溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Spark的基礎知識點有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Spark的基礎知識點有哪些”吧!
Spark使用簡練優雅的Scala語言編寫,基于Scala提供了交互式編程體驗,同時提供多種方便易用的API。Spark遵循“一個軟件棧滿足不同應用場景”的設計理念,逐漸形成了一套完整的生態系統(包括 Spark提供內存計算框架、SQL即席查詢(Spark SQL)、流式計算(Spark Streaming)、機器學習(MLlib)、圖計算(Graph X)等),Spark可以部署在yarn資源管理器上,提供一站式大數據解決方案,可以同時支持批處理、流處理、交互式查詢。
MapReduce計算模型延遲高,無法勝任實時、快速計算的需求,因而只適用于離線場景,Spark借鑒MapReduce計算模式,但與之相比有以下幾個優勢(快、易用、全面):
Spark作為計算框架只是取代了Hadoop生態系統中的MapReduce計算框架,它任需要HDFS來實現數據的分布式存儲,Hadoop中的其他組件依然在企業大數據系統中發揮著重要作用。
Spark的不足:雖然Spark很快,但現在在生產環境中仍然不盡人意,無論擴展性、穩定性、管理性等方面都需要進一步增強;同時Spark在流處理領域能力有限,如果要實現亞秒級或大容量的數據獲取或處理需要其他流處理產品。
Cloudera旨在讓Spark流數據技術適用于80%的使用場合,就考慮到這一缺陷,在實時分析(而非簡單數據過濾或分發)場景中,很多以前使用S4或Storm等流式處理引擎的實現已經逐漸被Kafka+Spark Streaming代替;
Hadoop現在分三塊HDFS/MR/YARN,Spark的流行將逐漸讓MapReduce、Tez走進博物館;Spark只是作為一個計算引擎比MR的性能要好,但它的存儲和調度框架還是依賴于HDFS/YARN,Spark也有自己的調度框架,但不成熟,基本不可商用。
YARN實現了一個集群多個框架”,即在一個集群上部署一個統一的資源調度管理框架,并部署其他各種計算框架,YARN為這些計算框架提供統一的資源調度管理服務,并且能夠根據各種計算框架的負載需求調整各自占用的資源,實現集群資源共享和資源彈性收縮;
并且,YARN實現集群上的不同應用負載混搭,有效提高了集群的利用率;不同計算框架可以共享底層存儲,避免了數據集跨集群移動 ;
這里使用Spark on Yarn 模式部署,配置on yarn模式只需要修改很少配置,也不用使用啟動spark集群命令,需要提交任務時候須指定在yarn上。
Spark運行需要Scala語言,須下載Scala和Spark并解壓到家目錄,設置當前用戶的環境變量(~/.bash_profile),增加SCALA_HOME和SPARK_HOME路徑并立即生效;啟動scala命令和spark-shell命令驗證是否成功;Spark的配置文件修改按照官網教程不好理解,這里完成的配置參照博客及調試。
Spark的需要修改兩個配置文件:spark-env.sh和spark-default.conf,前者需要指明Hadoop的hdfs和yarn的配置文件路徑及Spark.master.host地址,后者需要指明jar包地址;
spark-env.sh配置文件修改如下:
export JAVA_HOME=/home/stream/jdk1.8.0_144
export SCALA_HOME=/home/stream/scala-2.11.12
export HADOOP_HOME=/home/stream/hadoop-3.0.3
export HADOOP_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export YARN_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export SPARK_MASTER_HOST=xx
export SPARK_LOCAL_IP=xxx
spark-default.conf配置修改如下:
//增加jar包地址
spark.yarn.jars=hdfs://1xxx/spark_jars/*
該設置表明將jar地址定義在hdfs上,必須將~/spark/jars路徑下所有的jar包都上傳到hdfs的/spark_jars/路徑(hadoop hdfs –put ~/spark/jars/*),否則會報錯無法找到編譯jar包錯誤;
直接無參數啟動./spark-shell ,運行的是本地模式:
啟動./spark-shell –master yarn,運行的是on yarn模式,前提是yarn配置成功并可用:
在hdfs文件系統中創建文件README.md,并讀入RDD中,使用RDD自帶的參數轉換,RDD默認每行為一個值:
使用./spark-shell --master yarn啟動spark 后運行命令:val textFile=sc.textFile(“README.md”)讀取hdfs上的README.md文件到RDD,并使用內置函數測試如下,說明spark on yarn配置成功.
在啟動spark-shell時候,報錯Yarn-site.xml中配置的最大分配內存不足,調大這個值為2048M,需重啟yarn后生效。
設置的hdfs地址沖突,hdfs的配置文件中hdfs-site.xml設置沒有帶端口,但是spark-default.conf中的spark.yarn.jars值帶有端口,修改spark-default.conf的配置地址同前者一致:
在實際應用中,大數據處理主要包括以下三個類型:復雜的批量數據處理:通常時間跨度在數十分鐘到數小時之間;基于歷史數據的交互式查詢:通常時間跨度在數十秒到數分鐘之間;基于實時數據流的數據處理:通常時間跨度在數百毫秒到數秒之間;
同時存在以上場景需要同時部署多個組件,如:MapReduce/Impala/Storm,這樣做難免會帶來一些問題:不同場景之間輸入輸出數據無法做到無縫共享,通常需要進行數據格式的轉換,不同的軟件需要不同的開發和維護團隊,帶來了較高的使用成本,比較難以對同一個集群中的各個系統進行統一的資源協調和分配;
Spark的設計遵循“一個軟件棧滿足不同應用場景”的理念,逐漸形成了一套完整的生態系統,其生態系統包含了Spark Core、Spark SQL、Spark Streaming( Structured Streaming)、MLLib和GraphX 等組件,既能夠提供內存計算框架,也可以支持SQL即席查詢、實時流式計算、機器學習和圖計算等。
