溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Spark2.x入門中SparkStreaming的工作原理是什么,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
官網翻譯大體意思如下:
SparkStreaming是核心SparkApi的擴展,支持可伸縮、高吞吐量、容錯的實時數據流處理。數據可以從許多來源獲取,如Kafka、Flume、Kinesis或TCP sockets,可以使用復雜的算法處理數據,這些算法用高級函數表示,如map、reduce、join和window。最后,處理后的數據可以推送到文件系統、數據庫和活動儀表板。實際上,您可以將Spark的機器學習和圖形處理算法應用于數據流。

內部工作原理:SparkStreaming接受實時輸入數據流,并將數據分成批次,然后由Spark engine處理,以批量生成最終的結果流。
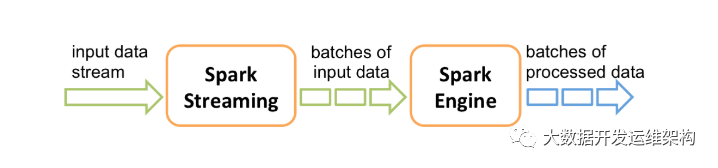
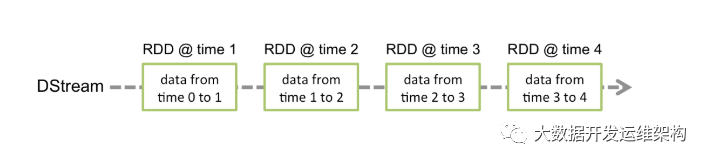
DStream是SparkStreaming流提供的基本抽象。它表示連續的數據流,可以是從源接收到的輸入數據流,也可以是通過轉換輸入流生成的經過處理的數據流。在內部,DStream由一系列連續的RDD表示,RDD是Spark對不可變的分布式數據集的抽象。DStream中的每個RDD包含來自某個間隔的數據,如下圖所示。
應用于DStream上的任何操作都轉換為底層RDD上的操作。例如,在前面將一個行流轉換為單詞的示例中,flatMap操作應用于行DStream中的每個RDD,以生成單詞DStream的RDD。如下圖所示。
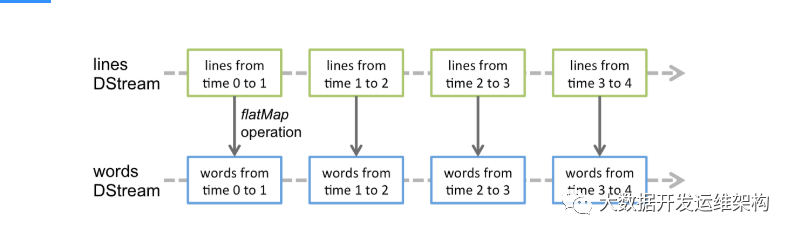
這些底層的RDD轉換是由Spark引擎計算的。DStream操作隱藏了這些細節中的大部分,并為開發人員提供了更高級的API。這些操作將在后面的小節中詳細討論。
SparkStreaming 、Flink 、Storm 三種流式處理框架對比分析
| SparkStreaming | Flink | Storm | |
| 吞吐量 | 高吞吐 | 高吞吐 | 低吞吐 |
| 實時性 | 秒級延遲 | 低延遲,毫秒級(百毫秒) | 低延遲,毫秒級(幾十毫秒) |
| 亂序、延遲處理 | 無 | flink通過warterMarker水印支持亂序和延遲處理,這個spark沒有 | 無 |
| 保證次數 | exactly-once | exactly-once | at-least-once |
| 動態調整并行度 | 不支持 | 支持 | 支持 |
| 容錯 | 基于RDD的checkpoint | 基于分布式Snapshot的checkpoint | 基于Record記錄的ack機制 |
以上就是Spark2.x入門中SparkStreaming的工作原理是什么,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





