溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關在TKE中如何利用 HPA 實現業務的彈性伸縮,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Kubernetes Pod 水平自動擴縮(Horizontal Pod Autoscaler,以下簡稱 HPA)可以基于 CPU 利用率、內存利用率和其他自定義的度量指標自動擴縮 Pod 的副本數量,以使得工作負載服務的整體度量水平與用戶所設定的目標值匹配。本文將介紹和使用騰訊云容器服務 TKE 的 HPA 功能實現 Pod 自動水平擴縮容。
HPA 自動伸縮特性使容器服務具有非常靈活的自適應能力,能夠在用戶設定內快速擴容多個 Pod 副本來應對業務負載的急劇飆升,也可以在業務負載變小的情況下根據實際情況適當縮容來節省計算資源給其他的服務,整個過程自動化無須人為干預,非常適合服務波動較大,服務數量多且需要頻繁擴縮容的業務場景,如:電商服務、線上教育、金融服務等。
Pod 水平自動擴縮特性由 Kubernetes API 資源和控制器實現。資源利用指標決定控制器的行為, 控制器會周期性的根據 Pod 資源利用情況調整服務 Pod 的副本數量,以使得工作負載的度量水平與用戶所設定的目標值匹配。其擴縮容流程和說明如下:
提示:目前這一功能處于 beta 版本,且 Pod 自動水平擴縮不適用于無法擴縮的對象,比如 DaemonSet 資源。
