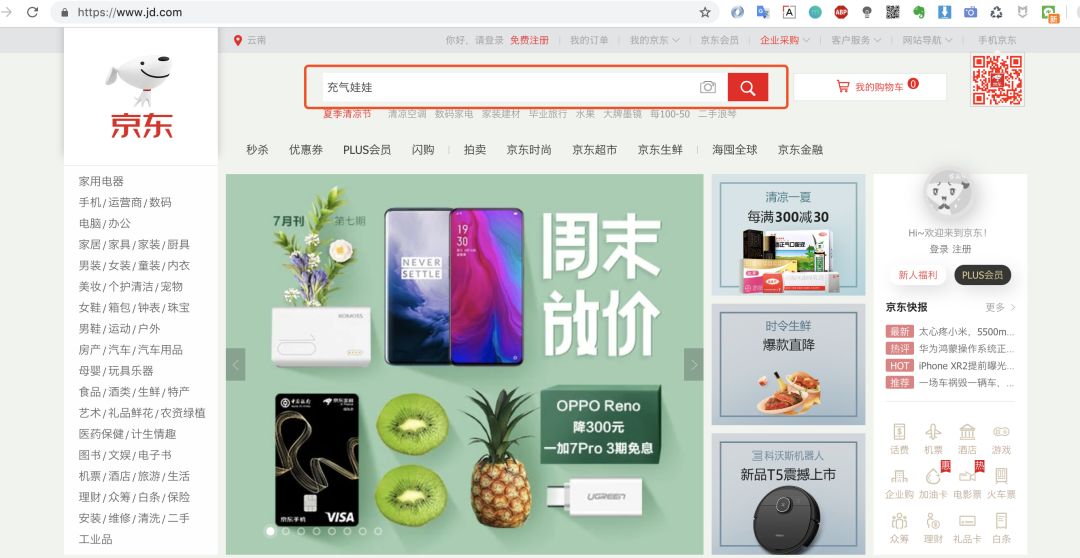
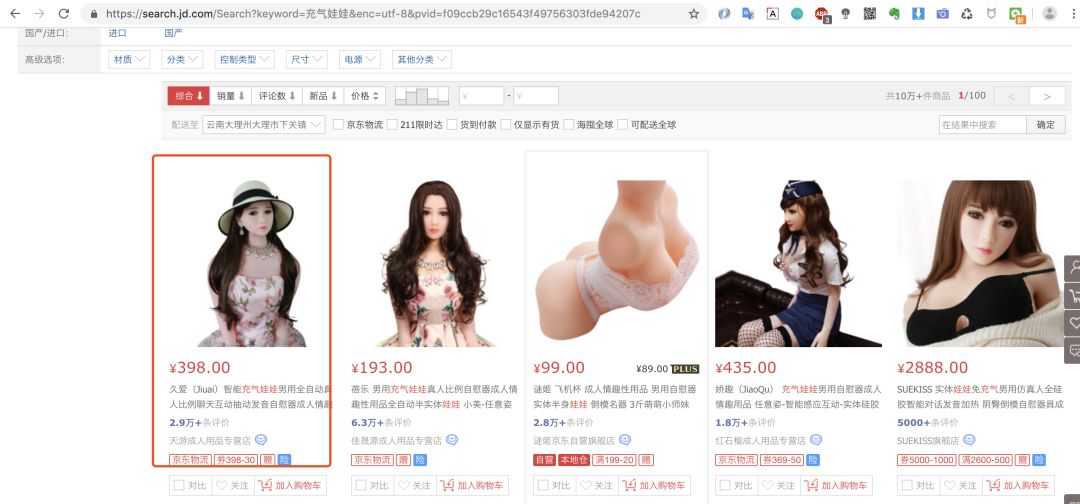
ps:豬哥并不是在開車哦,為什么選這款商品?因為后面會爬取這款商品的評價做數據分析,是不是很刺激!