而且Spark可以部署在資源管理器YARN之上,提供一站式的大數據解決方案;因此,Spark所提供的生態系統足以應對上述三種場景,即批處理、交互式查詢和流數據處理。
RDD:是Resilient Distributed Dataset(彈性分布式數據集)的簡稱,是分布式內存的一個抽象概念,提供了一種高度受限的共享內存模型 ;
DAG:是Directed Acyclic Graph(有向無環圖)的簡稱,反映RDD之間的依賴關系 ;
Executor:是運行在工作節點(WorkerNode)的一個進程,負責運行Task ;
應用(Application):用戶編寫的Spark應用程序;
任務( Task ):運行在Executor上的工作單元 ;
作業( Job ):一個作業包含多個RDD及作用于相應RDD上的各種操作;
階段( Stage ):是作業的基本調度單位,一個作業會分為多組任務,每組任務被稱為階段,或者也被稱為任務集合,代表了一組關聯的、相互之間沒有Shuffle依賴關系的任務組成的任務集;
Spark運行架構包括集群資源管理器(Cluster Manager)、運行作業任務的工作節點(Worker Node)、每個應用的任務控制節點(Driver)和每個工作節點上負責具體任務的執行進程(Executor),資源管理器可以自帶或使用Mesos/YARN;
一個應用由一個Driver和若干個作業構成,一個作業由多個階段構成,一個階段由多個沒有Shuffle關系的任務組成;
當執行一個應用時,Driver會向集群管理器申請資源,啟動Executor,并向Executor發送應用程序代碼和文件,然后在Executor上執行任務,運行結束后,執行結果會返回給Driver,或者寫到HDFS或者其他數據庫中。
SparkContext對象代表了和一個集群的連接:
(1)首先為應用構建起基本的運行環境,即由Driver創建一個SparkContext,進行資源的申請、任務的分配和監控;
(2)資源管理器為Executor分配資源,并啟動Executor進程;
(3)SparkContext根據RDD的依賴關系構建DAG圖,DAG圖提交給DAGScheduler解析成Stage,然后把一個個TaskSet提交給底層調度器TaskScheduler處理;Executor向SparkContext申請Task,Task Scheduler將Task發放給Executor運行,并提供應用程序代碼;
(4)Task在Executor上運行,把執行結果反饋給TaskScheduler,然后反饋給DAGScheduler,運行完畢后寫入數據并釋放所有資源;
許多迭代式算法(比如機器學習、圖算法等)和交互式數據挖掘工具,共同之處是不同計算階段之間會重用中間結果, MapReduce框架把中間結果寫入到穩定存儲(如磁盤)中,帶來大量的數據復制、磁盤IO和序列化開銷。
RDD就是為了滿足這種需求而出現的,它提供了一個抽象的數據架構,開發者不必擔心底層數據的分布式特性,只需將具體的應用邏輯表達為一系列轉換處理,不同RDD之間的轉換操作形成依賴關系,可以實現管道化,避免中間數據存儲。一個RDD就是一個分布式對象集合,本質上是一個只讀的分區記錄集合,每個RDD可分成多個分區,每個分區就是一個數據集片段,并且一個RDD的不同分區可以被保存到集群中不同的節點上,從而可以在集群中的不同節點上進行并行計算。
RDD提供了一種高度受限的共享內存模型,即RDD是只讀的記錄分區的集合,不能直接修改,只能基于穩定的物理存儲中的數據集創建RDD,或者通過在其他RDD上執行確定的轉換操作(如map、join和group by)而創建得到新的RDD。
RDD提供了豐富的操作以支持常見數據運算,分“轉換”(Transformation)和“動作”(Action)兩種類型;RDD提供的轉換接口都非常簡單,都是類似map、filter、groupBy、join等粗粒度的數據轉換操作,而不是針對某個數據項的細粒度修改(不適合網頁爬蟲),表面上RDD的功能很受限、不夠強大,實際上RDD已經被實踐證明可以高效地表達許多框架的編程模型(比如MapReduce、SQL、Pregel);Spark用Scala語言實現了RDD的API,程序員可以通過調用API實現對RDD的各種操作
RDD典型的執行過程如下,這一系列處理稱為一個Lineage(血緣關系),即DAG拓撲排序的結果:
Spark采用RDD以后能夠實現高效計算的原因主要在于:
(1)高容錯性:血緣關系、重新計算丟失分區、無需回滾系統、重算過程在不同節點之間并行、只記錄粗粒度的操作;
(2)中間結果持久化到內存:數據在內存中的多個RDD操作之間進行傳遞,避免了不必要的讀寫磁盤開銷;
(3)存放的數據是Java對象:避免了不必要的對象序列化和反序列化;
Spark通過分析各個RDD的依賴關系生成了DAG,并根據RDD 依賴關系把一個作業分成多個階段,階段劃分的依據是窄依賴和寬依賴,窄依賴可以實現流水線優化,寬依賴包含Shuffle過程,無法實現流水線方式處理。
窄依賴表現為一個父RDD的分區對應于一個子RDD的分區或多個父RDD的分區對應于一個子RDD的分區;寬依賴則表現為存在一個父RDD的一個分區對應一個子RDD的多個分區。
邏輯上每個RDD 操作都是一個fork/join(一種用于并行執行任務的框架),把計算fork 到每個RDD 分區,完成計算后對各個分區得到的結果進行join 操作,然后fork/join下一個RDD 操作;
RDD Stage劃分:Spark通過分析各個RDD的依賴關系生成了DAG,再通過分析各個RDD中的分區之間的依賴關系來決定如何劃分Stage,具體方法:
通過上述對RDD概念、依賴關系和Stage劃分的介紹,結合之前介紹的Spark運行基本流程,總結一下RDD在Spark架構中的運行過程:
(1)創建RDD對象;
(2)SparkContext負責計算RDD之間的依賴關系,構建DAG;
(3)DAG Scheduler負責把DAG圖分解成多個Stage,每個Stage中包含了多個Task,每個Task會被TaskScheduler分發給各個WorkerNode上的Executor去執行;
RDD的創建可以從從文件系統中加載數據創建得到,或者通過并行集合(數組)創建RDD。Spark采用textFile()方法來從文件系統中加載數據創建RDD,該方法把文件的URI作為參數,這個URI可以是本地文件系統的地址,或者是分布式文件系統HDFS的地址;