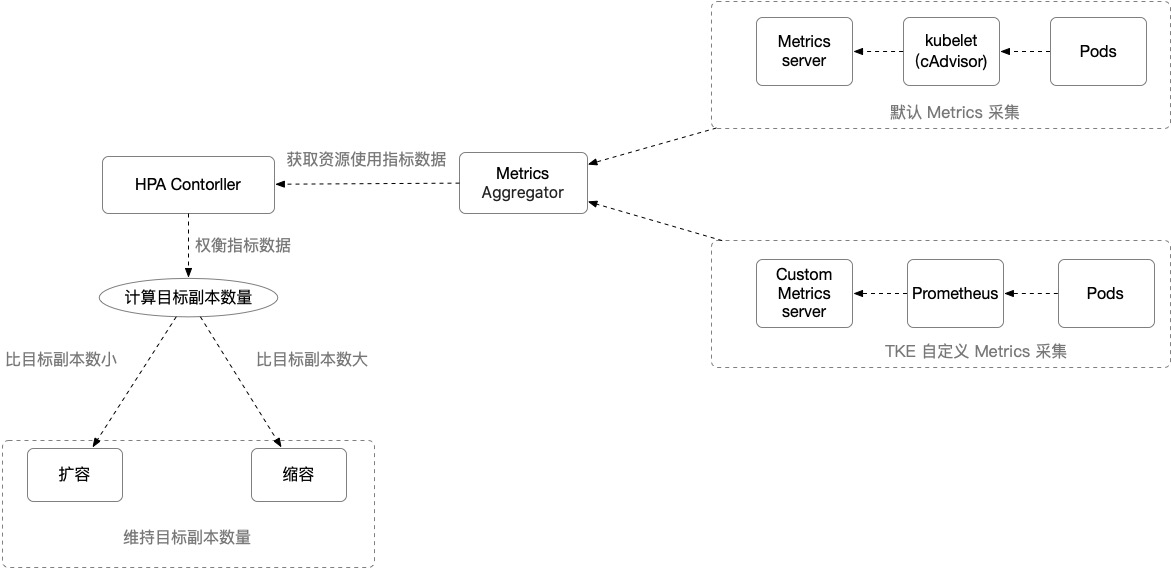
HPA Controller:控制 HPA 擴縮邏輯的控制組件。
Metrics Aggregator:度量指標聚合器。通常情況下,控制器將從一系列的聚合 API(metrics.k8s.io、custom.metrics.k8s.io 和 external.metrics.k8s.io)中獲取度量值。 metrics.k8s.io API 通常由 Metrics 服務器提供,社區版可提供基本的 CPU、內存度量類型,相比于社區版,TKE 使用自定義 Metrics Server 采集可支持更廣泛的的 HPA 的度量指標觸發類型,提供包括 CPU 、內存、硬盤、網絡和 GPU 相關指標,了解更多詳細內容參閱 TKE 自動伸縮指標說明。
提示:控制器也可以直接從 Heapster 獲取指標。但自 Kubernetes 1.11 起,從 Heapster 獲取指標特性的方式已廢棄。
HPA 計算目標副本數算法:TKE HPA 擴縮容算法請參考 工作原理,更多詳細算法請參閱 算法細節。
已 注冊騰訊云賬戶。
已登錄 騰訊云容器服務控制臺。
已創建 TKE 集群。關于創建集群,詳情請參見 創建集群。
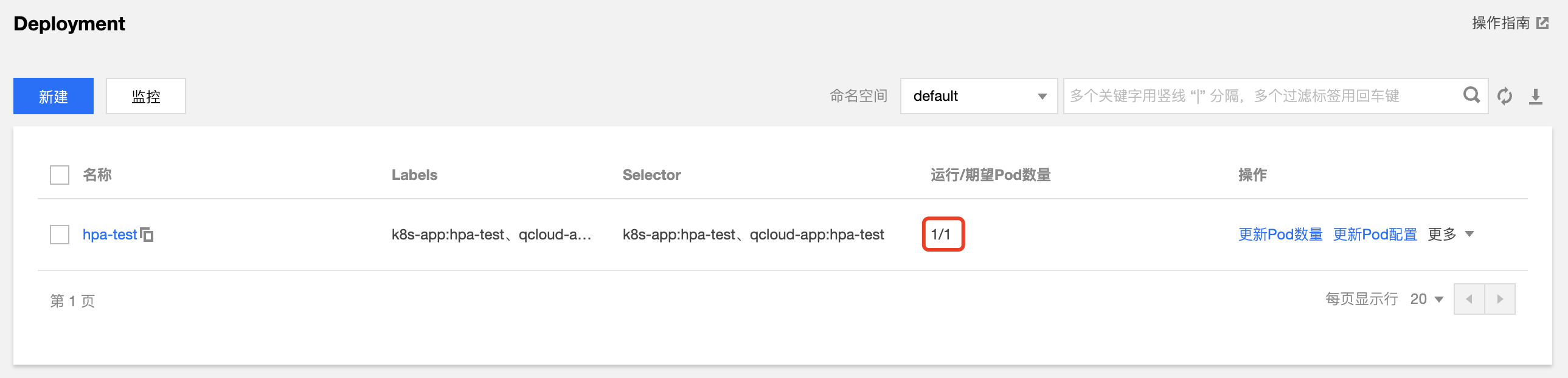
第 1 步:部署測試工作負載
