溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎樣用一個開源工具實現多線程 Python 程序的可視化,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
VizTracer 可以跟蹤并發的 Python 程序,以幫助記錄、調試和剖析。
并發是現代編程中必不可少的一部分,因為我們有多個核心,有許多需要協作的任務。然而,當并發程序不按順序運行時,就很難理解它們。對于工程師來說,在這些程序中發現 bug 和性能問題不像在單線程、單任務程序中那么容易。
在 Python 中,你有多種并發的選擇。最常見的可能是用 threading 模塊的多線程,用subprocess 和 multiprocessing 模塊的多進程,以及最近用 asyncio 模塊提供的 async 語法。在 VizTracer 之前,缺乏分析使用了這些技術程序的工具。
VizTracer 是一個追蹤和可視化 Python 程序的工具,對日志、調試和剖析很有幫助。盡管它對單線程、單任務程序很好用,但它在并發程序中的實用性是它的獨特之處。
從一個簡單的練習任務開始:計算出一個數組中的整數是否是質數并返回一個布爾數組。下面是一個簡單的解決方案:
def is_prime(n): for i in range(2, n): if n % i == 0: return False return True def get_prime_arr(arr): return [is_prime(elem) for elem in arr]
試著用 VizTracer 以單線程方式正常運行它:
if __name__ == "__main__": num_arr = [random.randint(100, 10000) for _ in range(6000)] get_prime_arr(num_arr)
viztracer my_program.py

Running code in a single thread
調用堆棧報告顯示,耗時約 140ms,大部分時間花在 get_prime_arr 上。
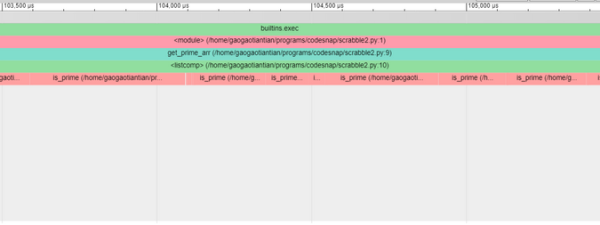
call-stack report
這只是在數組中的元素上一遍又一遍地執行 is_prime 函數。
這是你所期望的,而且它并不有趣(如果你了解 VizTracer 的話)。
試著用多線程程序來做:
if __name__ == "__main__": num_arr = [random.randint(100, 10000) for i in range(2000)] thread1 = Thread(target=get_prime_arr, args=(num_arr,)) thread2 = Thread(target=get_prime_arr, args=(num_arr,)) thread3 = Thread(target=get_prime_arr, args=(num_arr,)) thread1.start() thread2.start() thread3.start() thread1.join() thread2.join() thread3.join()
為了配合單線程程序的工作負載,這就為三個線程使用了一個 2000 元素的數組,模擬了三個線程共享任務的情況。

Multi-thread program
如果你熟悉 Python 的全局解釋器鎖(GIL),就會想到,它不會再快了。由于開銷太大,花了 140ms 多一點的時間。不過,你可以觀察到多線程的并發性:

Concurrency of multiple threads
當一個線程在工作(執行多個 is_prime 函數)時,另一個線程被凍結了(一個 is_prime 函數);后來,它們進行了切換。這是由于 GIL 的原因,這也是 Python 沒有真正的多線程的原因。它可以實現并發,但不能實現并行。
要想實現并行,辦法就是 multiprocessing 庫。下面是另一個使用 multiprocessing 的版本:
if __name__ == "__main__": num_arr = [random.randint(100, 10000) for _ in range(2000)] p1 = Process(target=get_prime_arr, args=(num_arr,)) p2 = Process(target=get_prime_arr, args=(num_arr,)) p3 = Process(target=get_prime_arr, args=(num_arr,)) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join()
要使用 VizTracer 運行它,你需要一個額外的參數:
viztracer --log_multiprocess my_program.py

Running with extra argument
整個程序在 50ms 多一點的時間內完成,實際任務在 50ms 之前完成。程序的速度大概提高了三倍。
為了和多線程版本進行比較,這里是多進程版本:

Multi-process version
在沒有 GIL 的情況下,多個進程可以實現并行,也就是多個 is_prime 函數可以并行執行。
不過,Python 的多線程也不是一無是處。例如,對于計算密集型和 I/O 密集型程序,你可以用睡眠來偽造一個 I/O 綁定的任務:
def io_task(): time.sleep(0.01)
在單線程、單任務程序中試試:
if __name__ == "__main__": for _ in range(3): io_task()

I/O-bound single-thread, single-task program
整個程序用了 30ms 左右,沒什么特別的。
現在使用多線程:
if __name__ == "__main__": thread1 = Thread(target=io_task) thread2 = Thread(target=io_task) thread3 = Thread(target=io_task) thread1.start() thread2.start() thread3.start() thread1.join() thread2.join() thread3.join()

I/O-bound multi-thread program
程序耗時 10ms,很明顯三個線程是并發工作的,這提高了整體性能。
Python 正在嘗試引入另一個有趣的功能,叫做異步編程。你可以制作一個異步版的任務:
import asyncio async def io_task(): await asyncio.sleep(0.01) async def main(): t1 = asyncio.create_task(io_task()) t2 = asyncio.create_task(io_task()) t3 = asyncio.create_task(io_task()) await t1 await t2 await t3 if __name__ == "__main__": asyncio.run(main())
由于 asyncio 從字面上看是一個帶有任務的單線程調度器,你可以直接在它上使用 VizTracer:

VizTracer with asyncio
依然花了 10ms,但顯示的大部分函數都是底層結構,這可能不是用戶感興趣的。為了解決這個問題,可以使用 --log_async 來分離真正的任務:
viztracer --log_async my_program.py

Using --log_async to separate tasks
現在,用戶任務更加清晰了。在大部分時間里,沒有任務在運行(因為它唯一做的事情就是睡覺)。有趣的部分是這里:
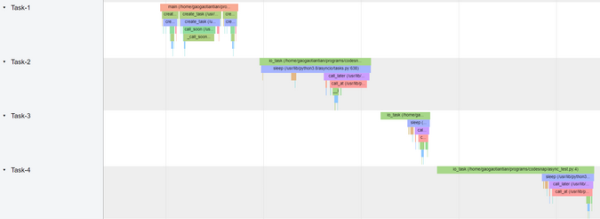
Graph of task creation and execution
這顯示了任務的創建和執行時間。Task-1 是 main() 協程,創建了其他任務。Task-2、Task-3、Task-4 執行 io_task 和 sleep 然后等待喚醒。如圖所示,因為是單線程程序,所以任務之間沒有重疊,VizTracer 這樣可視化是為了讓它更容易理解。
為了讓它更有趣,可以在任務中添加一個 time.sleep 的調用來阻止異步循環:
async def io_task(): time.sleep(0.01) await asyncio.sleep(0.01)

time.sleep call
程序耗時更長(40ms),任務填補了異步調度器中的空白。
這個功能對于診斷異步程序的行為和性能問題非常有幫助。
通過 VizTracer,你可以在時間軸上查看程序的進展情況,而不是從復雜的日志中想象。這有助于你更好地理解你的并發程序。
VizTracer 是開源的,在 Apache 2.0 許可證下發布,支持所有常見的操作系統(Linux、macOS 和 Windows)。你可以在 VizTracer 的 GitHub 倉庫中了解更多關于它的功能和訪問它的源代碼。
看完上述內容,你們對怎樣用一個開源工具實現多線程 Python 程序的可視化有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





