溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關基于Alluxio系統的Spark DataFrame高效存儲管理技術該怎么理解,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
越來越多的公司和組織開始將Alluxio和Spark一起部署從而簡化數據管理,提升數據訪問性能。Qunar最近將Alluxio部署在他們的生產環境中,從而將Spark streaming作業的平均性能提升了15倍,峰值甚至達到300倍左右。在未使用Alluxio之前,他們發現生產環境中的一些Spark作業會變慢甚至無法完成。而在采用Alluxio后這些作業可以很快地完成。我們將介紹如何使用Alluxio幫助Spark變得更高效,具體地,我們將展示如何使用Alluxio高效存儲Spark DataFrame。
用戶使用Alluxio存儲Spark DataFrame非常簡單:通過Spark DataFrame write API將DataFrame作為一個文件寫入Alluxio。通常的做法是使用df.write.parquet()將DataFrame寫成parquet文件。在DataFrame對應的parquet文件被寫入Alluxio后,在Spark中可以使用sqlContext.read.parquet()讀取。為了分析理解使用Alluxio存儲DataFrame和使用Spark內置緩存存儲DataFrame在性能上差異,我們進行了如下的一些實驗。
實驗相關設置如下:
硬件配置:單個worker安裝在一個節點上,節點配置:61 GB內存 + 8核CPU;
軟件版本:Spark 2.0.0和Alluxio1.2.0,參數均為缺省配置;
運行方式:以standalone模式運行Spark和Alluxio。
在本次實驗中,我們使用Spark內置的不同緩存級別存儲DataFrame對比測試使用Alluxio存儲DataFrame,然后收集分析性能測試結果。同時通過改變DataFrame的大小來展示存儲的DataFrame的規模對性能的影響。
Spark DataFrame可以使用persist() API存儲到Spark緩存中。persist()可以緩存DataFrame數據到不同的存儲媒介。
本次實驗使用了以下Spark緩存存儲級別(StorageLevel):
MEMORY_ONLY:在Spark JVM內存中存儲DataFrame對象
MEMORY_ONLY_SER:在Spark JVM內存中存儲序列化后的DataFrame對象
DISK_ONLY: 將DataFrame數據存儲在本地磁盤
下面是一個如何使用persist() API緩存DataFrame的例子:
df.persist(MEMORY_ONLY)
將DataFrame保存在內存中的另一種方法是將DataFrame作為一個文件寫入Alluxio。Spark支持將DataFrame寫成多種不同的文件格式,在本次實驗中,我們將DataFrame寫成parquet文件。
下面是一個將DataFrame寫入Alluxio的例子:
DataFrame被保存后(無論存儲在Spark內存還是Alluxio中),應用可以讀取DataFrame以進行后續的計算任務。本次實驗中,我們創建了一個包含2列的DataFrame(這2列的數據類型均為浮點型),計算任務則是分別計算這2列數據之和。
當DataFrame存儲在Alluxio時,Spark讀取DataFrame就像從Alluxio中讀取文件一樣簡單。下面是一個從Alluxio中讀取DataFrame的例子:
df = sqlContext.read.parquet(alluxioFile)
df.agg(sum("s1"), sum("s2")).show()我們分別從Alluxio中 parquet文件以及各種Spark存儲級別緩存中讀取DataFrame,并進行上述的聚合計算操作。下圖顯示了不同存儲方案中的聚合操作的完成時間。
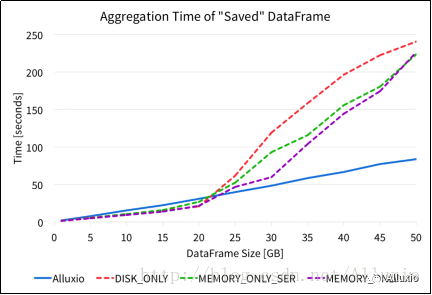
從上圖可以看出,從Alluxio中讀取DataFrame進行聚合操作具有比較穩定的執行性能。對于從Spark緩存中讀取DataFrame,在DataFrame規模較小時執行性能具有一定優勢,但是隨著DataFrame規模的增長,性能急劇下降。在本文的實驗環境中,對于各種Spark內置的存儲級別, DataFrame規模達到20 GB以后,聚合操作的性能下降比較明顯。
另一方面,相比使用Spark內置緩存,使用Alluxio存儲DataFrame并進行聚合操作,其性能在小規模數據上略有劣勢。然而,隨著DataFrame數據規模的增長,從Alluxio中讀取DataFrame性能更好,因為從Alluxio中讀取DataFrame的耗時幾乎始終隨著數據規模線性增長。由于使用Alluxio存儲DataFrame的讀寫性能具有較好的線性可擴展性,上層應用可以穩定地以內存速度處理更大規模的數據。
使用Alluxio存儲DataFrame的另一大優勢是可以在不同Spark應用或作業之間共享存儲在Alluxio中的數據。當一個DataFrame文件被寫入Alluxio后,它可以被不同的作業、SparkContext、甚至不同的計算框架共享。因此,如果一個存儲在Alluxio中的DataFrame被多個應用頻繁地訪問,那么所有的應用均可以從Alluxio內存中直接讀取數據,并不需要重新計算或者從另外的底層外部數據源中讀取數據。
為了驗證采用Alluxio共享內存的優勢,我們在如上述的同樣的實驗環境中進行相同規模的DataFrame聚合操作。當使用50 GB規模的DataFrame時,我們在單個Spark應用中進行聚合操作,并且記錄該聚合操作的耗時。沒有使用Alluxio時,Spark應用需要每次都從數據源讀取數據(在本次實驗中是一個本地SSD)。在使用Alluxio時,數據可以直接從Alluxio內存中讀取。下圖顯示了2次聚合操作的完成時間性能對比。使用Alluxio的情況下,聚合操作快了約2.5倍。

在上圖的實驗中,數據源是本地SSD。如果DataFrame來自訪問起來更慢或不穩定的數據源,Alluxio的優勢就更加明顯了。舉例而言,下圖是DataFrame數據源由本地SSD替換為某公有云存儲的實驗結果。

這張圖顯示是執行7次聚合操作的平均完成時間。圖中的紅色的誤差范圍(error bar)代表完成時間的最大和最小范圍。這些結果清晰地顯示出Alluxio可以顯著提升操作的平均性能。這是因為使用Alluxio緩存DataFrame時,Spark可以直接從Alluxio內存中讀取DataFrame,而不是從遠程的公有云存儲中。平均而言,Alluxio可以加速上述DataFrame的聚集操作性能超過10倍。
另一方面,由于數據源是公有云系統,Spark必須跨網絡遠程讀取數據。錯綜復雜的網絡狀況會導致讀取性能難以預測。這種性能的不穩定性從上圖中的誤差范圍(error bar)可以很明顯地看出。在不使用Alluxio的情況下,Spark作業的完成時間變化范圍超過1100秒。當使用Alluxio之后,完成時間的變化范圍只有10秒。在本實驗中,Alluxio能夠將數據讀取造成的不穩定性降低超過100倍。
由于共有云存儲系統的網絡訪問性能不可預測性,最慢的Spark作業執行時間超過1700秒, 比平均慢2倍。然而,當使用Alluxio時,最慢的Spark作業執行時間大約比平均時間只慢6秒。因此,如果以最慢的Spark作業執行時間來評估,Alluxio可以加速DataFrame聚合操作超過17倍。
關于基于Alluxio系統的Spark DataFrame高效存儲管理技術該怎么理解就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