以 Deployment 資源類型的工作負載為例,創建一個單副本數,服務類型為 WEB 服務的 "hpa-test" 工作負載,在 TKE 控制臺創建Deployment 類型工作負載方法請參閱 Deployment 管理。本示例創建結果如下圖所示:
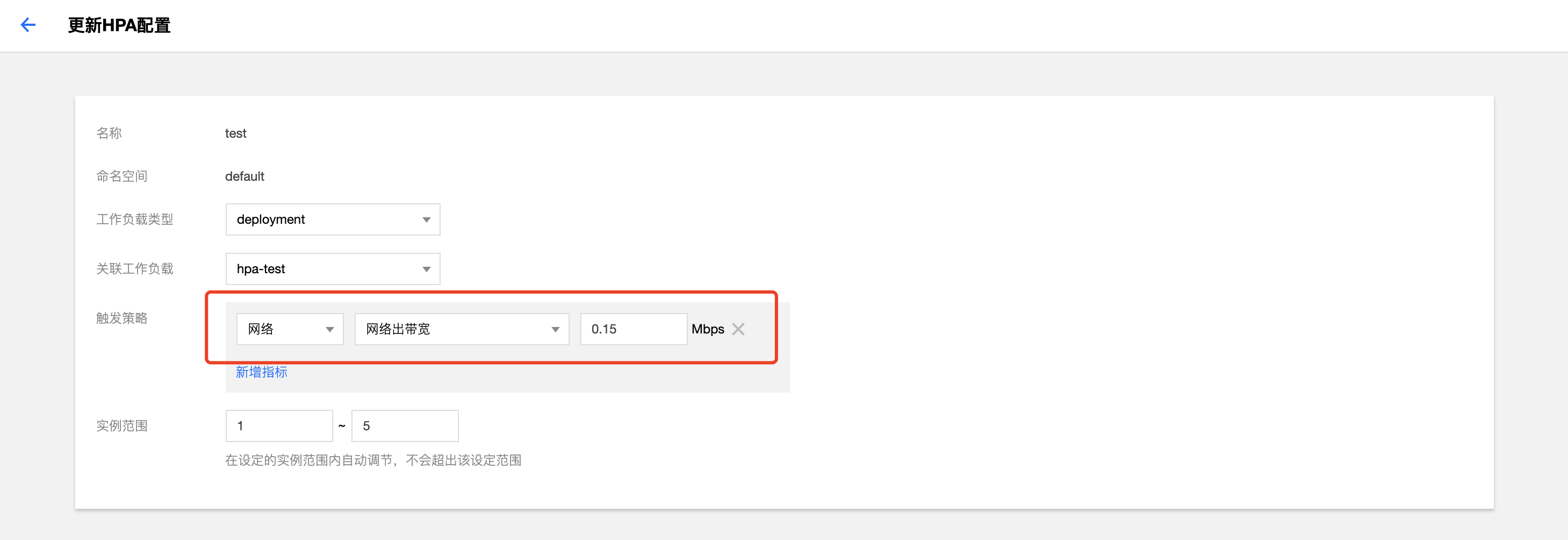
第 2 步:配置 HPA
在 TKE 控制臺為測試工作負載綁定一個 HPA 配置,關于如何綁定配置 HPA 請參閱 HPA 操作步驟 ,本示例配置當網絡出帶寬達到0.15Mbps(150Kbps) 時觸發擴容的策略。
第 3 步:功能驗證
在集群中啟動一個臨時 Pod 對配置的 HPA 功能進行測試(模擬客戶端):
kubectl run -it --image alpine hpa-test --restart=Never --rm /bin/sh
在臨時 Pod 中運行下面命令短時間內模擬大量請求訪問 "hpa-test" 服務使出口流量帶寬增大:
# hpa-test.default.svc.cluster.local 為服務在集群中的域名,當需要停止腳本時按 Ctrl+C 即可 while true; do wget -q -O - hpa-test.default.svc.cluster.local; done
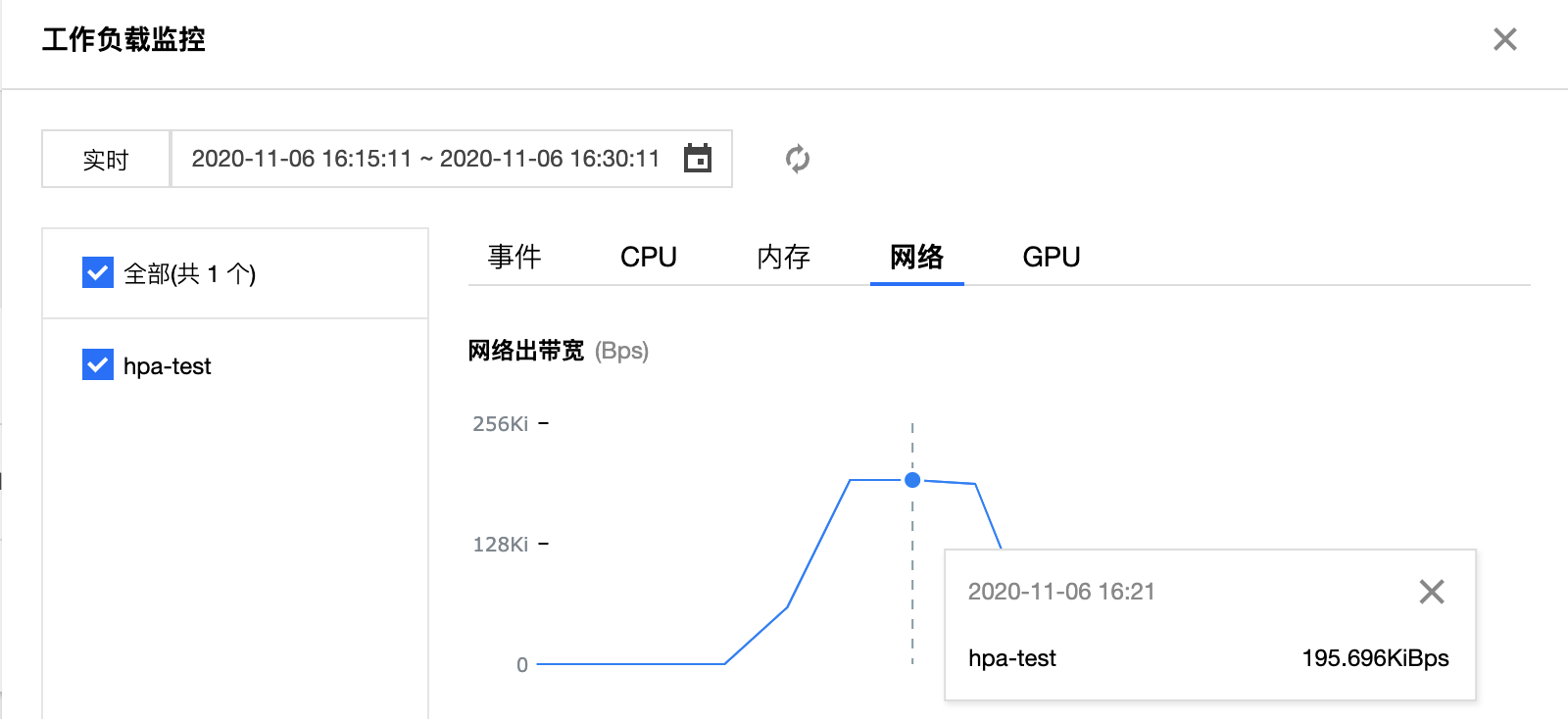
在測試 Pod 中執行模擬請求命令后,通過觀察下圖中工作負載的 Pod 數量監控可以看到,在 16:21 分時工作負載擴容副本數量至 2 個,由此可推斷出已經觸發了 HPA 的擴容事件。

