溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何理解分布式SQL大數據查詢引擎的發展”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何理解分布式SQL大數據查詢引擎的發展”吧!
介紹
從高層的角度來看,許多數據和分析解決方案已經以相同的方式構建了許多年。 簡而言之,它由各種集成過程組成,可將所有數據加載到一個中央位置,這是即將到來的數據建模和分析用例的唯一事實來源。 雖然在較早的日子里,這些中心位置大多是昂貴的且不靈活的緊密耦合的硬件/軟件系統,但如今通常會利用云和分布式架構,包括計算和存儲的分離。 然而,盡管近年來取得了巨大的技術進步,但集中數據的整體方法仍然是最有效地利用其數據并進行適當的數據管理的最明顯方法。
集權
那么,這種集中化方法有什么問題呢?首先它與分布式查詢引擎有什么關系?
首先,沒有什么可反對的。事實上,恰恰相反,在一個地方以清晰,新鮮的狀態構建包含所有數據的海量數據倉庫或數據湖通常是確保一致性的唯一方法,因此每個人使用相同的定義。在這方面,尤其是云數據湖服務,例如Microsoft的Azure Data Lake Storage或Amazon Web Service的S3,通過啟用集中化的更多優勢而呈現出有趣的變化,這歸因于其非常靈活且廉價的方式來存儲大量任何類型的數據。
注意事項
但是,有很多原因使集中所有數據變得越來越困難。數據源的數量正在增長,滿足依賴該數據的越來越多的不同業務領域所需的數據集的多功能性也在不斷增長。通常,與靜態預建數據集相反,業務用戶越來越接近需要更高靈活性的數據。高級分析用例也是如此,通常需要對原始和未轉換的數據應用方法。而且,在某些情況下,由于任何內部或外部法規,甚至禁止組織遷移數據。在其他情況下,在集中式數據之上仍然存在管道,可將其進一步加載到任何下游系統中,以滿足所有分析要求。反過來,這甚至可能導致與傳統本地系統相同的鎖定。或集中數據不足以證明所涉及的工作合理的用例,或者數據太大而移動所需的時間太長的用例。依此類推…
那么在這種情況下該怎么辦?
聯邦
如今,在分析解決方案及其數據管理方面有很多選擇。不僅包括其報價的不同提供商,而且種類繁多的技術都勢不可擋,技術進步的步伐比以往更快。也沒有一個明確的贏家,他們無疑將幫助將更多的數據卡路里轉化為有用的東西,這毫無疑問。但是,基于SQL的分布式查詢引擎確實確實存在明顯的趨勢,有助于應對數據爆炸。這也證實了現有數據和分析服務提供商的產品陣容及其最新發展。他們都試圖無縫集成那些具有成本效益的云存儲,并允許使用完全一樣的查詢引擎在其上進行交互式SQL查詢。因此,它們可以填補上述缺失的空白,并允許成熟的企業通過保持核心事實,在保持組織和平臺穩定性的同時實現擴展的大數據功能。
數據虛擬化
分布式查詢引擎背后的基本思想無非就是數據虛擬化以及創建抽象層的嘗試,該抽象層提供了跨不同數據源的數據訪問。與傳統的數據虛擬化軟件(鏈接服務器,DBLink等)的區別在于,您可以橫向擴展方式一起查詢關系和非關系數據,以提高查詢性能。因此,分布式一詞不僅指查詢本身,還指計算和存儲。它們基本上是針對密集型OLAP查詢而設計的,因此在性能方面并不是那么脆弱和不一致。
Hadoop上的SQL
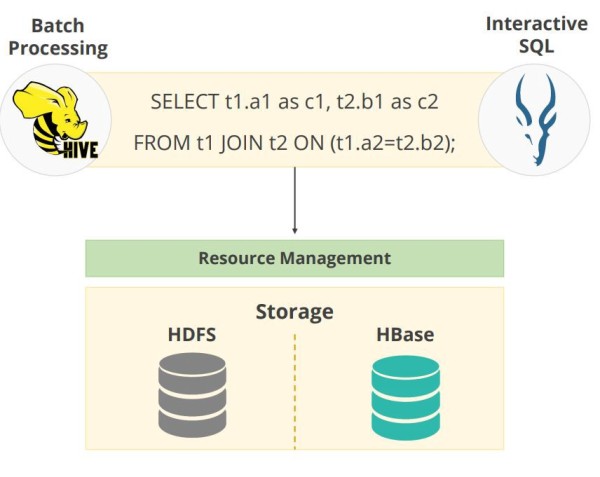
