溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么用Python采集web質量數據到Excel表”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Python腳本編寫前的準備:
下載pycurl模塊,直接雙擊安裝即可。
xlsxwriter使用pip命令安裝,此處需要注意環境變量是否配置。
1、由于pycurl是下載下來直接安裝的,這里就不寫了,比較簡單。
2、安裝xlsxwriter模塊(需可連接Internet)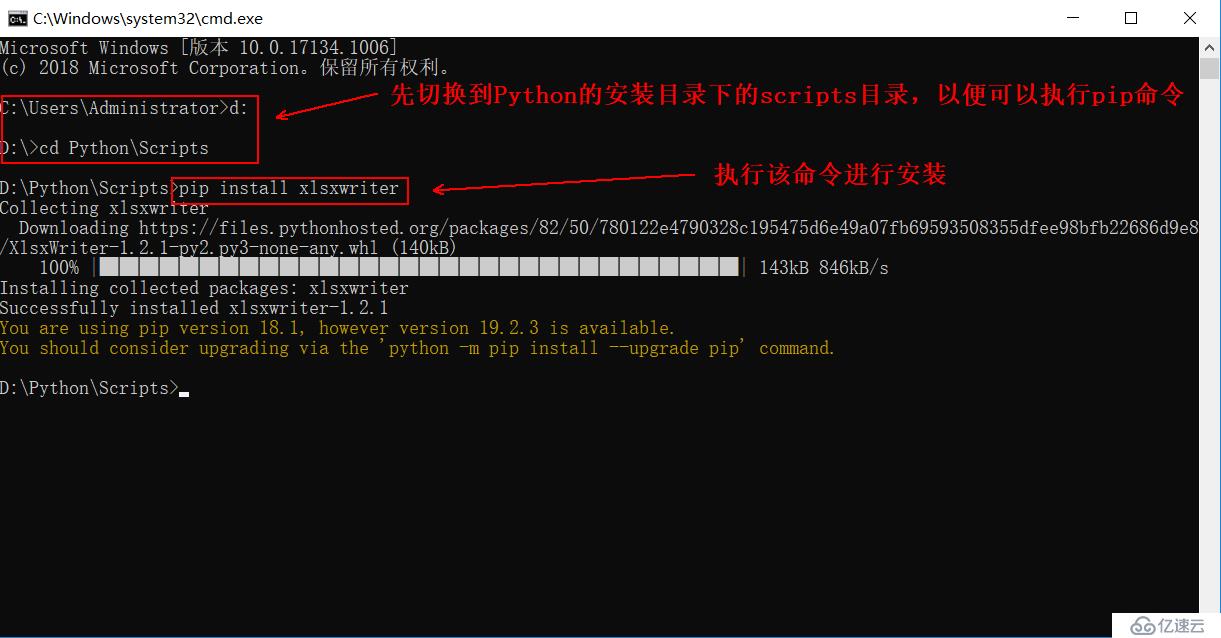
3、采集數據的腳本如下:
# _._ coding:utf-8 _._ import os,sys import pycurl import xlsxwriter URL="www.baidu.com" #探測目標的url,需要探測哪個目標,這里改哪個即可 c = pycurl.Curl() #創建一個curl對象 c.setopt(pycurl.URL, URL) #定義請求的url常量 c.setopt(pycurl.CONNECTTIMEOUT, 10) #定義請求連接的等待時間 c.setopt(pycurl.TIMEOUT, 10) #定義請求超時時間 c.setopt(pycurl.NOPROGRESS, 1) #屏蔽下載進度條 c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后強制斷開連接,不重用 c.setopt(pycurl.MAXREDIRS, 1) #指定HTTP重定向的最大數為1 c.setopt(pycurl.DNS_CACHE_TIMEOUT, 30) #創建一個文件對象,以’wb’方式打開,用來存儲返回的http頭部及頁面內容 indexfile = open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb") c.setopt(pycurl.WRITEHEADER, indexfile) #將返回的http頭部定向到indexfile文件 c.setopt(pycurl.WRITEDATA, indexfile) #將返回的html內容定向到indexfile文件 c.perform() NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME) #獲取DNS解析時間 CONNECT_TIME = c.getinfo(c.CONNECT_TIME) #獲取建立連接時間 TOTAL_TIME = c.getinfo(c.TOTAL_TIME) #獲取傳輸的總時間 HTTP_CODE = c.getinfo(c.HTTP_CODE) #獲取HTTP狀態碼 SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD) #獲取下載數據包大小 HEADER_SIZE = c.getinfo(c.HEADER_SIZE) #獲取HTTP頭部大小 SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD) #獲取平均下載速度 print u"HTTP狀態碼: %s" %(HTTP_CODE) #輸出狀態碼 print u"DNS解析時間: %.2f ms" %(NAMELOOKUP_TIME*1000) #輸出DNS解析時間 print u"建立連接時間: %.2f ms" %(CONNECT_TIME*1000) #輸出建立連接時間 print u"傳輸結束總時間: %.2f ms" %(TOTAL_TIME*1000) #輸出傳輸結束總時間 print u"下載數據包大小: %d bytes/s" %(SIZE_DOWNLOAD) #輸出下載數據包大小 print u"HTTP頭部大小: %d byte" %(HEADER_SIZE) #輸出HTTP頭部大小 print u"平均下載速度: %d bytes/s" %(SPEED_DOWNLOAD) #輸出平均下載速度 indexfile.close() #關閉文件 c.close() #關閉curl對象 f = file('chart.txt','a') #打開一個chart.txt文件,以追加的方式 f.write(str(HTTP_CODE)+','+str(NAMELOOKUP_TIME*1000)+','+str(CONNECT_TIME*1000)+','+str(TOTAL_TIME*1000)+','+str(SIZE_DOWNLOAD/1024)+','+str(HEADER_SIZE)+','+str(SPEED_DOWNLOAD/1024)+'\n') #將上面輸出的結果寫入到chart.txt文件 f.close() #關閉chart.txt文件 workbook = xlsxwriter.Workbook('chart.xlsx') #創建一個chart.xlsx的excel文件 worksheet = workbook.add_worksheet() #創建一個工作表對象,默認為Sheet1 chart = workbook.add_chart({'type': 'column'}) #創建一個圖表對象 title = [URL , u' HTTP狀態碼',u' DNS解析時間',u' 建立連接時間',u' 傳輸結束時間',u' 下載數據包大小',u' HTTP頭部大小',u' 平均下載速度'] #定義數據表頭列表 format=workbook.add_format() #定義format格式對象 format.set_border(1) #定義format對象單元格邊框加粗(1像素)的格式 format_title=workbook.add_format() #定義format_title格式對象 format_title.set_border(1) #定義format_title對象單元格邊框加粗(1像素)的格式 format_title.set_bg_color('#00FF00') #定義format_title對象單元格背景顏色為’#cccccc’ format_title.set_align('center') #定義format_title對象單元格居中對齊的格式 format_title.set_bold() #定義format_title對象單元格內容加粗的格式 worksheet.write_row(0, 0,title,format_title) #將title的內容寫入到第一行 f = open('chart.txt','r') #以只讀的方式打開chart.txt文件 line = 1 #定義變量line等于1 for i in f: #開啟for循環讀文件 head = [line] #定義變量head等于line lineList = i.split(',') #將字符串轉化為列表形式 lineList = map(lambda i2:int(float(i2.replace("\n", ''))), lineList) #將列表中的最后\n刪除,將小數點后面的數字刪除,將浮點型轉換成整型 lineList = head + lineList #兩個列表相加 worksheet.write_row(line, 0, lineList, format) #將數據寫入到execl表格中 line += 1 average = [u'平均值', '=AVERAGE(B2:B' + str((line - 1)) +')', '=AVERAGE(C2:C' + str((line - 1)) +')', '=AVERAGE(D2:D' + str((line - 1)) +')', '=AVERAGE(E2:E' + str((line - 1)) +')', '=AVERAGE(F2:F' + str((line - 1)) +')', '=AVERAGE(G2:G' + str((line - 1)) +')', '=AVERAGE(H2:H' + str((line - 1)) +')'] #求每一列的平均值 worksheet.write_row(line, 0, average, format) #在最后一行數據下面寫入平均值 f.close() #關閉文件 def chart_series(cur_row, line): #定義一個函數 chart.add_series({ 'categories': '=Sheet1!$B$1:$H$1', #將要輸出的參數作為圖表數據標簽(X軸) 'values': '=Sheet1!$B$'+cur_row+':$H$'+cur_row, #獲取B列到H列的數據 'line': {'color': 'black'}, #線條顏色定義為black 'name': '=Sheet1!$A'+ cur_row, #引用業務名稱為圖例項 }) for row in range(2, line + 1): #從第二行開始到最后一次取文本中的行的數據系列函數調用 chart_series(str(row), line) chart.set_size({'width':876,'height':287}) #定義圖表的寬度及高度 worksheet.insert_chart(line + 2, 0, chart) #在最后一行數據下面的兩行處插入圖表 workbook.close() #關閉execl文檔
4、運行腳本后,會在腳本所在的目錄下產生三個文件,兩個是txt文本文件,一個是Excel文件,執行腳本后,會顯示如下信息:
5、當前目錄下產生的文件如下: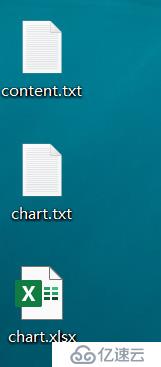
其中,兩個txt格式的文件都是為了給Excel做鋪墊的,所以可以選擇性忽略即可,主要是看Excel中的數據。Excel中的數據如下(以下是執行6次腳本后的顯示結果,也就是說探測了6次):
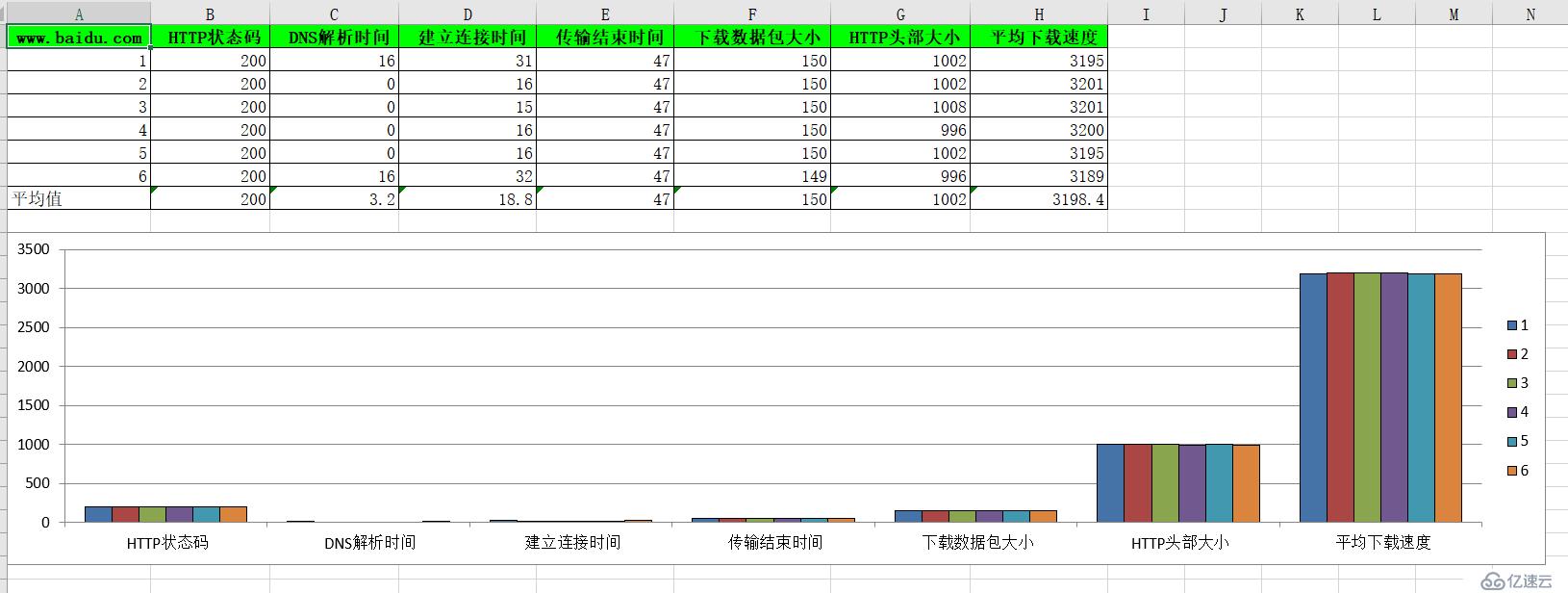
“怎么用Python采集web質量數據到Excel表”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