從文件系統中加載數據:
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
從HDFS中加載數據:
scala> val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
可以調用SparkContext的parallelize方法,在Driver中一個已經存在的集合(數組)上創建。
scala>val array = Array(1,2,3,4,5)
scala>val rdd = sc.parallelize(array)
或者從列表中創建:
scala>val list = List(1,2,3,4,5)
scala>val rdd = sc.parallelize(list)
對于RDD而言,每一次轉換操作都會產生不同的RDD,供給下一個“轉換”使用,轉換得到的RDD是惰性求值的,也就是說,整個轉換過程只是記錄了轉換的軌跡,并不會發生真正的計算,只有遇到行動操作時,才會發生真正的計算,開始從血緣關系源頭開始,進行物理的轉換操作;
常用的RDD轉換操作,總結如下:
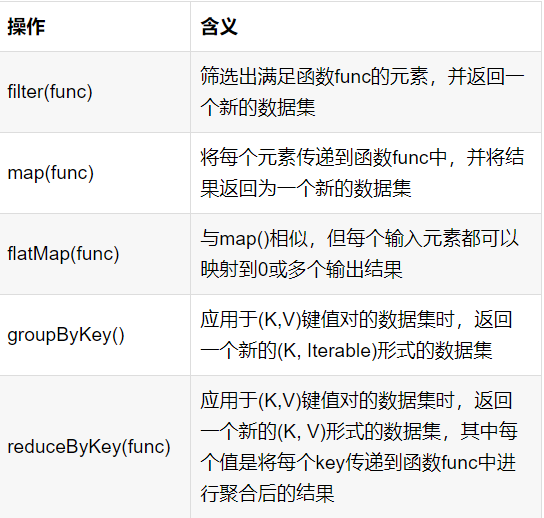 filter(func)操作:篩選出滿足函數func的元素,并返回一個新的數據集
filter(func)操作:篩選出滿足函數func的元素,并返回一個新的數據集
scala> val lines =sc.textFile(file:///usr/local/spark/mycode/rdd/word.txt)
scala> val linesWithSpark=lines.filter(line => line.contains("Spark"))
map(func)操作:map(func)操作將每個元素傳遞到函數func中,并將結果返回為一個新的數據集
scala> data=Array(1,2,3,4,5)
scala> val rdd1= sc.parallelize(data)
scala> val rdd2=rdd1.map(x=>x+10)
另一個實例:
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
scala> val words=lines.map(line => line.split(" "))
flatMap(func)操作:拍扁操作
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
scala> val words=lines.flatMap(line => line.split(" "))
groupByKey()操作:應用于(K,V)鍵值對的數據集時,返回一個新的(K, Iterable)形式的數據集;
reduceByKey(func)操作:應用于(K,V)鍵值對的數據集返回新(K, V)形式數據集,其中每個值是將每個key傳遞到函數func中進行聚合后得到的結果:
行動操作是真正觸發計算的地方。Spark程序執行到行動操作時,才會執行真正的計算,這就是惰性機制,“惰性機制”是指,整個轉換過程只是記錄了轉換的軌跡,并不會發生真正的計算,只有遇到行動操作時,才會觸發“從頭到尾”的真正的計算,常用的行動操作:
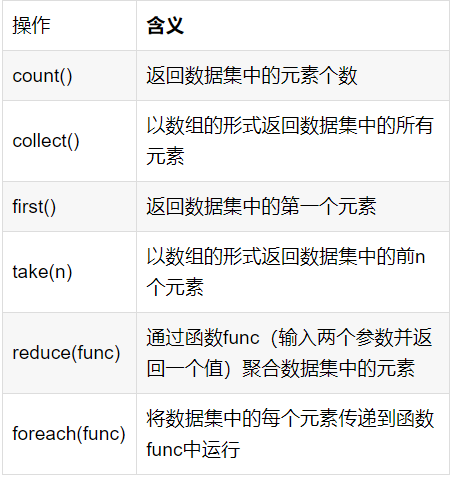
Spark RDD采用惰性求值的機制,但是每次遇到行動操作都會從頭開始執行計算,每次調用行動操作都會觸發一次從頭開始的計算,這對于迭代計算而言代價是很大的,迭代計算經常需要多次重復使用同一組數據:
scala> val list = List("Hadoop","Spark","Hive")
scala> val rdd = sc.parallelize(list)
scala> println(rdd.count()) //行動操作,觸發一次真正從頭到尾的計算
scala> println(rdd.collect().mkString(",")) //行動操作,觸發一次真正從頭到尾的計算
可以通過持久化(緩存)機制避免這種重復計算的開銷,可以使用persist()方法對一個RDD標記為持久化,之所以說“標記為持久化”,是因為出現persist()語句的地方,并不會馬上計算生成RDD并把它持久化,而是要等到遇到第一個行動操作觸發真正計算以后,才會把計算結果進行持久化,持久化后的RDD將會被保留在計算節點的內存中被后面的行動操作重復使用;
persist()的圓括號中包含的是持久化級別參數,persist(MEMORY_ONLY)表示將RDD作為反序列化的對象存儲于JVM中,如果內存不足,就要按照LRU原則替換緩存中的內容;persist(MEMORY_AND_DISK)表示將RDD作為反序列化的對象存儲在JVM中,如果內存不足,超出的分區將會被存放在硬盤上;一般而言,使用cache()方法時,會調用persist(MEMORY_ONLY),同時可以使用unpersist()方法手動地把持久化的RDD從緩存中移除。
針對上面的實例,增加持久化語句以后的執行過程如下:
scala> val list = List("Hadoop","Spark","Hive")
scala> val rdd = sc.parallelize(list)
scala> rdd.cache() //會調用persist(MEMORY_ONLY),但是,語句執行到這里,并不會緩存rdd,因為這時rdd還沒有被計算生成
scala> println(rdd.count()) //第一次行動操作,觸發一次真正從頭到尾的計算,這時上面的rdd.cache()才會被執行,把這個rdd放到緩存中
scala> println(rdd.collect().mkString(",")) //第二次行動操作,不需要觸發從頭到尾的計算,只需要重復使用上面緩存中的rdd
RDD是彈性分布式數據集,通常RDD很大,會被分成很多個分區分別保存在不同的節點上,分區的作用:(1)增加并行度(2)減少通信開銷。RDD分區原則是使得分區的個數盡量等于集群中的CPU核心(core)數目,對于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通過設置spark.default.parallelism這個參數的值,來配置默認的分區數目,一般而言:
本地模式:默認為本地機器的CPU數目,若設置了local[N],則默認為N;