用于此目的的技術最初或仍然經常被稱為基于Hadoop的SQL-on-Hadoop,它依賴于MPP(大規模并行處理)引擎。它允許使用熟悉的類似于SQL的語言查詢和分析存儲在HDFS(Hadoop分布式文件系統)上的數據,以隱藏MapReduce / Tez的復雜性,并使數據庫開發人員更易于訪問。 Hive可以說是Hadoop上的第一個SQL引擎,并且由于多年來的發展已被證明具有非常強大的功能,因此Hive仍被廣泛用于批處理式數據處理。 Hive將SQL查詢轉換為多個階段,并將中間結果存儲到磁盤中。同時,在Hadoop生態系統中原生開發了其他專用工具,例如Impala,還支持將HBase用作數據源。與Hive相比,它利用了內存和緩存技術,與長期運行的批處理作業相比,它更適合用于交互式分析-此類別中的另一個示例是SparkSQL。所有這些都需要預先完成的元數據定義,也稱為讀取模式,例如視圖或外部表。此定義存儲在集中存儲中,例如Hive metastore。
SQL-on-Anything
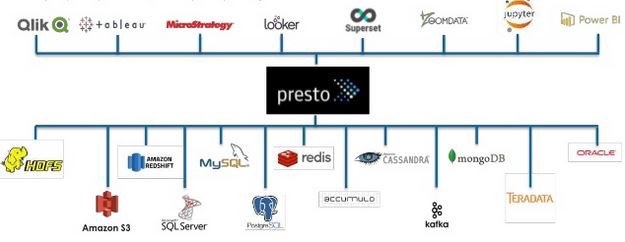
隨著技術的發展,需要更多的開放性,并且不嚴格與Hadoop捆綁在一起,而是以松散耦合的方式支持許多其他種類的其他數據庫。這樣,查詢引擎無需大量的先決條件和準備工作即可在大量數據上實現即插即用發現。此外,還提供了標準ANSI SQL作為接口,使數據分析人員和開發人員可以更輕松地訪問它。同時,不再需要預先定義架構,某些引擎甚至可以通過下推查詢(例如Drill)在原始存儲層自動解析它。該領域的另一個開拓性工具是Presto,它甚至可以查詢來自Kafka和Redis的實時流數據。 Presto是Facebook專門為滿足此需求而開發的一種內存中分布式SQL查詢引擎,可在不同的數據集中進行交互式分析。對于Netflix,Twitter,Airbnb或Uber等公司而言,這對于他們的日常業務至關重要,否則它們將無法處理和分析PB級的數據。 Presto可以與許多不同的BI工具一起使用,包括Power BI,Looker,Tableau,Superset或任何其他符合ODBC和JDBC的工具。在這種情況下," SQL-on-Anything"這個名字終于首次被創造出來。
數據湖引擎
數據湖引擎的技術方法沒有太大不同。畢竟,它僅僅是數據虛擬化和合并來自不同來源的數據。它們通常在提供更多有關數據建模,數據轉換,數據行數和數據安全性的功能方面有所不同。通常,它們也更趨向于云,并且可能會認為它們同時具有豐富的用戶界面,從而為非技術用戶帶來了一種數據自助服務理念。這種方法可以充分利用公共云中的數據集中性,并且由于云的價格彈性而可以以較低的成本進行交互式分析,而沒有任何鎖定風險。 Data Lake Engines也不一定支持更多的數據源,但是由于延遲到來,它們可以從頭開始利用最新技術。例如,Databricks最近發布了SQL Analytics,該數據庫由其Delta引擎提供支持,可直接查詢數據湖上的Delta Lake表。此外,它為數據瀏覽提供了SQL本機接口,并且儀表板可以彼此共享。在這方面,另一個非常有前途的工具也是我最喜歡的工具之一是Dremio,它基本上是開源的,但是得到了同名公司的支持,該公司提供了具有一些附加功能的商業化企業版。
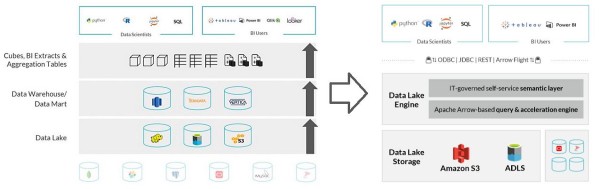
與傳統的多層體系結構相反,Dremio正在BI工具和查詢的數據源系統之間建立直接的橋梁。幕后使用的主要技術是Drill,Arrow,Calcite和parquet。這種組合提供了適用于各種數據源的無模式SQL,以及具有下推功能的柱狀內存分析執行引擎,并且可以輕松實現查詢以提高查詢性能。順便說一句,Arrow被視為內存分析的事實上的標準。
到此,相信大家對“如何理解分布式SQL大數據查詢引擎的發展”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