打開瀏覽器調試窗口是為了查看網絡請求,看看數據是怎么加載的?是直接返回靜態頁面呢,還是js動態加載呢?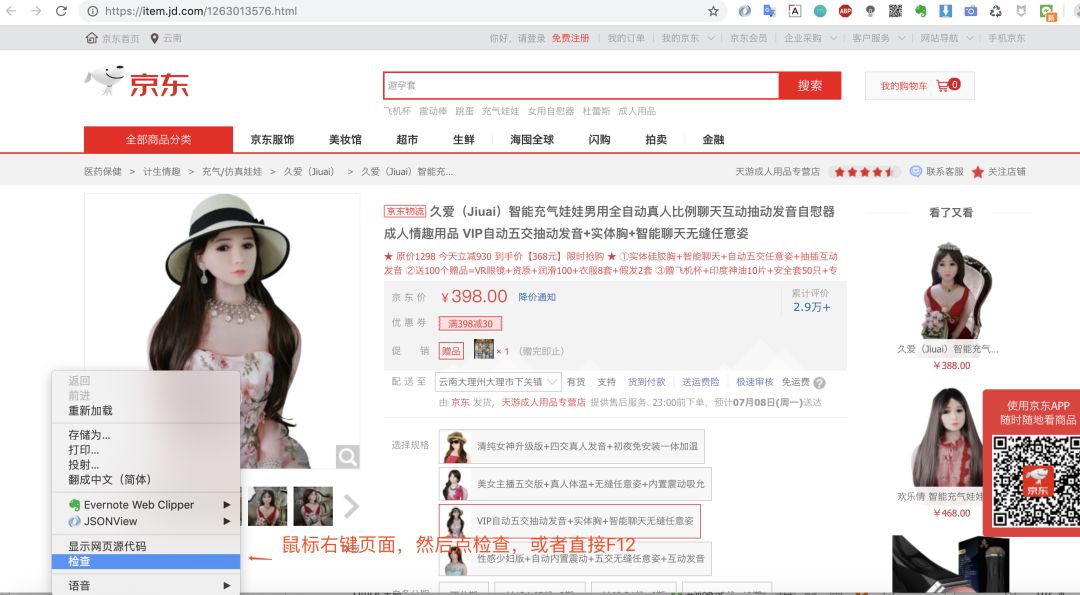
鼠標右鍵然后點檢查或者直接F12即可打開調試窗口,這里豬哥推薦大家使用Chrome瀏覽器,為什么?因為好用,程序員都在用!具體的Chrome如何調試,大家自行網上看教程!
打開調試窗口之后,我們就可以重新請求數據,然后查看返回的數據,確定數據來源。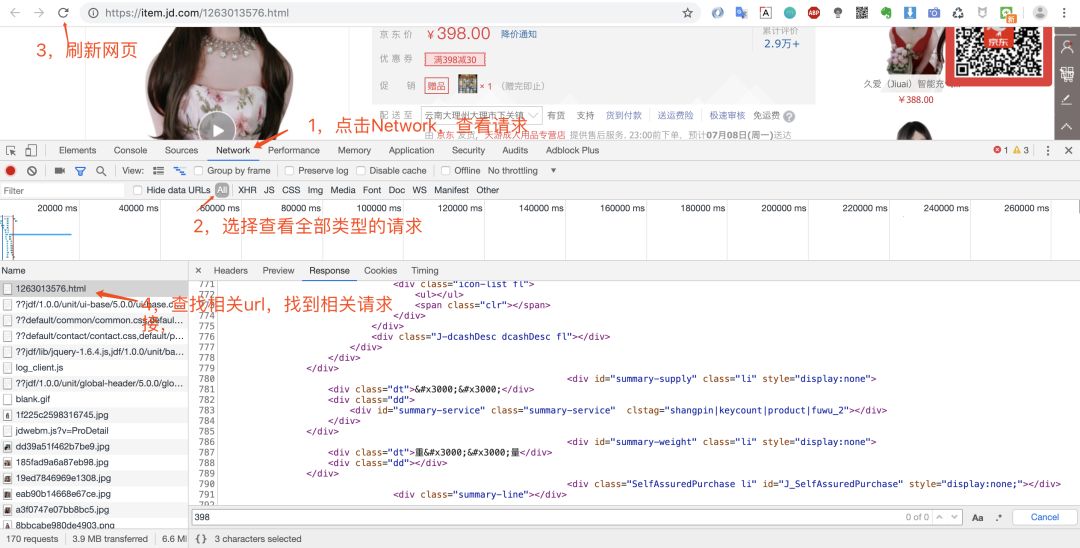
