溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Spark MLlib機器學習是什么”,在日常操作中,相信很多人在Spark MLlib機器學習是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Spark MLlib機器學習是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
MLlib是Spark提供的一個機器學習庫,通過調用MLlib封裝好的算法,可以輕松地構建機器學習應用。它提供了非常豐富的機器學習算法,比如分類、回歸、聚類及推薦算法。除此之外,MLlib對用于機器學習算法的API進行了標準化,從而使將多種算法組合到單個Pipeline或工作流中變得更加容易。
機器學習是人工智能的一個分支,是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、計算復雜性理論等多門學科。機器學習理論主要是設計和分析一些讓計算機可以自動“學習”的算法。因為學習算法中涉及了大量的統計學理論,機器學習與推斷統計學聯系尤為密切,也被稱為統計學習理論。算法設計方面,機器學習理論關注可以實現的,行之有效的學習算法。

機器學習的應用已遍及人工智能的各個分支,如專家系統、自動推理、自然語言理解、模式識別、計算機視覺、智能機器人等領域。機器學習是人工智能的一個分支學科,主要研究的是讓機器從過去的經歷中學習經驗,對數據的不確定性進行建模,對未來進行預測。機器學習應用的領域很多,比如搜索、推薦系統、垃圾郵件過濾、人臉識別、語音識別等等。
大數據時代,數據產生的速度是非常驚人的。互聯網、移動互聯網、物聯網、GPS等等都會在無時無刻產生著數據。處理這些數據所需要的存儲與計算的能力也在成幾何級增長,由此誕生了一系列的以Hadoop為代表的大數據技術,這些大數據技術為處理和存儲這些數據提供了可靠的保障。
數據、信息、知識是由大到小的三個層次。單純的數據很難說明一些問題,需要加之人們的一些經驗,將其轉換為信息,所謂信息,也就是為了消除不確定性,我們常說信息不對稱,指的就是在不能夠獲取足夠的信息時,很難消除一些不確定的因素。而知識則是最高階段,所以數據挖掘也叫知識發現。
機器學習的任務就是利用一些算法,作用于大數據,然后挖掘背后所蘊含的潛在的知識。訓練的數據越多,機器學習就越能體現出優勢,以前機器學習解決不了的問題,現在通過大數據技術可以得到很好的解決,性能也會大幅度提升,如語音識別、圖像識別等等。
機器學習主要分為下面幾大類:
監督學習(supervised learning)
基本上是分類的同義詞。學習中的監督來自訓練數據集中標記的實例。比如,在郵政編碼識別問題中,一組手寫郵政編碼圖像與其對應的機器可讀的轉換物用作訓練實例,監督分類模型的學習。常見的監督學習算法包括:線性回歸、邏輯回歸、決策樹、樸素貝葉斯、支持向量機等等。
無監督學習(unsupervised learning)
本質上是聚類的同義詞。學習過程是無監督的,因為輸入實例沒有類標記。無監督學習的任務是從給定的數據集中,挖掘出潛在的結構。比如,把貓和狗的照片給機器,不給這些照片打任何標簽,但是希望機器能夠將這些照片分分類,最終機器會把這些照片分為兩大類,但是并不知道哪些是貓的照片,哪些是狗的照片,對于機器來說,相當于分成了 A、B 兩類。常見的無監督學習算法包括:K-means 聚類、主成分分析(PCA)等。
半監督學習(Semi-supervised learning)
半監督學習是一類機器學習技術,在學習模型時,它使用標記的和未標記的實例。讓學習器不依賴外界交互、自動地利用未標記樣本來提升學習性能,就是半監督學習。