再通過下圖的工作負載的網絡出口帶寬監控可以看出在 16:21 右左時網絡出口帶寬增至大概 199 Kbps,已經超過 HPA 設定的網絡出口帶寬目標值,進一步證明此時觸發 HPA 擴縮容算法 擴容了一個副本數來滿足設定的目標值,故工作負載的副本數量變成了 2 個。
注意:HPA 擴縮容算法 不只以公式計算維度去控制擴縮容邏輯,而會多維度去衡量是否需要擴容或縮容,詳情可以參閱 算法細節,所以在實際情況中可能和預期會稍有偏差。
接下來模擬縮容過程,在 16:24 左右手動停止執行模擬請求的命令, 從下圖監控看到此時網絡出口帶寬值下降到擴容前位置,按照 HPA 的邏輯,此時已經滿足工作負載縮容的條件。

但從下圖工作負載的 Pod 數量監控可以看出,工作負載在 16:30 分時才觸發了 HPA 的縮容,這是因為觸發了 HPA 縮容有默認 5 分鐘的容忍時間的算法,以防止度量指標短時間波動導致的頻繁的擴縮容,詳情請參閱 冷卻/延遲支持。從下圖可以看出工作負載副本數在停止命令 5 分鐘后按照 HPA 擴縮容算法 縮容到了最初設定的 1 個副本數。

當 TKE 發生 HPA 擴縮容事件時,會在對應的 HPA 實例的事件列表展示,如下圖所示。需要注意的是事件通知列表的時間分為 “首次出現時間” 和 “最后出現時間”,“首次出現時間” 表示相同事件第一次出現的時間,”最后出現時間” 為相同事件出現的最新時間,所以從下圖事件列表 “最后出現時間” 字段可以看到本示例擴容事件時間點是16:21:03,縮容事件時間是16.29:42,時間點與工作負載監控看到的時間點相吻合。
