溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Kubernetes中彈性伸縮最常用組件HPA的原理與演進是怎樣的,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
今天會為大家介紹在 Kubernetes 中彈性伸縮最常用的組件 HPA(Horizontal Pod Autoscaler)。HPA 是通過計算 Pod 的實際工作負載進行重新容量規劃的組件,在資源池符合滿足條件的前提下,HPA 可以很好的實現彈性伸縮的模型。HPA 到目前為止,已經演進了三個大版本,本文將會為大家詳細解析 HPA 底層的原理以及在 Kubernetes 中彈性伸縮概念的演變歷程。
HPA 是根據實際工作負載水平伸縮容器數目的組件,從中可以提煉出兩個非常重要的關鍵字:負載和數目。我們可以用一個非常簡單的數學公式進行歸納: 下面舉一個實際例子進行上述公式的闡述。 假設存在一個叫
下面舉一個實際例子進行上述公式的闡述。 假設存在一個叫 A 的 Deployment,包含3個 Pod,每個副本的 Request 值是 1 核,當前 3 個 Pod 的 CPU 利用率分別是 60%、70% 與 80%,此時我們設置 HPA 閾值為 50%,最小副本為 3,最大副本為 10。接下來我們將上述的數據帶入公式中:
總的 Pod 的利用率是 60%+70%+80% = 210%;
當前的 Target 是 3;
算式的結果是 70%,大于50%閾值,因此當前的 Target 數目過小,需要進行擴容;
重新設置 Target 值為 5,此時算式的結果為 42% 低于 50%,判斷還需要擴容兩個容器;
此時 HPA 設置 Replicas 為 5,進行 Pod 的水平擴容。
經過上面的推演,可以協助開發者快速理解 HPA 最核心的原理,不過上面的推演結果和實際情況下是有所出入的,如果開發者進行試驗的話,會發現 Replicas 最終的結果是 6 而不是 5。這是由于 HPA 中一些細節的處理導致的,主要包含如下三個主要的方面:
噪聲處理
通過上面的公式可以發現,Target 的數目很大程度上會影響最終的結果,而在 Kubernetes 中,無論是變更或者升級,都更傾向于使用 Recreate 而不是 Restart 的方式進行處理。這就導致了在 Deployment 的生命周期中,可能會出現某一個時間,Target 會由于計算了 Starting 或者 Stopping 的 Pod 而變得很大。這就會給 HPA 的計算帶來非常大的噪聲,在 HPA Controller 的計算中,如果發現當前的對象存在 Starting 或者 Stopping 的 Pod 會直接跳過當前的計算周期,等待狀態都變為 Running 再進行計算。
冷卻周期
在彈性伸縮中,冷卻周期是不能逃避的一個話題,很多時候我們期望快速彈出與快速回收,而另一方面,我們又不希望集群震蕩,所以一個彈性伸縮活動冷卻周期的具體數值是多少,一直被開發者所挑戰。在 HPA 中,默認的擴容冷卻周期是 3 分鐘,縮容冷卻周期是 5 分鐘。
邊界值計算