半監督學習的現實需求非常強烈,因為在現實應用中往往能容易地收集到大量未標記樣本,而獲取標記卻需耗費人力、物力。例如,在進行計算機輔助醫學影像分析時,可以從醫院獲得大量醫學影像, 但若希望醫學專家把影像中的病灶全都標識出來則是不現實的有標記數據少,未標記數據多這個現象在互聯網應用中更明顯,例如在進行網頁推薦時需請用戶標記出感興趣的網頁, 但很少有用戶愿花很多時間來提供標記,因此,有標記網頁樣本少,但互聯網上存在無數網頁可作為未標記樣本來使用。
強化學習(reinforcement learning)
又稱再勵學習、評價學習,是一種重要的機器學習方法,在智能控制機器人及分析預測等領域有許多應用。強化學習的常見模型是標準的馬爾可夫決策過程(Markov Decision Process, MDP)。
MLlib是Spark的機器學習庫,通過該庫可以簡化機器學習的工程實踐工作。MLlib包含了非常豐富的機器學習算法:分類、回歸、聚類、協同過濾、主成分分析等等。目前,MLlib分為兩個代碼包:spark.mllib與spark.ml。
Spark MLlib是Spark的重要組成部分,是最初提供的一個機器學習庫。該庫有一個缺點:如果數據集非常復雜,需要做多次處理,或者是對新數據需要結合多個已經訓練好的單個模型進行綜合計算時,使用Spark MLlib會使程序結構變得復雜,甚至難以理解和實現。
spark.mllib是基于RDD的原始算法API,目前處于維護狀態。該庫下包含4類常見的機器學習算法:分類、回歸、聚類、協同過濾。指的注意的是,基于RDD的API不會再添加新的功能。
Spark1.2版本引入了ML Pipeline,經過多個版本的發展,Spark ML克服了MLlib處理機器學習問題的一些不足(復雜、流程不清晰),向用戶提供了基于DataFrame API的機器學習庫,使得構建整個機器學習應用的過程變得簡單高效。
Spark ML不是正式名稱,用于指代基于DataFrame API的MLlib庫 。與RDD相比,DataFrame提供了更加友好的API。DataFrame的許多好處包括Spark數據源,SQL / DataFrame查詢,Tungsten和Catalyst優化以及跨語言的統一API。
Spark ML API提供了很多數據特征處理函數,如特征選取、特征轉換、類別數值化、正則化、降維等。另外基于DataFrame API的ml庫支持構建機器學習的Pipeline,把機器學習過程一些任務有序地組織在一起,便于運行和遷移。Spark官方推薦使用spark.ml庫。
數據變換是數據預處理的一項重要工作,比如對數據進行規范化、離散化、衍生指標等等。Spark ML中提供了非常豐富的數據轉換算法,詳細可以參考官網,現歸納如下:
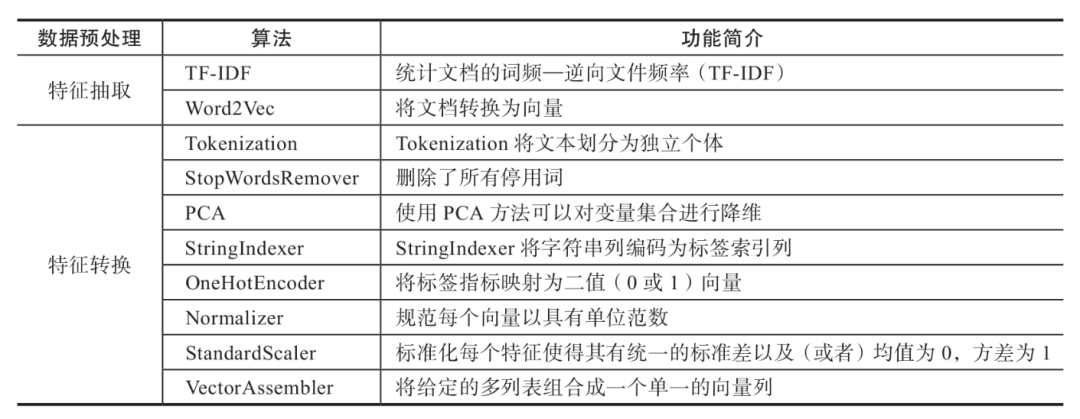
上面的轉換算法中,詞頻逆文檔頻率(TF-IDF)、Word2Vec、PCA是比較常見的,如果你做過文本挖掘處理,那么對此應該并不陌生。
大數據是機器學習的基礎,為機器學習提供充足的數據訓練集。在數據量非常大的時候,需要通過數據規約技術刪除或者減少冗余的維度屬性以來達到精簡數據集的目的,類似于抽樣的思想,雖然縮小了數據容量,但是并沒有改變數據的完整性。Spark ML提供的特征選擇和降維的方法如下表所示:

選擇特征和降維是機器學習中常用的手段,可以使用上述的方法減少特征的選擇,消除噪聲的同時還能夠維持原始的數據結構特征。尤其是主成分分析法(PCA),無論是在統計學領域還是機器學習領域,都起到了很重要的作用。
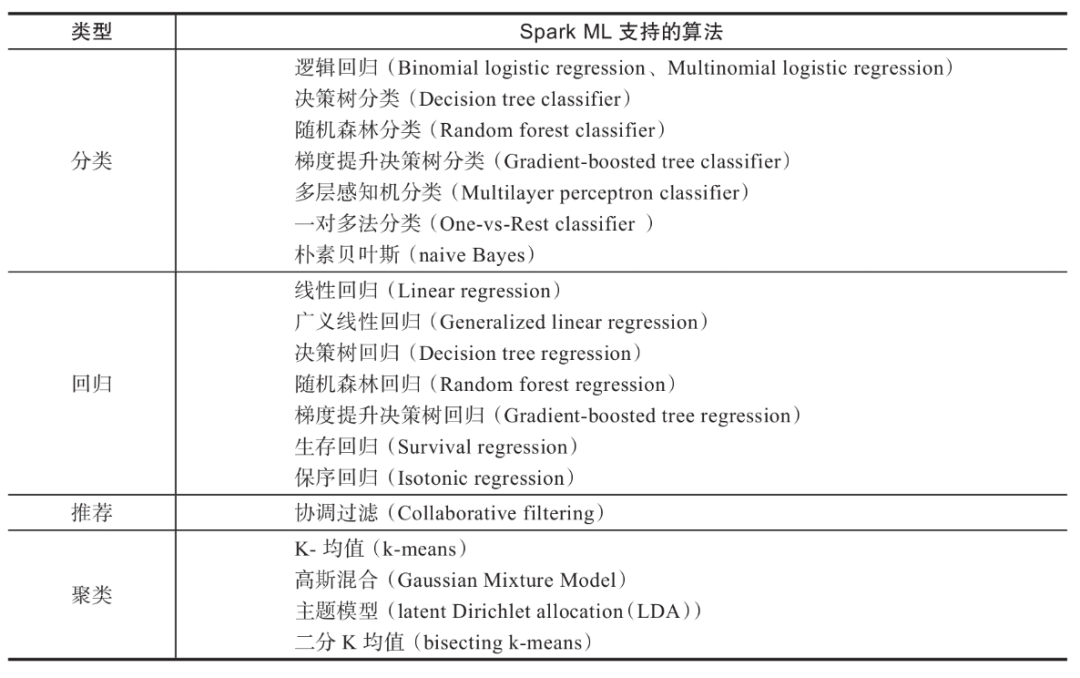
Spark支持分類、回歸、聚類、推薦等常用的機器學習算法。見下表:
到此,關于“Spark MLlib機器學習是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





