溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1、Cluster Manager:Spark集群的資源管理中心
1>Standalone模式:Cluster Manager為Spark原生的資源管理器,由Master節點負責資源的分配;
2>Haddop Yarn模式:Cluster Manager由Yarn中的ResearchManager負責資源的分配
3>Messos模式:Cluster Manager由Messos中的Messos Master負責資源管理。
2、Worker Node:Spark集群中可以運行Application代碼的工作節點。
3、Executor:是運行在工作節點(Worker Node)上的一個進程,負責執行具體的任務(Task),并且負責將數據存在內存或者磁盤上。
4、Application:Spark Application,是用戶構建在 Spark 上的程序
如圖:
1>包含了Driver,和一批應用獨立的Executor進程
2>每一個Application包含多個作業Job,每個Job包含多個Stage階段,每個stage包含多個Task。
3>Job:作業,一個Job包含多個RDD及作用于相應RDD上的各種操作。
4>Stage:階段,是作業的基本調度單位,一個作業會分為多組任務,每組任務被稱為“階段”。
5>TaskScheduler:任務調度器
6>Task:任務,運行在Executor上的工作單元,是Executor中的一個線程。
5、Driver Program:驅動程序
1>運行應用Application的 main() 方法并且創建了 SparkContext;
2>Driver 分為 main() 方法和 SparkContext兩部分。6、DAG:是Directed Acyclic Graph(有向無環圖)
1>用于反映RDD之間的依賴關系。
2>工作內容如圖: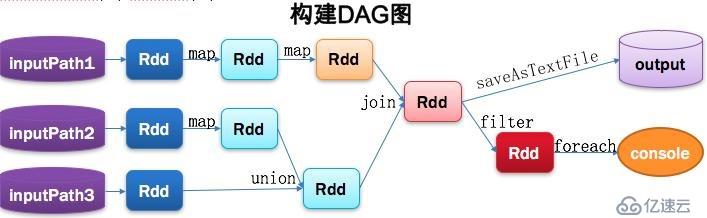
7、DAGScheduler:有向無環圖調度器
1>基于DAG劃分Stage,并以TaskSet的形勢提交Stage給TaskScheduler;
2>負責將作業拆分成不同階段的具有依賴關系的多批任務;
3>計算作業和任務的依賴關系,制定調度邏輯。
4>在SparkContext初始化的過程中被實例化,一個SparkContext對應創建一個DAGScheduler
5>工作內容如圖:
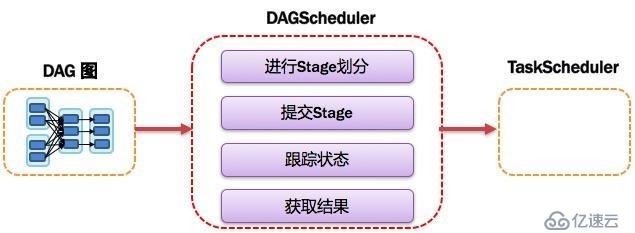
官方流程如圖: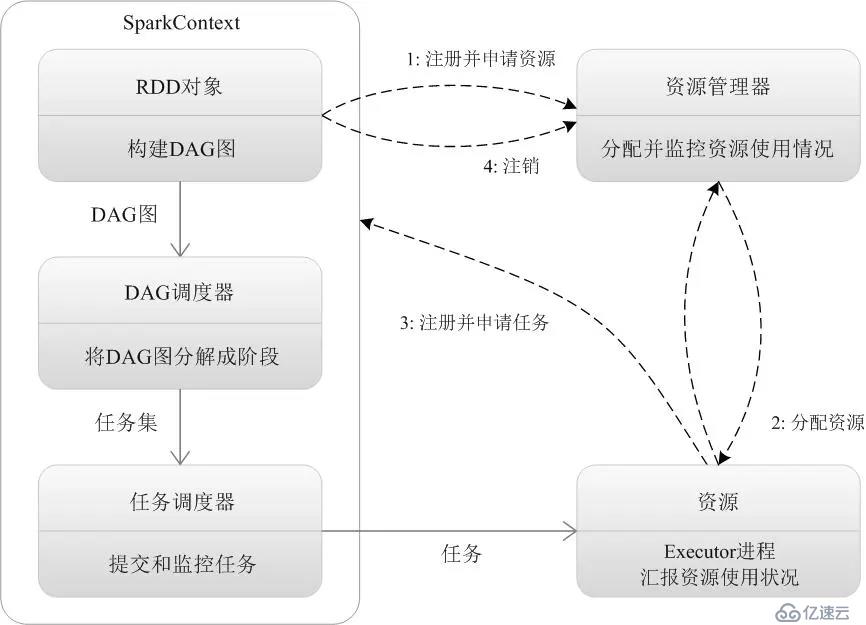
下面,我們對每一步做詳細說明:
1、客戶端提交作業:spark-submit
2、創建應用,運行Application應用程序的main函數,創建SparkContext對象(準備Spark應用程序的運行環境),并負責與Cluster Manager進行交互。
3、通過SparkContext向Cluster manager(Master)注冊,并申請需要運行的Executor資源。
4、Cluster manager按資源分配策略進行分配。
5、Cluster manager向分配好的Worker Node發送,啟動Executor進程指令。
6、Worker Node接收到指令后,啟動Executor進程。
7、Executor進程發送心跳給Cluster manager。
8、Driver程序的SparkContext,構建成DAG圖。
9、SparkContext進一步,將DAG圖分解成Stage階段(即任務集TaskSet)。
10、SparkContext進一步,將Stage階段(TaskSet)發送給任務調度器(TaskScheduler)。
11、Executor向TaskScheduler申請任務(Task)。
12、TaskScheduler將Task任務發放給Executor運行,SparkContext同時將Application應用代碼發放給Executor。
13、Executor運行應用代碼,Driver進行執行任務監控。
14、Execurot運行任務完畢后,向Driver發送任務完成信號。
15、Driver負責將SparkContext關閉,并向Cluster manager發送注銷信號。
15、Cluster manager收到Driver的注銷信號后,向Worker Node發送釋放資源信號。
16、Worker Node對應的Executor程序停止運行,資源釋放。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