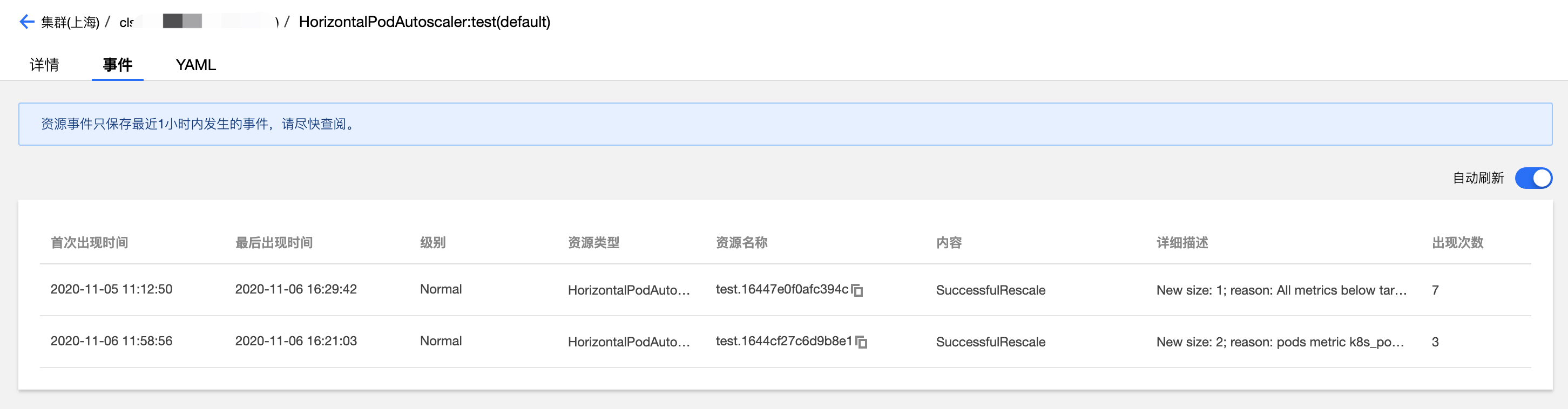
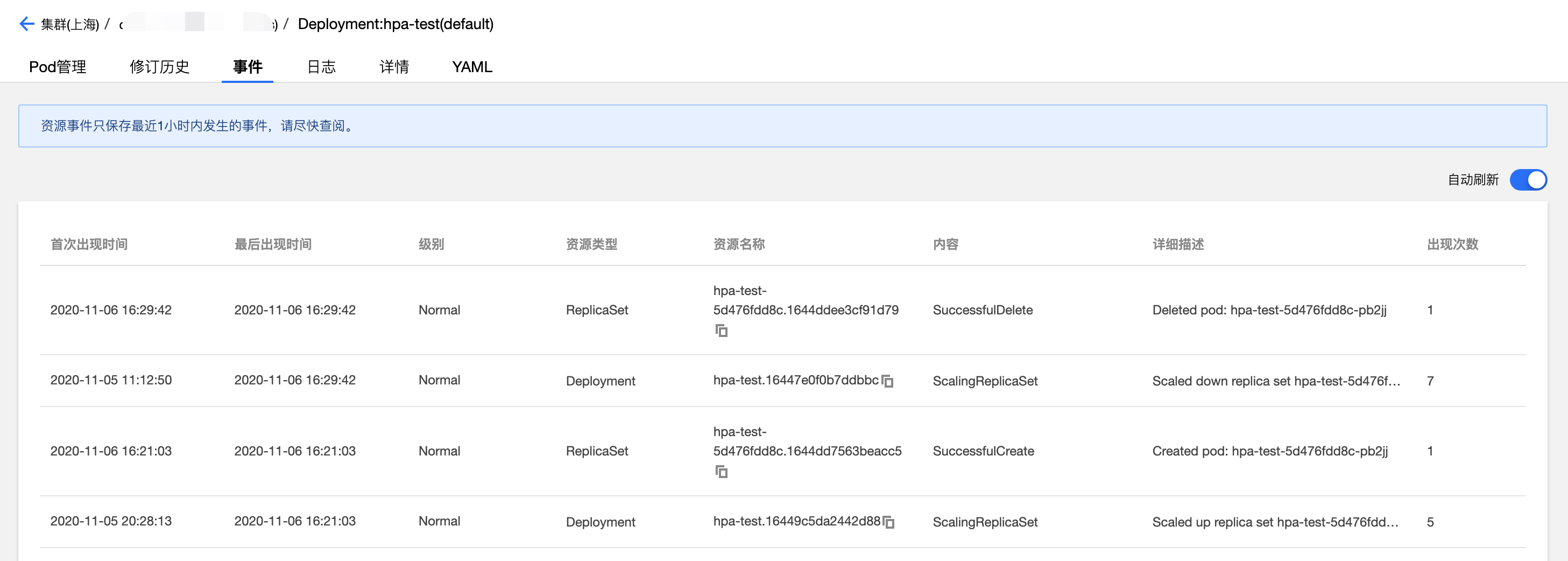
此外,工作負載事件列表也會記錄 HPA 發生時工作負載的增刪副本數事件,從下圖可以看出工作負載擴縮容時間點與 HPA 事件列表的時間點也是吻合的,增加副本數時間點是 16:21:03,減少副本數時間點是 16: 29:42。
在本示例中主要演示了 TKE 的 HPA 功能, 使用 TKE 自定義的網絡出口帶寬度量類型作為工作負載 HPA 的擴縮容度量指標,當工作負載實際度量值超過 HPA 配置的度量目標值時, HPA 根據擴容算法計算出合適的副本數實現水平擴容,保證工作負載的度量指標滿足預期,保障工作負載健康穩定運行;當實際度量值遠低于 HPA 配置的度量目標值時,HPA 會在容忍時間后計算合適的副本數實現水平縮容,適當釋放閑置資源,達到提升資源利用率的目的,并且整個過程在 HPA 和工作負載事件列表都會有相應的事件記錄,使整個工作負載水平擴縮容全程可追溯。
看完上述內容,你們對在TKE中如何利用 HPA 實現業務的彈性伸縮有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