Standalone或YARN:在“集群中所有CPU核心數目總和”和2二者中取較大值作為默認值;
設置分區的個數有兩種方法:創建RDD時手動指定分區個數,使用reparititon方法重新設置分區個數;
創建RDD時手動指定分區個數:在調用textFile()和parallelize()方法的時候手動指定分區個數即可,語法格式如 sc.textFile(path, partitionNum),其中path參數用于指定要加載的文件的地址,partitionNum參數用于指定分區個數。
scala> val array = Array(1,2,3,4,5)
scala> val rdd = sc.parallelize(array,2) //設置兩個分區
reparititon方法重新設置分區個數:通過轉換操作得到新 RDD 時,直接調用 repartition 方法即可,如:
scala> val data = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt",2)
scala> data.partitions.size //顯示data這個RDD的分區數量
scala> val rdd = data.repartition(1) //對data這個RDD進行重新分區
scala> rdd.partitions.size
res4: Int = 1
完成Spark部署后,使用spark-shell指令進入Scala交互編程界面,spark-shell默認創建一個sparkContext(sc),在spark-shell啟動時候可以查看運行模式是on yarn還是local模式,使用交互式界面可以直接引用sc變量使用;
使用Spark-shell處理數據實例:讀取HDFS文件系統中文件實現WordCount 單詞計數:
sc.textFile("hdfs://172.22.241.183:8020/user/spark/yzg_test.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
其中,map((_,1)) 等同于map(x => (x, 1))
使用saveAsText File()函數可以將結果保存到文件系統中。
Spark采用Scala語言編寫,在開發中需要熟悉函數式編程思想,并熟練使用Scala語言,使用Scala進行Spark開發的代碼量大大少于Java開發的代碼量;
函數式編程屬于聲明式編程的一種,將計算描述為數學函數的求值,但函數式編程沒有準確的定義,只是一系列理念,并不需要嚴格準守,可以理解為函數式編程把程序看做是數學函數,輸入的是自變量,輸出因變量,通過表達式完成計算,當前越來越多的命令式語言支持部分的函數式編程特性。
在函數式編程中,函數作為一等公民,就是說函數的行為和普通變量沒有區別,可以作為函參進行傳遞,也可以在函數內部聲明一個函數,那么外層的函數就被稱作高階函數。
函數式編程的curry化:把接受多個參數的函數變換成接受一個單一參數的函數,返回接受余下的參數并且返回結果的新函數。
函數式編程要求所有的變量都是常量(這里所用的變量這個詞并不準確,只是為了便于理解),erlang是其中的典型語言,雖然許多語言支持部分函數式編程的特性,但是并不要求變量必須是常量。這樣的特性提高了編程的復雜度,但是使代碼沒有副作用,并且帶來了很大的一個好處,那就是大大簡化了并發編程。
Java中最常用的并發模式是共享內存模型,依賴于線程與鎖,若代碼編寫不當,會發生死鎖和競爭條件,并且隨著線程數的增加,會占用大量的系統資源。在函數式編程中,因為都是常量,所以根本就不用考慮死鎖等情況。為什么說一次賦值提高了編程的復雜度,既然所有變量都是常量,那么我們沒辦法更改一個變量的值,循環的意義也就不大,所以haskell與erlang中使用遞歸代替了循環。
Scala即可伸縮的語言(Scalable Language),是一種多范式的編程語言,類似于java的編程,設計初衷是要集成面向對象編程和函數式編程的各種特性。
在Scala中函數是一等公民,像變量一樣既可以作為函參使用,也可以將函數賦值給一個變量;而且函數的創建不用依賴于類、或對象,在Java中函數的創建則要依賴于類、抽象類或者接口。Scala函數有兩種定義:
Scala的函數定義規范化寫法,最后一行代碼是它的返回值:
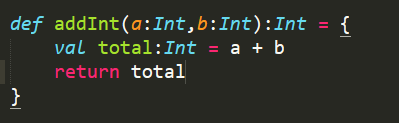
精簡后函數定義可以只有一行:

也可以直接使用val將函數定義成變量,表示定義函數addInt,輸入參數有兩個,分別為x,y,均為Int類型,返回值為兩者的和,類型Int:

Scala中的匿名函數也叫做函數字面量,既可以作為函數的參數使用,也可以將其賦值給一個變量,在匿名函數的定義中“=>”可理解為一個轉換器,它使用右側的算法,將左側的輸入數據轉換為新的輸出數據,使用匿名函數后,我們的代碼變得更簡潔了。
val test = (x:Int) => x + 1
Scala使用術語“高階函數”來表示那些把函數作為參數或函數作為返回結果的方法和函數。比如常見的有map,filter,reduce等函數,它們可以接受一個函數作為參數。
Scala中的閉包指的是當函數的變量超出它的有效作用域的時候,還能對函數內部的變量進行訪問;Scala中的閉包捕獲到的是變量的本身而不僅僅是變量的數值,當自由變量發生變化時,Scala中的閉包能夠捕獲到這個變化;如果自由變量在閉包內部發生變化,也會反映到函數外面定義的自由變量的數值。
部分應用函數只是在“已有函數”的基礎上,提供部分默認參數,未提供默認參數的地方使用下劃線替代,從而創建出一個“函數值”,在使用這個函數值(部分應用函數)的時候,只需提供下劃線部分對應的參數即可;部分應用函數本質上是一種值類型的表達式,在使用的時候不需要提供所有的參數,只需要提供部分參數。
scala中的柯里化指的是將原來接受兩個參數的函數變成新的接受一個參數的函數的過程,新的函數返回一個以原有第二個參數作為參數的函數;
def someAction(f:(Double)=>Double) = f(10)
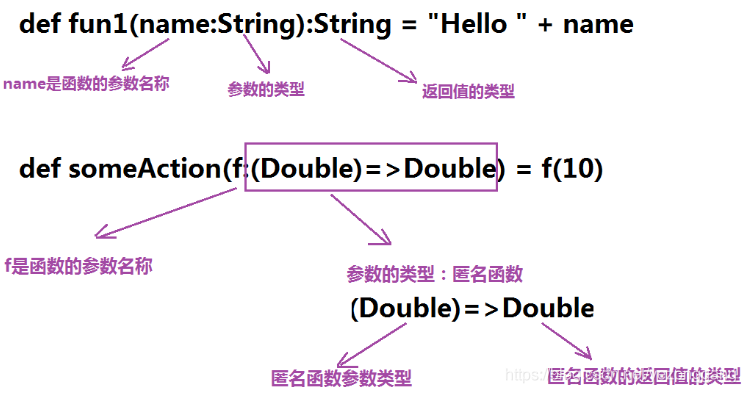
只要滿足:函數參數是一個double、返回值也是一個double,這個函數就可以作為f值;
Shark的出現,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高,但Shark的設計導致了兩個問題:
Spark SQL在Hive兼容層面僅依賴HiveQL解析、Hive元數據,也就是說,從HQL被解析成抽象語法樹(AST)起,就全部由Spark SQL接管了。Spark SQL執行計劃生成和優化都由Catalyst(函數式關系查詢優化框架)負責 ;
Spark SQL增加了DataFrame(即帶有Schema信息的RDD),使用戶可以在Spark SQL中執行SQL語句,數據既可以來自RDD,也可以是Hive、HDFS、Cassandra等外部數據源,還可以是JSON格式的數據,Spark SQL目前支持Scala、Java、Python三種語言,支持SQL-92規范 ;
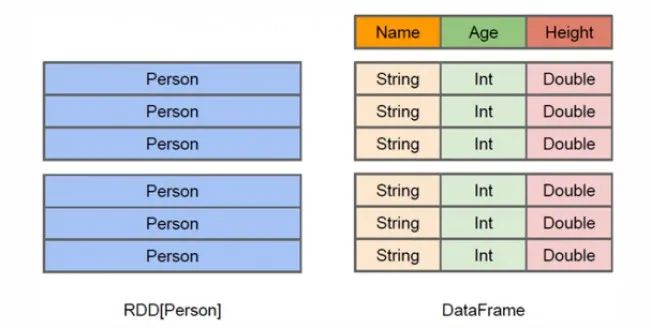 RDD是分布式的 Java對象的集合,但是,對象內部結構對于RDD而言卻是不可知的;DataFrame是一種以RDD為基礎的分布式數據集,提供了詳細的結構信息。
RDD是分布式的 Java對象的集合,但是,對象內部結構對于RDD而言卻是不可知的;DataFrame是一種以RDD為基礎的分布式數據集,提供了詳細的結構信息。RDD就像一個屋子,找東西要把這個屋子翻遍才能找到;DataFrame相當于在你的屋子里面打上了貨架,只要告訴他你是在第幾個貨架的第幾個位置, DataFrame就是在RDD基礎上加入了列,處理數據就像處理二維表一樣。
DataFrame與RDD的主要區別在于,前者帶schema元信息,即DataFrame表示的二維表數據集的每一列都帶有名稱和類型。這使得Spark SQL得以洞察更多的結構信息,從而對藏于DataFrame背后的數據源以及作用于DataFrame之上的變換進行了針對性的優化,最終達到大幅提升運行時效率的目標。反觀RDD,由于無從得知所存數據元素的具體內部結構,Spark Core只能在stage層面進行簡單、通用的流水線優化。
Spark2.0版本開始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口來實現其對數據加載、轉換、處理等功能。SparkSession實現了SQLContext及HiveContext所有功能;
SparkSession支持從不同的數據源加載數據,并把數據轉換成DataFrame,支持把DataFrame轉換成SQLContext自身中的表,然后使用SQL語句來操作數據。SparkSession亦提供了HiveQL以及其他依賴于Hive的功能的支持;可以通過如下語句創建一個SparkSession對象:
scala> import org.apache.spark.sql.SparkSession
scala> val spark=SparkSession.builder().getOrCreate()
在創建DataFrame前,為支持RDD轉換為DataFrame及后續的SQL操作,需通過import語句(即import spark.implicits._)導入相應包,啟用隱式轉換。
在創建DataFrame時,可使用spark.read操作從不同類型的文件中加載數據創建DataFrame,如:spark.read.json("people.json"):讀取people.json文件創建DataFrame;在讀取本地文件或HDFS文件時,要注意給出正確的文件路徑;spark.read.csv("people.csv"):讀取people.csv文件創建DataFrame;
讀取hdfs上的json文件,并打印,json文件為:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
讀取代碼:
import org.apache.spark.sql.SparkSession
val spark=SparkSession.builder().getOrCreate()
import spark.implicits._
val df =spark.read.json("hdfs://172.22.241.183:8020/user/spark/json_sparksql.json")
df.show()
Spark官網提供了兩種方法來實現從RDD轉換得到DataFrame:① 利用反射來推斷包含特定類型對象的RDD的schema,適用對已知數據結構的RDD轉換;② 使用編程接口,構造一個schema并將其應用在已知的RDD上;
SparkSQL 的元數據的狀態有兩種:① in_memory,用完了元數據也就丟了;② 通過hive保存,hive的元數據存在哪兒,它的元數據也就存在哪,SparkSQL數據倉庫建立在Hive之上實現的,使用SparkSQL去構建數據倉庫的時候,必須依賴于Hive。
Spark-sql命令行提供了即席查詢能力,可以使用類sql方式操作數據源,效率高于hive。
Spark Streaming是Spark Core擴展而來的一個高吞吐、高容錯的實時處理引擎,同Storm的最大區別在于無法實現毫秒級計算,而Storm可以實現毫秒級響應,Spark Streaming 實現方式是批量計算,按照時間片對stream切割形成靜態數據,并且基于RDD數據集更容易做高效的容錯處理。Spark Streaming的輸入和輸出數據源可以是多種。Spark Streaming 實時讀取數據并將數據分為小批量的batch,然后在spark引擎中處理生成批量的結果集。Spark Streaming提供了稱為離散流或DStream的高級抽象概念,它表示連續的數據流。DStreams既可以從Kafka、Flume等源的輸入數據流創建,也可以通過在其他DStreams上應用高級操作創建。在內部DStream表示為RDD序列。
在這里從一個例子開始介紹,StreamingContext是所有的流式計算的主要實體,創建含有兩個執行線程的本地StreamingContext和1秒鐘的batch,然后創建一個Dstream(lines)用于監聽TCP端口,lines中的每一行就是一個RDD,flatMap函數將一個RDD分解成多個記錄,是一對多的Dstream操作,這里使用空格將lines分解成單詞,words被映射成(word, 1)對,隨后進行詞頻統計,例子的代碼如下:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
Spark Streaming提供了稱為離散流或DStream的高級抽象,它表示連續的數據流,在內部DStream表示為RDD序列,每個RDD包含一定間隔的數據,如下圖所示:
所有對于DStream的操作都會相應地轉換成對RDDs的操作,在上面的例子中,flatMap操作被應用到lines 中的每個RDD中生成了一組RDD(即words)