我們回到剛才的計算公式,第一次我們算出需要彈出的容器數目是 5,此時擴容后整體的負載是 42%,但是我們似乎忽略了一個問題:一個全新的 Pod 啟動會不會自己就占用了部分資源?此外,8% 的緩沖區是否就能夠緩解整體的負載情況?要知道當一次彈性擴容完成后,下一次擴容要最少等待 3 分鐘才可以繼續擴容。為了解決這些問題,HPA 引入了邊界值 △,目前在計算邊界條件時,會自動加入 10% 的緩沖,這也是為什么在剛才的例子中最終的計算結果為 6 的原因。
在了解了 HPA 的基本原理后,我們來聊一下 HPA 的演進歷程,目前 HPA 已經支持了 autoscaling/v1、autoscaling/v1beta1 和 autoscaling/v1beta2 三個大版本。大部分的開發者目前比較熟悉的是autoscaling/v1 的版本,這個版本的特點是只支持 CPU 一個指標的彈性伸縮,大致的 yaml 內容如下:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: php-apache namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 50
接下來我們再來看一下 v2beta1 與 v2beta2 的 yaml,會發現里面支持的 metrics 類型增加了很多,結構也復雜了很多。
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: php-apache namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: kind: AverageUtilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second targetAverageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: extensions/v1beta1 kind: Ingress name: main-route target: kind: Value value: 10k --- apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: php-apache namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50
而這些變化的產生不得不提的是 Kubernetes 社區中對監控與監控指標的認識與轉變。在 Kubernetes 中,有兩個核心的監控組件 Heapster 與 Metrics Server。Heapster 是早期 Kubernetes 社區中唯一的監控組件,它所包含的功能很強大,通過采集 kubelet 提供的 metrics 接口,并支持監控數據的離線與歸檔。
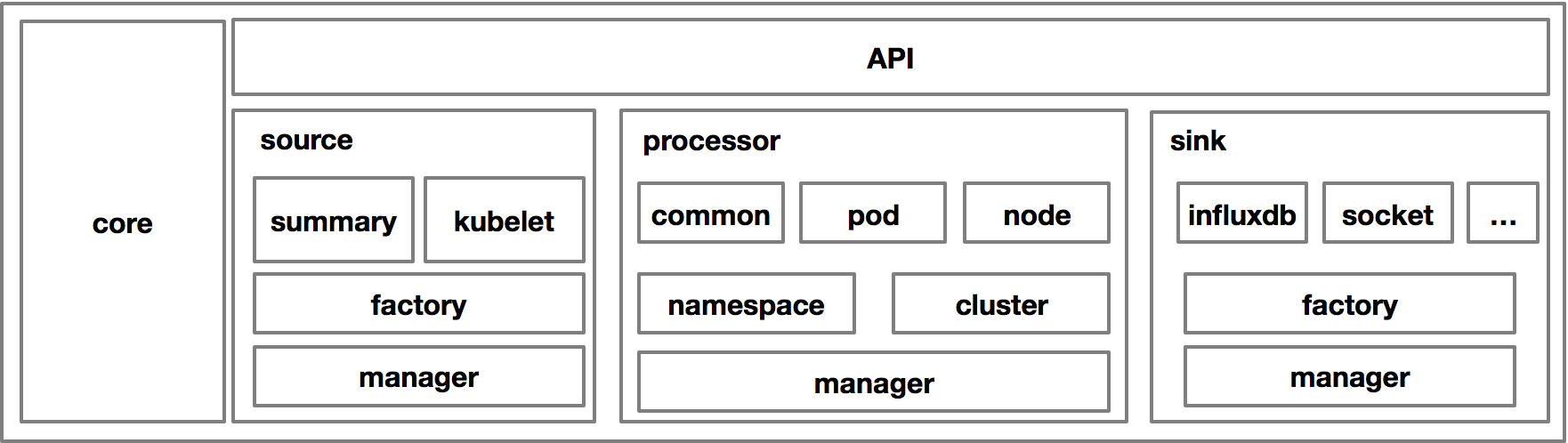
大致的架構圖如上:source 的部分是不同的數據來源,主要是 kubelet 的 common api 與后來提供的 summary api;processor 的作用是將采集的數據進行處理,分別在 namespace 級別、cluster 級別進行聚合,并創建新的聚合類型的監控數據;sink 的作用是數據離線與歸檔,常見的歸檔方式包括 influxdb、kafka 等等。Heapster 組件在相當長時間成為了 Kubernetes 社區中監控數據的唯一來源,也因此有非常多的和監控相關的組件通過 Heapster 的鏈路進行監控數據的消費。但是后來,Kubernetes 社區發現了 Heapster 存在非常嚴重的幾個問題:
強大繁多的 Sink 由不同的 Maintainer 進行維護,50% 以上的 Heapster Issues 都是關于 Sink 無法使用的,而由于 Maintainer 的活躍度不同造成 Heapster 社區有大量的 issues 無法解決;
對于開發者而言,監控數據的類型已經不再是 CPU、Memory 這么簡單的幾個指標項了,越來越多的開發者需要應用內或者接入層的監控指標,例如 ingress 的 QPS、應用的在線活躍人數等等。而這些指標的獲取是 Heapster 無法實現的;
Prometheus 的成熟讓 Heapster 的生存空間不斷被擠壓,自從 Prometheus 被 CNCF 收錄為孵化項目,Heapster 的不可替代地位被正式移除。
社區經過反思后,決定將監控的指標邊界進行劃分,分為 Resource、Custom 和 External 三種不同的 Metrics,而 Heapster(Metrics Server) 的定位就只關心 Resource 這一種指標類型。為了解決代碼維護性的問題,Metrics Server 對 Heapster 進行了裁剪,裁剪后的架構如下:
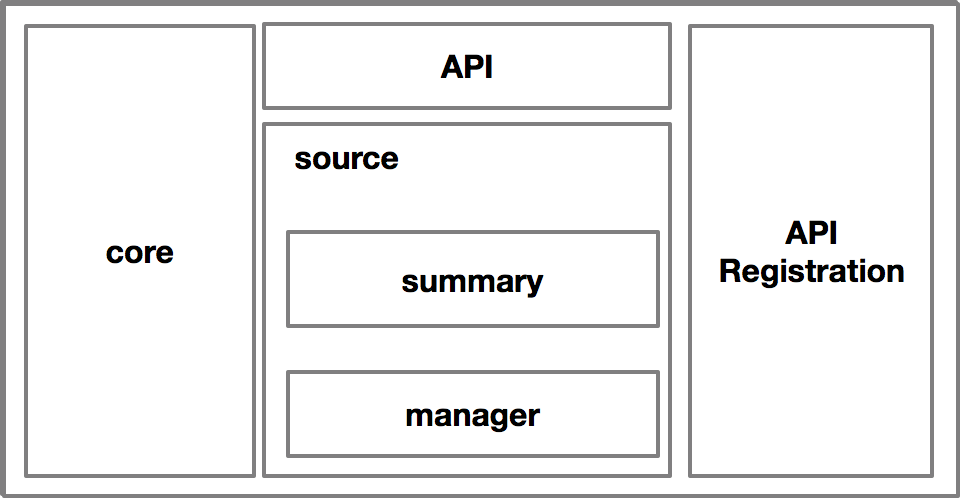
去掉了 Sink 的機制,并將調用方式改為標準的 API 注冊的方式,這樣的好處是既精簡了核心代碼的邏輯又提供了替代的可能,也就是說此時 Metrics Server 也是可以替代的,只要實現了相同的 API 接口,并注冊到 API Server 上,就可以替代 Metrics Server。
接下來我們解析一下三種不同的 Metrics 與使用的場景:
| API | 注釋 | |
|---|---|---|
| Resource | metrics.k8s.io | Pod的資源指標,計算的時要除以Pod數目再對比閾值進行判斷 |
| Custom | custom.metrics.k8s.io | Object: CRD等對象的監控指標,直接計算指標比對閾值<br />Pods : 每個Pod的自定義指標,計算時要除以Pods的數目 |
| External | external.metrics.k8s.io | External:集群指標的監控指標,通常由云廠商實現 |
其中 autoscaling/v2beta1 支持 Resource 與 Custom 兩種指標,而 autoscaling/v2beta2 中增加了 External 的指標的支持。
HPA 目前已經進入了 GA 階段,在大體的功能上面不會進行過多的變化,目前社區的主要發力點在如何配置化的調整細節參數、豐富監控 adapter 的實現等等。
上述就是小編為大家分享的Kubernetes中彈性伸縮最常用組件HPA的原理與演進是怎樣的了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





