溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark Streaming初步使用以及工作原理是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
1.什么是流?
Streaming:是一種數據傳送技術,它把客戶機收到的數據變成一個穩定連續的
流,源源不斷地送出,使用戶聽到的聲音或看到的圖象十分平穩,而且用戶在
整個文件送完之前就可以開始在屏幕上瀏覽文件。
2.常見的流式計算框架
Apache Storm
Spark Streaming
Apache Samza
上述三種實時計算系統都是開源的分布式系統,具有低延遲、可擴展和容錯性
諸多優點,它們的共同特色在于:允許你在運行數據流代碼時,將任務分配到
一系列具有容錯能力的計算機上并行運行。此外,它們都提供了簡單的API來
簡化底層實現的復雜程度。
對于上面的三種流使計算框架的比較可以參考這篇文章流式大數據處理的三種框架:Storm,Spark和Samza
1.Spark Streaming介紹
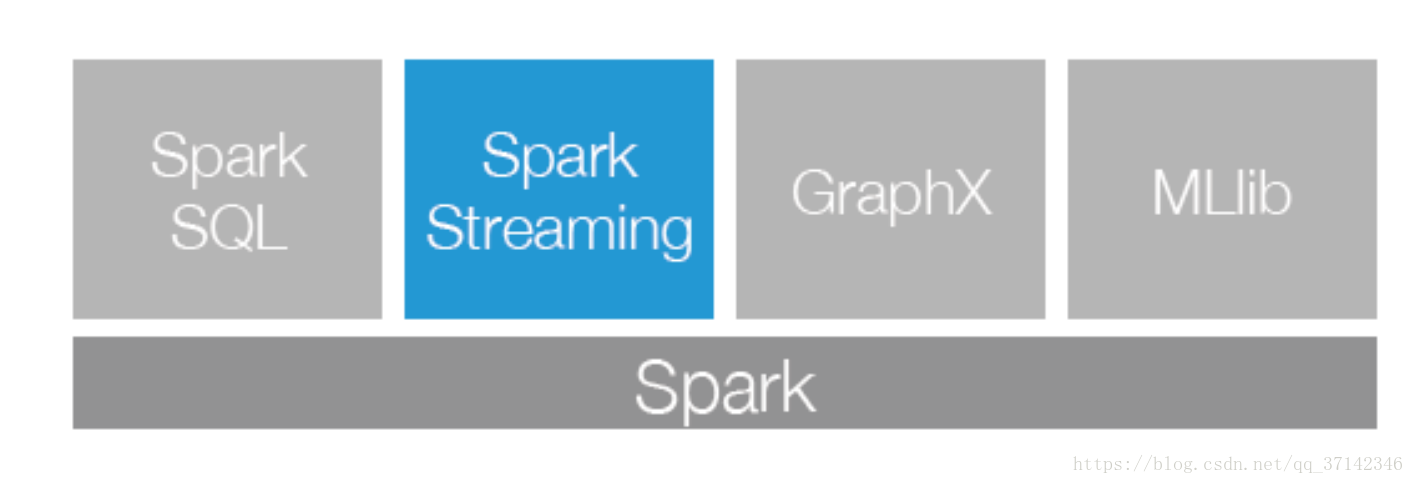
Spark Streaming是Spark生態系統當中一個重要的框架,它建立在Spark Core之上,下面這幅圖也可以看出Sparking Streaming在Spark生態系統中地位。
官方對于Spark Streaming的解釋如下:
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis or TCP sockets can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
Spark Streaming有以下特點:
高可擴展性,可以運行在上百臺機器上(Scales to hundreds of nodes)
低延遲,可以在秒級別上對數據進行處理(Achieves low latency)
高可容錯性(Efficiently recover from failures)
能夠集成并行計算程序,比如Spark Core(Integrates with batch and interactive processing)
2.Spark Streaming工作原理
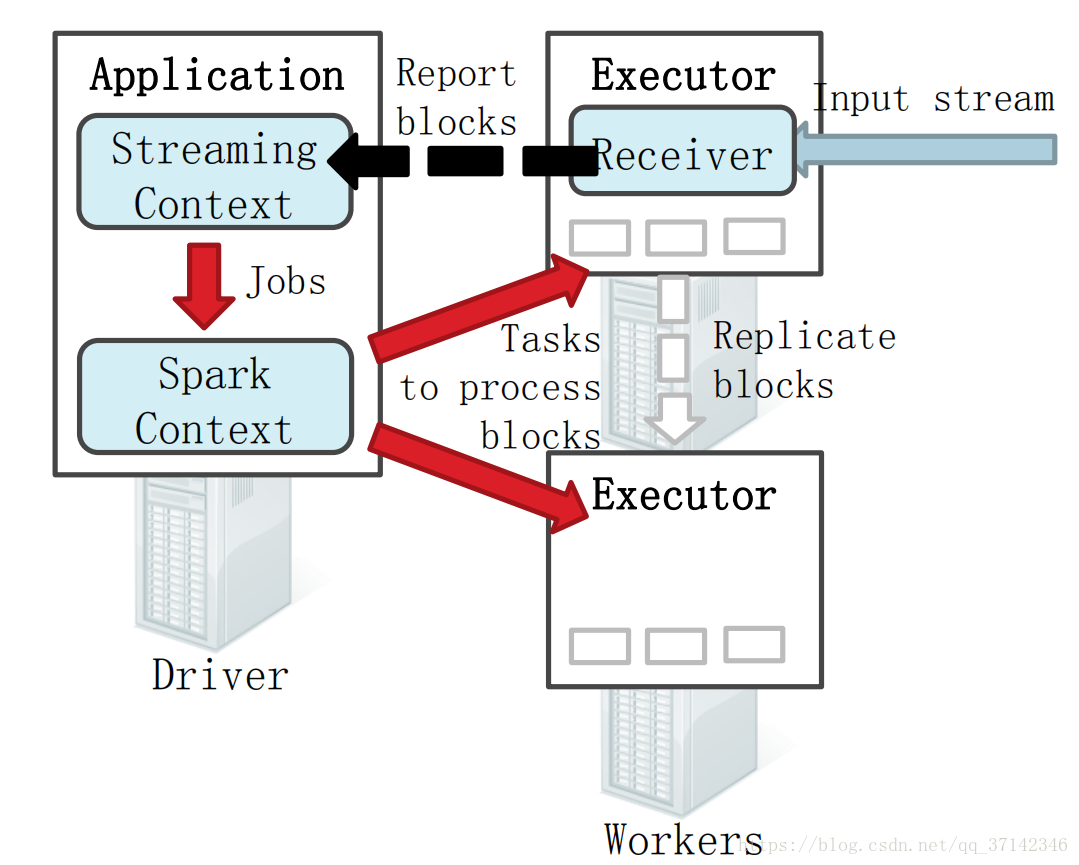
對于Spark Core它的核心就是RDD,對于Spark Streaming來說,它的核心是DStream,DStream類似于RDD,它實質上一系列的RDD的集合,DStream可以按照秒數將數據流進行批量的劃分。首先從接收到流數據之后,將其劃分為多個batch,然后提交給Spark集群進行計算,最后將結果批量輸出到HDFS或者數據庫以及前端頁面展示等等。可以參考下面這幅圖來幫助理解:
我們都知道Spark Core在初始化時會生成一個SparkContext對象來對數據進行后續的處理,相對應的Spark Streaming會創建一個Streaming Context,它的底層是SparkContext,也就是說它會將任務提交給SparkContext來執行,這也很好的解釋了DStream是一系列的RDD。當啟動Spark Streaming應用的時候,首先會在一個節點的Executor上啟動一個Receiver接受者,然后當從數據源寫入數據的時候會被Receiver接收,接收到數據之后Receiver會將數據Split成很多個block,然后備份到各個節點(Replicate Blocks 容災恢復),然后Receiver向StreamingContext進行塊報告,說明數據在那幾個節點的Executor上,接著在一定間隔時間內StreamingContext會將數據處理為RDD并且交給SparkContext劃分到各個節點進行并行計算。
3.Spark Streaming Demo
介紹完Spark Streaming的基本原理之后,下面來看看如何運行Spark Streaming,官方給出了一個例子,從Socket源端監控收集數據運行wordcount的案例,案例很簡單,這里不再說明,讀者可參考官方文檔【http://spark.apache.org/docs/1.3.0/streaming-programming-guide.html】
對于Spark Streaming的編程模型有兩種方式
第一種:通過SparkConf來創建SparkStreaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val conf=new SparkConf().setAppName("SparkStreamingDemo").setMaster("master")
val scc=new StreamingContext(conf,Seconds(1)) //每個1秒鐘檢測一次數據1
2
3
4
5
第二種:通過SparkContext來創建,也就是在Spark-Shell命令行運行:
import org.apache.spark.streaming._ val scc=new StreamingContext(sc,Seconds(1))
1
2
當然,我們也可以收集來自HDFS文件系統中數據,查閱Spark的源碼,可以發現如下方法:
這個方法會監控指定HDFS文件目錄下的數據,不過忽略以“.”開頭的文件,也就是不會收集以“.”開頭的文件進行數據的處理。
下面介紹一下如何從HDFS文件系統上監控數據運行wordcount案例統計單詞數并且將結果打印出來的案例:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
// read data
val lines = ssc.textFileStream("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/spark/streaming/")
// process
