溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python爬蟲是什么及怎么應用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人)就是模擬瀏覽器發送網絡請求,接收請求響應,一種按照一定的規則,自動地抓取互聯網信息的程序。
原則上,只要是瀏覽器(客戶端)能做的事情,爬蟲都能夠做。
互聯網大數據時代,給予我們的是生活的便利以及海量數據爆炸式的出現在網絡中。
過去,我們通過書籍、報紙、電視、廣播或許信息,這些信息數量有限,且是經過一定的篩選,信息相對而言比較有效,但是缺點則是信息面太過于狹窄了。不對稱的信息傳導,以致于我們視野受限,無法了解到更多的信息和知識。
互聯網大數據時代,我們突然間,信息獲取自由了,我們得到了海量的信息,但是大多數都是無效的垃圾信息。
例如新浪微博,一天產生數億條的狀態更新,而在百度搜索引擎中,隨意搜一條——減肥100,000,000條信息。
在如此海量的信息碎片中,我們如何獲取對自己有用的信息呢?
答案是篩選!
通過某項技術將相關的內容收集起來,在分析刪選才能得到我們真正需要的信息。
這個信息收集分析整合的工作,可應用的范疇非常的廣泛,無論是生活服務、出行旅行、金融投資、各類制造業的產品市場需求等等……都能夠借助這個技術獲取更精準有效的信息加以利用。
網絡爬蟲技術,雖說有個詭異的名字,讓能第一反應是那種軟軟的蠕動的生物,但它卻是一個可以在虛擬世界里,無往不前的利器。
我們平時都說Python爬蟲,其實這里可能有個誤解,爬蟲并不是Python獨有的,可以做爬蟲的語言有很多例如:PHP,JAVA,C#,C++,Python,選擇Python做爬蟲是因為Python相對來說比較簡單,而且功能比較齊全。
首先我們需要下載python,我下載的是官方最新的版本 3.8.3
其次我們需要一個運行Python的環境,我用的是pychram

也可以從官方下載,
我們還需要一些庫來支持爬蟲的運行(有些庫Python可能自帶了)

差不多就是這幾個庫了,良心的我已經在后面寫好注釋了

(爬蟲運行過程中,不一定就只需要上面幾個庫,看你爬蟲的一個具體寫法了,反正需要庫的話我們可以直接在setting里面安裝)
我做的是爬取豆瓣評分電影Top250的爬蟲代碼
我們要爬取的就是這個網站:https://movie.douban.com/top250
這邊我已經爬取完畢,給大家看下效果圖,我是將爬取到的內容存到xls中
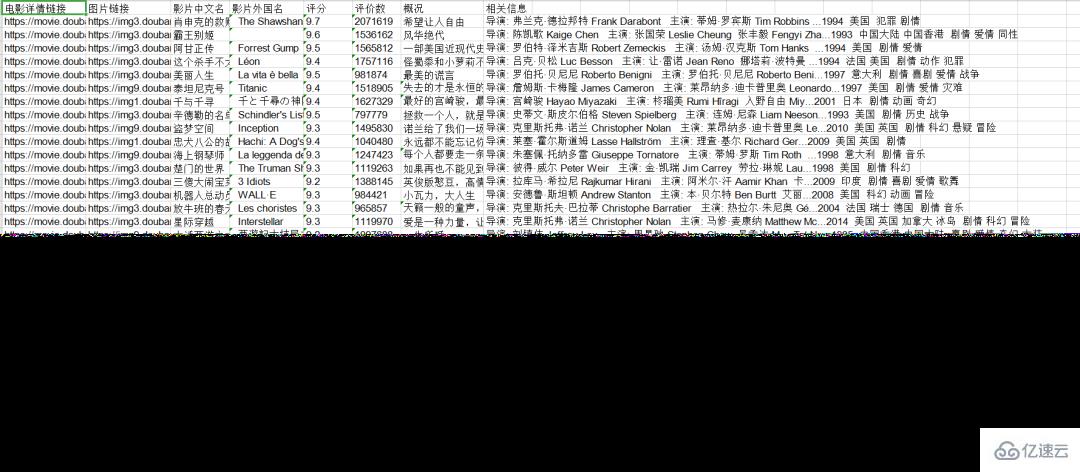
我們的爬取的內容是:電影詳情鏈接,圖片鏈接,影片中文名,影片外國名,評分,評價數,概況,相關信息。
先把代碼發放上來,然后我根據代碼逐步解析
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 網頁解析,獲取數據
import re # 正則表達式,進行文字匹配`
import urllib.request, urllib.error # 制定URL,獲取網頁數據
import xlwt # 進行excel操作
#import sqlite3 # 進行SQLite數據庫操作
findLink = re.compile(r'<a href="(.*?)">') # 創建正則表達式對象,標售規則 影片詳情鏈接的規則
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人評價</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的網頁鏈接
# 1.爬取網頁
datalist = getData(baseurl)
savepath = "豆瓣電影Top250.xls" #當前目錄新建XLS,存儲進去
# dbpath = "movie.db" #當前目錄新建數據庫,存儲進去
# 3.保存數據
saveData(datalist,savepath) #2種存儲方式可以只選擇一種
# saveData2DB(datalist,dbpath)
# 爬取網頁
def getData(baseurl):
datalist = [] #用來存儲爬取的網頁信息
for i in range(0, 10): # 調用獲取頁面信息的函數,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存獲取到的網頁源碼
