溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python爬蟲的原理是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1、網絡連接原理
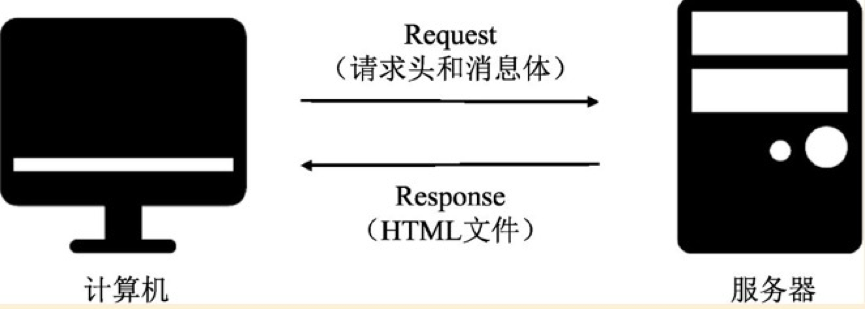
如上圖,簡單的說,網絡連接就是計算機發起請求,服務器返回相應的HTML文件,至于請求頭和消息體待爬蟲環節在詳細解釋。
2、爬蟲原理
爬蟲原理就是模擬計算機對服務器發起Request請求,接收服務器端的Response內容并解析,提取所需要的信息。
往往一次請求不能完全得到所有網頁的信息數據,然后就需要合理設計爬取的過程,來實現多頁面和跨頁面的爬取。
多頁面爬取過程是怎樣的呢?
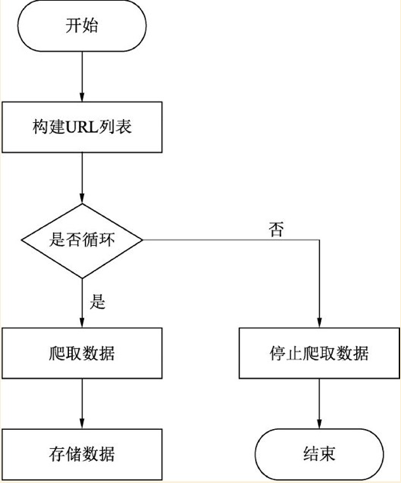
基本思路:
1、由于多頁面結構可能相似,可以先手動翻頁觀察URL
2、得到所有URL
3、根據每頁URL定義函數爬取數據
4、循環URL爬取存儲
跨頁面爬取過程是怎樣的呢?
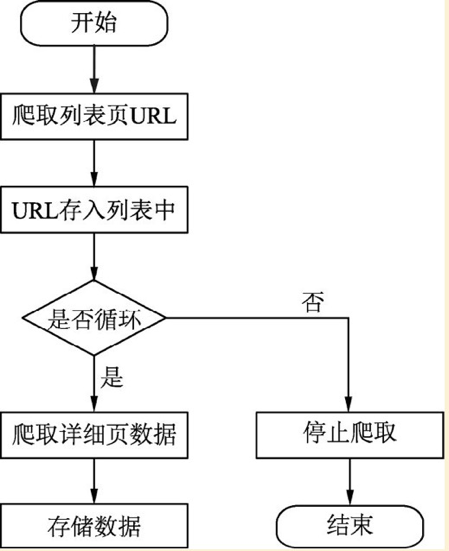
基本思路:
1、找到所有URL
2、定義爬取詳細頁函數代碼
3、進入詳細頁獲取詳細數據
4、存儲,循環完成,結束
3、網頁到底是怎么樣的呢?
右鍵選擇“檢查”,打開網頁源代碼,可以看到上面是HTML文件,下面是CSS樣式,其中HTML中<script></script>包含的部分就是JavaScript代碼。
我們瀏覽的網頁就是瀏覽器渲染后的結果,就是把HTML、CSS、JavaScript代碼進行翻譯得到的頁面界面。有一個通俗的比喻就是:加入網頁是一個房子,HTML就是房子的框架和格局,CSS就是房子的軟裝樣式,如地板和油漆,javaScript就是電器。
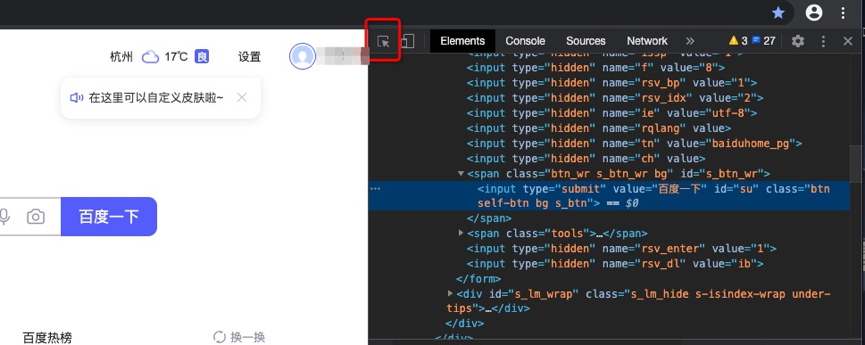
如打開百度搜索,將鼠標移至“百度一下”按鈕位置,右鍵選擇“檢查”,就可以看到網頁源碼位置。
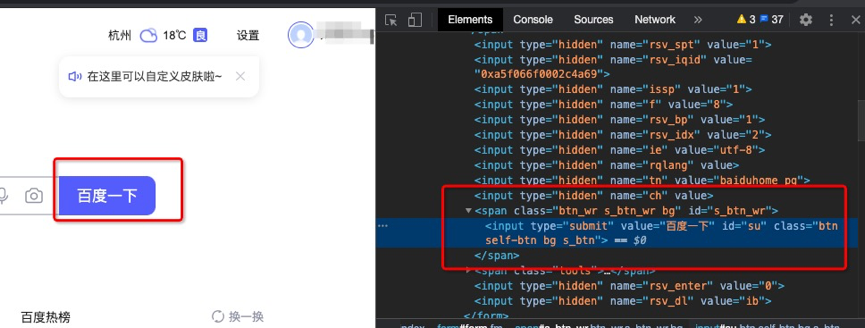
或者直接打開右鍵源碼,通過點擊網頁源碼頁面左上角鼠標狀圖標,然后移動到網頁的具體位置,就可以看到。
上述內容就是Python爬蟲的原理是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