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面程序會每個5秒鐘檢測一下HDFS文件系統下的hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/spark/streaming/目錄是否有新的數據,如果有就進行統計,然后將結果打印在控制臺。運行上面代碼有兩種方式,可以運行Spark-shell客戶端后將上述命令一條條粘貼到命令行執行,顯然這樣很麻煩;第二種就是將上面的程序寫入到一個腳本文件中加載到Spark-shell命令行中執行,這里采用第二種方式:
在一個目錄下創建SparkStreamingDemo.scala文件,內容如上面的代碼所示。然后啟動Spark-shell客戶端。
$ bin/spark-shell --master local[2]
1
然后加載Spark Streaming應用:
scala>:load /opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh6.3.6/SparkStreamingDemo.scala
1
然后上傳數據到上述HDFS文件目錄下:
$ bin/hdfs dfs -put /opt/datas/wc.input /user/shinelon/spark/streaming/input7
1
該文件內容如下所示:
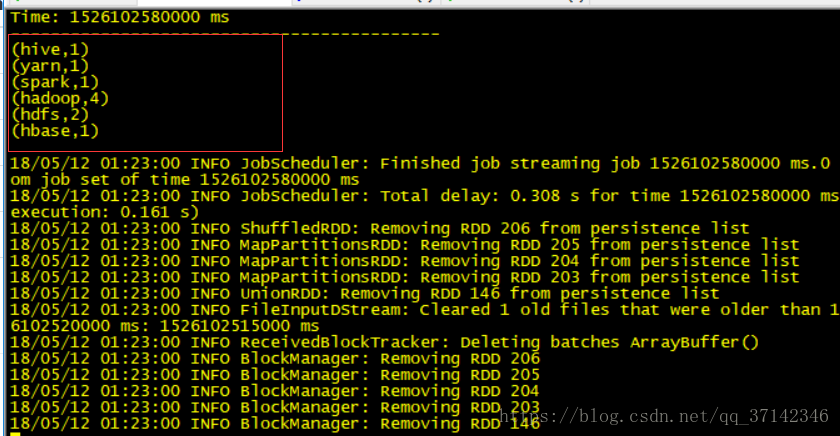
hadoop hive hadoop hbase hadoop yarn hadoop hdfs hdfs spark
1
2
3
4
5
運行結果如下所示:
通常對于一個Spark Streaming的應用程序的編寫分下面幾步:
定義一個輸入流源,比如獲取socket端的數據,HDFS,kafka中數據等等
定義一系列的處理轉換操作,比如上面的map,reduce操作等等,Spark Streaming也有類似于SparkCore的transformation操作
啟動程序收集數據(start())
等待程序停止(遇到錯誤終止或者手動停止awaitTermination())
手動終止應用程序(stop())
可以使用saveAsTextFiles()方法將結果輸出到HDFS文件系統上,讀者可以自行試驗將結果存入HDFS文件系統中。
最后,介紹一下Spark Streaming應用程序開發的幾種常見方式:
Spark Shell Code:開發、測試(上面提到過,將代碼一條條粘貼到命令行執行,這種方式只適用于測試)
Spark Shell Load Scripts:開發、測試(編寫scala腳本到spark-shell中執行)
IDE Develop App:開發、測試、打包JAR(生產環境),spark-submit提交應用程序
看完上述內容,你們掌握Spark Streaming初步使用以及工作原理是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。