# 2.逐一解析數據
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('p', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部電影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通過正則表達式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除轉義字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一個URL的網頁內容
def askURL(url):
head = { # 模擬瀏覽器頭部信息,向豆瓣服務器發送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用戶代理,表示告訴豆瓣服務器,我們是什么類型的機器、瀏覽器(本質上是告訴瀏覽器,我們可以接收什么水平的文件內容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存數據到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #創建workbook對象
sheet = book.add_sheet('豆瓣電影Top250', cell_overwrite_ok=True) #創建工作表
col = ("電影詳情鏈接","圖片鏈接","影片中文名","影片外國名","評分","評價數","概況","相關信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d條" %(i+1)) #輸出語句,用來測試
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #數據
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #輸出查詢語句,用來測試
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #創建數據表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存數據到數據庫
if __name__ == "__main__": # 當程序執行時
# 調用函數
main()
# init_db("movietest.db")
print("爬取完畢!")下面我根據代碼,從下到下給大家講解分析一遍-- codeing = utf-8 --,開頭的這個是設置編碼為utf-8 ,寫在開頭,防止亂碼。
然后下面 import就是導入一些庫,做做準備工作,(sqlite3這庫我并沒有用到所以我注釋起來了)。
下面一些find開頭的是正則表達式,是用來我們篩選信息的。
(正則表達式用到 re 庫,也可以不用正則表達式,不是必須的。)
大體流程分三步走:
1. 爬取網頁
2.逐一解析數據
3. 保存網頁
先分析流程1,爬取網頁,baseurl 就是我們要爬蟲的網頁網址,往下走,調用了 getData(baseurl) ,
我們來看 getData方法
for i in range(0, 10): # 調用獲取頁面信息的函數,10次 url = baseurl + str(i * 25)
這段大家可能看不懂,其實是這樣的:
因為電影評分Top250,每個頁面只顯示25個,所以我們需要訪問頁面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我們只要在baseurl后面加上數字就會跳到相應頁面,比如i=1時
https://movie.douban.com/top250?start=25
我放上超鏈接,大家可以點擊看看會跳到哪個頁面,畢竟實踐出真知。
然后又調用了askURL來請求網頁,這個方法是請求網頁的主體方法,
怕大家翻頁麻煩,我再把代碼復制一遍,讓大家有個直觀感受
def askURL(url):
head = { # 模擬瀏覽器頭部信息,向豆瓣服務器發送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用戶代理,表示告訴豆瓣服務器,我們是什么類型的機器、瀏覽器(本質上是告訴瀏覽器,我們可以接收什么水平的文件內容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html這個askURL就是用來向網頁發送請求用的,那么這里就有老鐵問了,為什么這里要寫個head呢?