總結編寫Spark Streaming程序的基本步驟是:
1.通過創建輸入DStream來定義輸入源
2.通過對DStream應用轉換操作和輸出操作來定義流計算
3.用streamingContext.start()來開始接收數據和處理流程
4.通過streamingContext.awaitTermination()方法來等待處理結束(手動結束或因為錯誤而結束)
5.可以通過streamingContext.stop()來手動結束流計算進程
有兩種創建StreamingContext的方式:通過SparkContext創建和通過SparkConf創建;
Spark conf創建:
val conf = new SparkConf().setAppName(appName).setMaster(master);
val ssc = new StreamingContext(conf, Seconds(1));
appName是用來在Spark UI上顯示的應用名稱。master是Spark、Mesos或Yarn集群的URL,或者是local[*]。batch interval可以根據你的應用程序的延遲要求以及可用的集群資源情況來設置。
SparkContext創建:
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))
在前面的例子中lines就是從源得到的輸入DStream,輸入DStream對應一個接收器對象,可以從源接收消息并存儲到Spark內存中進行處理。Spark Streaming提供兩種streaming源:
在本地運行Spark Streaming程序時,不要使用“local”或“local[1]”作為主URL。這兩者中的任何一個都意味著在本地運行任務只使用一個線程。如果使用基于receiver的輸入DStream(如Kafka、Flume等),這表明將使用單個線程運行receiver,而不留下用于處理所接收數據的線程。因此在本地運行時,始終使用“local[n]”作為主URL,其中n必須大于運行的receiver數量,否則系統將接收數據,但不能處理它。
Kafka和Flume這類源需要外部依賴包,其中一些庫具有復雜的依賴關系,Spark shell中沒有這些高級源代碼,因此無法在spark-shell中測試基于這些高級源代碼的應用程序,但可以手動將包引入;
基于可靠性的考慮,可以將數據源分為兩類:可靠的接收器的數據被Receiver 接收后發送確認到源頭(如Kafka ,Flume)并將數據存儲在spark,不可靠的接收器不會向源發送確認。
與RDD類似,轉換操作允許修改來自輸入DStream的數據,轉換操作包括無狀態轉換操作和有狀態轉換操作。
無狀態轉換操作實例:下節spark-shell中“套接字流”詞頻統計采用無狀態轉換,每次統計都只統計當前批次到達的單詞的詞頻,和之前批次無關,不會進行累計。
有狀態轉換操作實例:滑動窗口轉換操作和updateStateByKey操作;
一些常見的轉換如下:
每次窗口在源DStream上滑動,窗口內的源RDD被組合/操作生成了窗口RDD,在圖例中,過去3個時間單位的數據將被操作,并按2個時間單位滑動。
任何窗口操作都需要指定兩個參數:窗口長度:窗口的持續時間(圖中值是3);滑動間隔:執行窗口操作的間隔(圖中值是2)。這兩個參數必須是源DStream的批處理間隔的倍數(圖中值是1)
舉例說明窗口操作:希望通過每隔10秒在最近30秒數據中生成字數來擴展前面的示例。為此,我們必須在最近的30秒數據上對(word,1)的DStream鍵值對應用reduceByKey操作。這是使用reduceByKeyAndWindow操作完成的。
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
所有的滑動窗口操作都需要使用參數:windowLength(窗口長度)和slideInterval(滑動間隔),常見窗口操作總結如下,對應的含義可參照RDD的轉換操作:
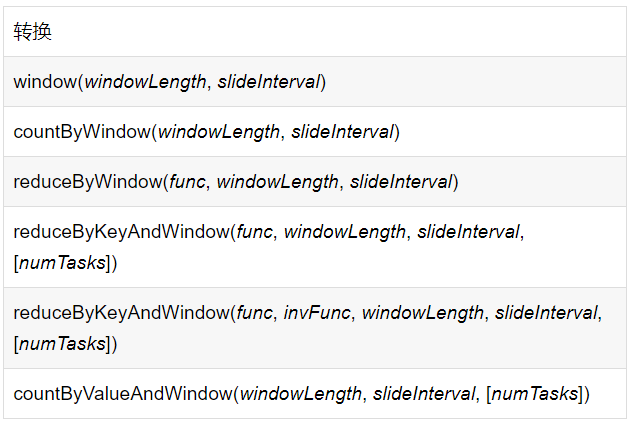
Window:基于源DStream產生的窗口化的批數據計算得到新的Dstream;
countByWindow: 返回DStream中元素的滑動窗口計數;
reduceByWindow:返回一個單元素流。利用函數func聚集滑動時間間隔的流的元素創建這個單元素流。函數func必須滿足結合律從而支持并行計算;
reduceByKeyAndWindow(三參數):應用到一個(K,V)鍵值對組成的DStream上時,會返回一個由(K,V)鍵值對組成的新的DStream。每一個key的值均由給定的reduce函數(func函數)進行聚合計算。注意:在默認情況下,這個算子利用了Spark默認的并發任務數去分組。可以通過numTasks參數的設置來指定不同的任務數;
reduceByKeyAndWindow(四參數):比上述reduceByKeyAndWindow(三參數)更高效的reduceByKeyAndWindow,每個窗口的reduce值是基于先前窗口的reduce值進行增量計算得到的;它會對進入滑動窗口的新數據進行reduce操作,并對離開窗口的老數據進行“逆向reduce”操作。但是,只能用于“可逆reduce函數”,即那些reduce函數都有一個對應的“逆向reduce函數”(以InvFunc參數傳入)。
countByValueAndWindow:當應用到一個(K,V)鍵值對組成的DStream上,返回一個由(K,V)鍵值對組成的新的DStream。每個key的值都是它們在滑動窗口中出現的頻率。
updateStateByKey:需要在跨批次之間維護狀態時,必須使用updateStateByKey操作;
窗口計算上join操作非常有用,在Spark Streaming中可以輕松實現不同類型的join,包括leftouterjoin、rightouterjoin和fulloterjoin。每個批處理間隔中stream1生成的RDD與stream2生成的RDD關聯如下:
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
輸出操作允許將DStream的數據推送到外部系統,如數據庫或files,由于輸出操作觸發所有DStream轉換的實際執行(類似于RDD的操作),并允許外部系統使用轉換后的數據,輸出操作有以下幾種:

在輸出DStream中,Dstream.foreachRDD是一個功能強大的原語.