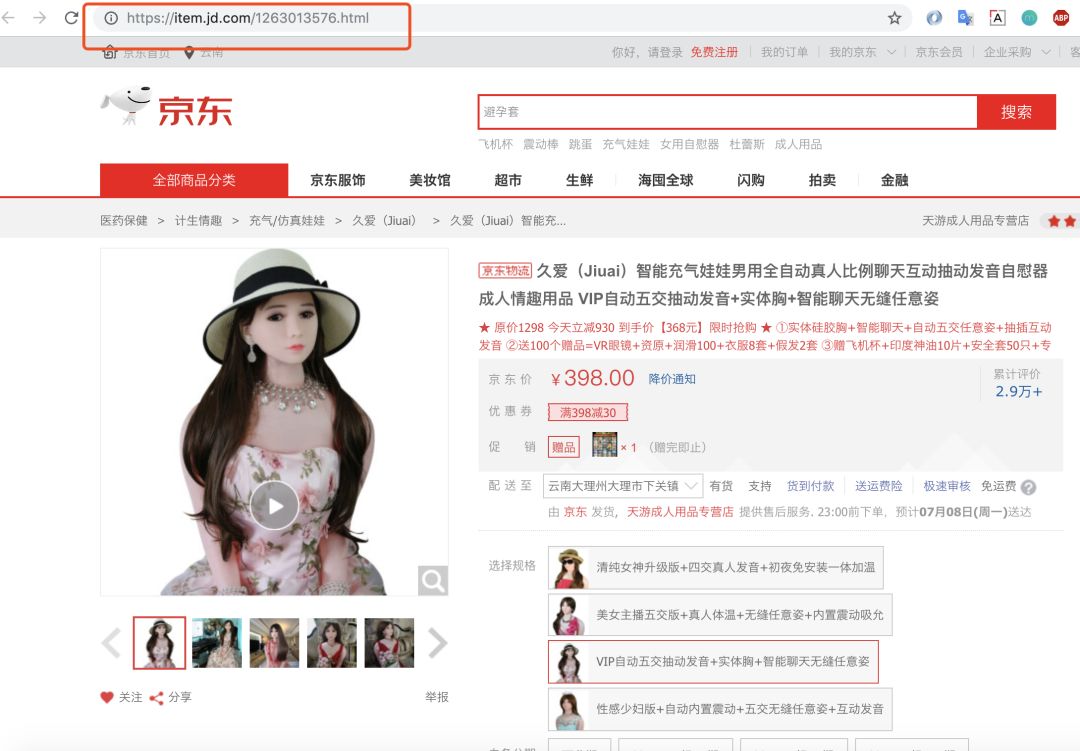
我們可以看到第一個請求鏈接:https://item.jd.com/1263013576.html 返回的數據便是我們要的網頁數據。因為我們是爬取商品頁,所以不存在分頁之說。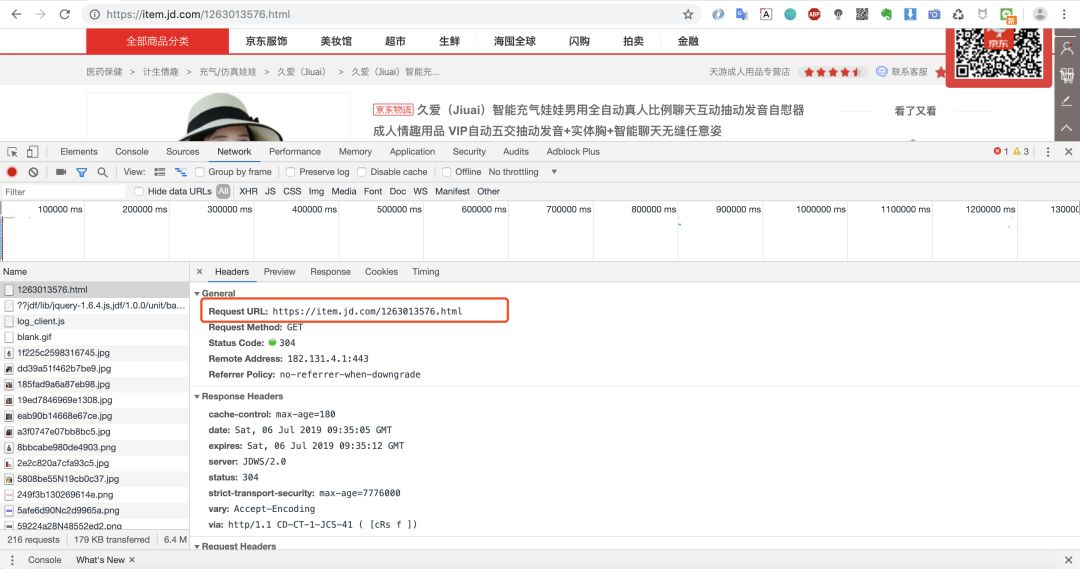
當然價格和一些優惠券等核心信息是通過另外的請求加載,這里我們暫時不討論,先完成我們的第一個小例子!