這是因為我們要是不寫的話,訪問某些網站的時候會被認出來爬蟲,顯示錯誤,錯誤代碼
這是一個梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一個茶壺
所以我們需要 “裝” ,裝成我們就是一個瀏覽器,這樣就不會被認出來,
偽裝一個身份。
來,我們繼續往下走,
html = response.read().decode("utf-8")這段就是我們讀取網頁的內容,設置編碼為utf-8,目的就是為了防止亂碼。
訪問成功后,來到了第二個流程:
2.逐一解析數據
解析數據這里我們用到了 BeautifulSoup(靚湯) 這個庫,這個庫是幾乎是做爬蟲必備的庫,無論你是什么寫法。
下面就開始查找符合我們要求的數據,用BeautifulSoup的方法以及 re 庫的
正則表達式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 創建正則表達式對象,標售規則 影片詳情鏈接的規則 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)人評價</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我們要求的數據,然后存進 dataList , 所以 dataList 里就存放著我們需要的數據了。
最后一個流程:
3.保存數據
# 3.保存數據 saveData(datalist,savepath) #2種存儲方式可以只選擇一種 # saveData2DB(datalist,dbpath)
保存數據可以選擇保存到 xls 表, 需要(xlwt庫支持)
也可以選擇保存數據到 sqlite數據庫, 需要(sqlite3庫支持)
這里我選擇保存到 xls 表 ,這也是為什么我注釋了一大堆代碼,注釋的部分就是保存到 sqlite 數據庫的代碼,二者選一就行
保存到 xls 的主體方法是 saveData (下面的saveData2DB方法是保存到sqlite數據庫):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #創建workbook對象
sheet = book.add_sheet('豆瓣電影Top250', cell_overwrite_ok=True) #創建工作表
col = ("電影詳情鏈接","圖片鏈接","影片中文名","影片外國名","評分","評價數","概況","相關信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d條" %(i+1)) #輸出語句,用來測試
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #數據
book.save(savepath) #保存創建工作表,創列(會在當前目錄下創建),
sheet = book.add_sheet('豆瓣電影Top250', cell_overwrite_ok=True) #創建工作表
col = ("電影詳情鏈接","圖片鏈接","影片中文名","影片外國名","評分","評價數","概況","相關信息")然后把 dataList里的數據一條條存進去就行。
最后運作成功后,會在左側生成這么一個文件

打開之后看看是不是我們想要的結果
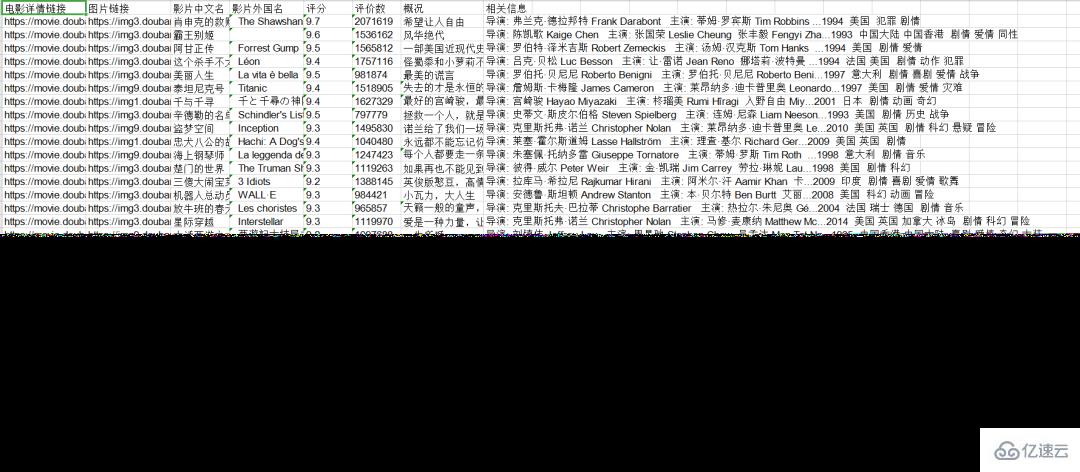
“Python爬蟲是什么及怎么應用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