可以輕松地對流數據使用DataFrames和SQL操作,但必須使用StreamingContext正在用的SparkContext創建SparkSession。下面例子使用DataFrames和SQL生成單詞計數。每個RDD都轉換為DataFrame,注冊為臨時表后使用SQL進行查詢:
val words: DStream[String] =
words.foreachRDD { rdd =>
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val wordsDataFrame = rdd.toDF("word")
wordsDataFrame.createOrReplaceTempView("words")
val wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
進入spark-shell后就默認獲得了的SparkConext,即sc,從SparkConf對象創建StreamingContext對象,spark-shell中創建StreamingContext對象如下:
scala> import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(1))
如果是編寫一個獨立的Spark Streaming程序,而不是在spark-shell中運行,則需要通過如下方式創建StreamingContext對象:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
文件流可以讀取本機文件,也可以讀取讀取HDFS上文件,如果部署的on yarn模式的Spark,則啟動spark-shell默認讀取HDFS上對應的: hdfs:xxxx/user/xx/ 下的文件;
scala> import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(5))
scala> val lines = ssc.textFileStream("hdfs://xxx/yzg_test.txt")
scala> val Counts = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
scala> Counts.saveAsTextFiles("hdfs://xxx/bendi"))
scala> ssc.start()
scala> ssc.awaitTermination()
scala> ssc.stop()
以上代碼在spark-shell中運行后,每隔5秒讀取hdfs上的文件并進行詞頻統計后寫入到hdfs中的“bendi-時間戳”文件夾下,直到ssc.stop();Counts.saveAsTextFiles("file://xxx/bendi"))和Counts.print分別寫本地和std輸出;
Spark Streaming可以通過Socket端口實時監聽并接收數據計算,步驟如下:
driver端創建StreamingContext對象,啟動上下文時依次創建JobScheduler和ReceiverTracker,并調用他們的start方法。ReceiverTracker在start方法中發送啟動接收器消息給遠程Executor,消息內部含有ServerSocket的地址信息。在executor一側,由Receiver TrackerEndpoint終端接受消息,抽取消息內容,利用sparkContext結合消息內容創建ReceiverRDD對象,最后提交rdd給spark集群。在代碼實現上,使用nc –lk 9999 開啟 地址172.22.241.184主機的9999監聽端口,并持續往里面寫數據;使用spark-shell實現監聽端口代碼如下,輸入源為socket源,進行簡單的詞頻統計后,統計結果輸出到HDFS文件系統;
scala> import org.apache.spark._
scala> import org.apache.spark.streaming._
scala> import org.apache.spark.storage.StorageLevel
scala> val ssc = new StreamingContext(sc, Seconds(5))
scala> val lines = ssc.socketTextStream("172.22.241.184", 9999, StorageLevel.MEMORY_AND_DISK_SER)
scala> val wordCounts = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
scala> wordCounts.saveAsTextFiles("hdfs://xxx/bendi-socket"))
scala> ssc.start()
scala> ssc.awaitTermination()
scala> ssc.stop()
Kafka和Flume等高級輸入源需要依賴獨立的庫(jar文件),如果使用spark-shell讀取kafka等高級輸入源,需要將對應的依賴jar包放在spark的依賴文件夾lib下。
根據當前使用的kafka版本,適配所需要的spark-streaming-kafka依賴的版本,在maven倉庫下載,地址如下:https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka_2.10/1.2.1
將對應的依賴jar包放在CDH的spark的依賴文件夾lib下,通過引入包內依賴驗證是否成功:
scala> import org.apache.spark._
scala> import org.apache.spark.streaming._
scala> import org.apache.spark.streaming.kafka._
scala> val ssc = new StreamingContext(sc, Seconds(5))
scala> ssc.checkpoint("hdfs://usr/spark/kafka/checkpoint")
scala> val zkQuorum = "172.22.241.186:2181"
scala> val group = "test-consumer-group"
scala> val topics = "yzg_spark"
scala> val numThreads = 1
scala> val topicMap =topics.split(",").map((_,numThreads.toInt)).toMap
scala> val lineMap = KafkaUtils.createStream(ssc,zkQuorum,group,topicMap)
scala> val pair = lineMap.map(_._2).flatMap(_.split(" ")).map((_,1))
scala> val wordCounts = pair.reduceByKeyAndWindow(_ + _,_ -_,Minutes(2),Seconds(10),2)
scala> wordCounts.print
scala> ssc.start
當Spark Streaming需要跨批次間維護狀態時,就必須使用updateStateByKey操作。以詞頻統計為例,對于有狀態轉換操作而言,當前批次的詞頻統計是在之前批次的詞頻統計結果的基礎上進行不斷累加,所以最終統計得到的詞頻是所有批次的單詞總的詞頻統計結果。
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
實現:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint("hdfs:172.22.241.184:8020//usr/spark/checkpoint")
val lines = ssc.socketTextStream("172.22.241.184", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val wordCounts = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey[Int](updateFunc)
wordCounts.saveAsTextFiles("hdfs:172.22.241.184:8020//user/spark/bendi-socket")
ssc.start()
ssc.awaitTermination()
ssc.stop()
關于SparkStreaming實時計算框架實時地讀取kafka中的數據然后進行計算,在spark1.3版本后kafkaUtils提供兩種Dstream創建方法,一種為KafkaUtils.createDstream,另一種為KafkaUtils.createDirectStream。
KafkaUtils.createDstream方式