獲取url鏈接之后我們來開始寫代碼吧
import requestsdef spider_jd():
"""爬取京東商品頁"""
url = 'https://item.jd.com/1263013576.html'
try:
r = requests.get(url) # 有時候請求錯誤也會有返回數據
# raise_for_status會判斷返回狀態碼,如果4XX或5XX則會拋出異常
r.raise_for_status()
print(r.text[:500]) except:
print('爬取失敗')if __name__ == '__main__':
spider_jd()檢查返回結果
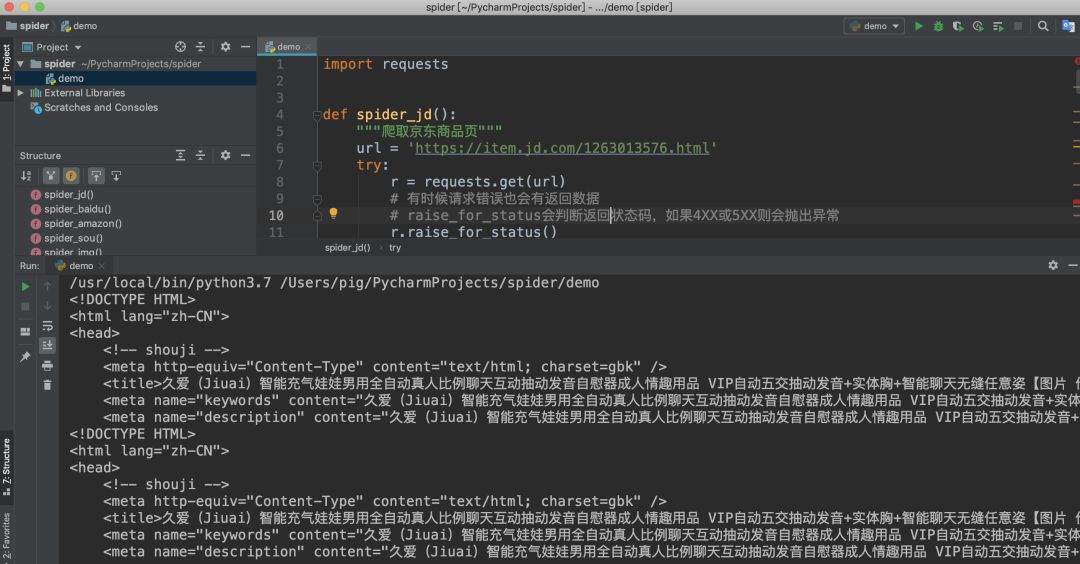
至此我們就完成了某東商品頁的爬取,雖然案例簡單,代碼很少,但是爬蟲的流程基本差不多,希望想學爬蟲的同學自己動動手實踐一把,選擇自己喜歡的商品抓取一下,只有自己動手才能真的學到知識!
上面我們使用了requests的get方法,我們可以查看源碼發現還有其他幾個方法:post、put、patch、delete、options、head,他們就是對應HTTP的請求方法。
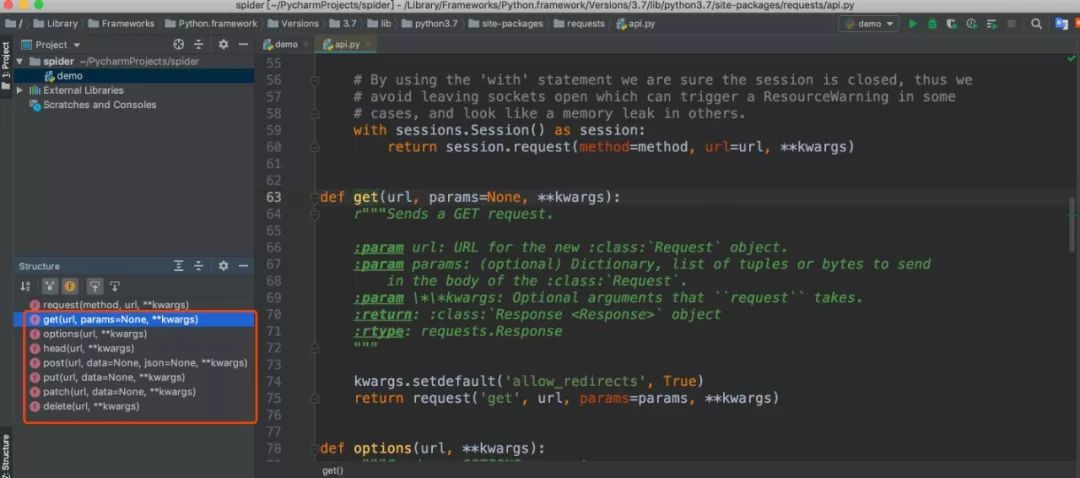
這里簡單給大家列一下,后面會用大量的案例來用而后學,畢竟枯燥的講解沒人愿意看。
requests.post('http://httpbin.org/post', data = {'key':'value'})
requests.patch('http://httpbin.org/post', data = {'key':'value'})
requests.put('http://httpbin.org/put', data = {'key':'value'})
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')注:httpbin.org是一個測試http請求的網站,能正常回應請求
看完上述內容,你們掌握Python爬蟲的起點是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
上述內容就是Python爬蟲的起點是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