其構造函數為KafkaUtils.createDstream(ssc,[zk], [consumer group id], [per-topic,partitions] ),使用receivers來接收數據,利用的是Kafka高層次的消費者api,對于所有的receivers接收到的數據將會保存在Spark executors中,然后通過Spark Streaming啟動job來處理這些數據,默認會丟失,可啟用WAL日志,它同步將接受到數據保存到分布式文件系統上比如HDFS。所以數據在出錯的情況下可以恢復出來。
A、創建一個receiver來對kafka進行定時拉取數據,ssc的RDD分區和Kafka的topic分區不是一個概念,故如果增加特定主消費的線程數僅僅是增加一個receiver中消費topic的線程數,并不增加spark的并行處理數據數量。
B、對于不同的group和topic可以使用多個receivers創建不同的DStream
C、如果啟用了WAL(spark.streaming.receiver.writeAheadLog.enable=true)
同時需要設置存儲級別(默認StorageLevel.MEMORY_AND_DISK_SER_2),即KafkaUtils.createStream(….,StorageLevel.MEMORY_AND_DISK_SER)
KafkaUtils.createDirectStream方式
在spark1.3之后,引入了Direct方式,不同于Receiver的方式,Direct方式沒有receiver這一層,其會周期性的獲取Kafka中每個topic的每個partition中的最新offsets,之后根據設定的maxRatePerPartition來處理每個batch。
這種方法相較于Receiver方式的優勢在于:
簡化的并行:在Receiver的方式中我們提到創建多個Receiver之后利用union來合并成一個Dstream的方式提高數據傳輸并行度。而在Direct方式中,Kafka中的partition與RDD中的partition是一一對應的并行讀取Kafka數據,這種映射關系也更利于理解和優化。
高效:在Receiver的方式中,為了達到0數據丟失需要將數據存入Write Ahead Log中,這樣在Kafka和日志中就保存了兩份數據,浪費!而第二種方式不存在這個問題,只要我們Kafka的數據保留時間足夠長,我們都能夠從Kafka進行數據恢復。
精確一次:在Receiver的方式中,使用的是Kafka的高階API接口從Zookeeper中獲取offset值,這也是傳統的從Kafka中讀取數據的方式,但由于Spark Streaming消費的數據和Zookeeper中記錄的offset不同步,這種方式偶爾會造成數據重復消費。而第二種方式,直接使用了簡單的低階Kafka API,Offsets則利用Spark Streaming的checkpoints進行記錄,消除了這種不一致性。
此方法缺點是它不會更新Zookeeper中的偏移量,因此基于Zookeeper的Kafka監視工具將不會顯示進度。但是您可以在每個批處理中訪問此方法處理的偏移量,并自行更新Zookeeper。
參照官方的API文檔地址:http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html,位置策略是用來控制特定的主題分區在哪個執行器上消費的,在executor針對主題分區如何對消費者進行調度,并且位置的選擇是相對的,位置策略有三種方案:
1、PreferBrokers:首選kafka服務器,只有在kafka服務器和executor位于同一主機可以使用該策略。
2、PreferConsistent:首選一致性,多數時候采用該方式,在所有可用的執行器上均勻分配kakfa的主題的所有分區,能夠綜合利用集群的計算資源。
3、PreferFixed:首選固定模式,如果負載不均衡可以使用該策略放置在特定節點使用指定的主題分區;該配置是手動控制方案,若沒有顯式指定的分區仍然采用(2)方案。
消費者策略是控制如何創建和配制消費者對象或者如何對Kafka上的消息進行消費界定,比如t1主題的分區0和1,或者消費特定分區上的特定消息段。該類可擴展,自行實現。
1、ConsumerStrategies.Assign:指定固定的分區集合;
def Assign[K, V](
topicPartitions: Iterable[TopicPartition],
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long])
2、ConsumerStrategies.Subscribe:允許消費訂閱固定的主題集合;
3、ConsumerStrategies.SubscribePattern:使用正則表達式指定感興趣的主題集合。
IDEA作為常用的開發工具使用maven進行依賴包的統一管理,配置Scala的開發環境,進行Spark Streaming的API開發;
下載并破解IDEA,并加入漢化的包到lib,重啟生效;
在IDEA中導入離線的Scala插件:需要確保當前win主機上已經下載安裝Scala并設置環境變量,首先下載IDEA的Scala插件,無須解壓,然后將其添加到IDEA中,具體為new---setting--plugins--"輸入scala"--install plugin from disk;
shift鍵多次------查找類和插件;
shift+ctrl+enter-------結束當前行,自動補全分號;
shift+alter+s-----------setting設置
alter+enter-----------補全拋出的異常
alter+insert---------自動生成get、set、構造函數等;
Ctrl+X --------------刪除當前行
ctrl+r----------------替換
ctrl+/----------------多行代碼分行注釋,每行一個注釋符號
ctrl+shift+/---------多行代碼注釋在一個塊里,只在開頭和結尾有注釋符號
新建maven工程:file--new--project--maven(選擇quickstart框架模型新建),groupId和ArtifactID用來區分該java工程;
maven自動生成pom.xml配置文件,用于各種包的依賴和引入,如果使用maven打包,需要引入maven的打包插件:使用maven-compiler-plugin、maven-jar-plugin插件,并在prom.xml中增加指定程序入口的
將mainClass設置為HelloWorld(主類),點擊右邊窗口maven -> package,生成jar包,打包完成后使用spark-submit指令提交jar包并執行。
spark-submit --class "JSONRead" /usr/local/spark/mycode/json/target/scala-2.11/json-project_2.11-1.0.jar
若有cannot find main class錯誤,需要刪除-class xx.jar選項;若出現“Invalid signature file digest for Manifest main”錯誤,則運行zip -d xxx.jar 'META-INF/.SF' 'META-INF/.RSA' 'META-INF/*SF' 指令,刪除所屬jar包中.SF/.RSA/相關文件。任務yarn管理器查看任務運行情況;
在Spark2.x中,spark新開放了一個基于DataFrame的無下限的流式處理組件Structured Streaming,在過去使用streaming時一次處理是當前batch的所有數據,針對這波數據進行各種處理,如果要做一些類似pv,uv的統計,需要借助有狀態的state的DStream,或者借助一些分布式緩存系統,如Redis,做一些類似Group by的操作Streaming是非常不便的,在面對復雜的流式處理場景時捉襟見肘,且無法支持基于event_time的時間窗口做聚合邏輯。
在Structured Streaming中,把源源不斷到來的數據通過固定的模式“追加”或者“更新”到無下限的DataFrame中。剩余的工作跟普通的DataFrame一樣,可以去map、filter,也可以去groupby().count(),甚至還可以把流處理的dataframe跟其他的“靜態”DataFrame進行join。另外,還提供了基于window時間的流式處理。總之,Structured Streaming提供了快速、可擴展、高可用、高可靠的流式處理。
Structured Streaming構建于sparksql引擎之上,可以用處理靜態數據的方式去處理你的流計算,隨著流數據的不斷流入,Sparksql引擎會增量的連續不斷的處理并且更新結果。可以使用DataSet/DataFrame的API進行 streaming aggregations, event-time windows, stream-to-batch joins等,計算的執行也是基于優化后的sparksql引擎。通過checkpointing and Write Ahead Logs該系統可以保證點對點,一次處理,容錯擔保。
到此,相信大家對“Spark的基礎知識點有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





