溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文介紹了PyTorch上搭建簡單神經網絡實現回歸和分類的示例,分享給大家,具體如下:

一、PyTorch入門
1. 安裝方法
登錄PyTorch官網,http://pytorch.org,可以看到以下界面:
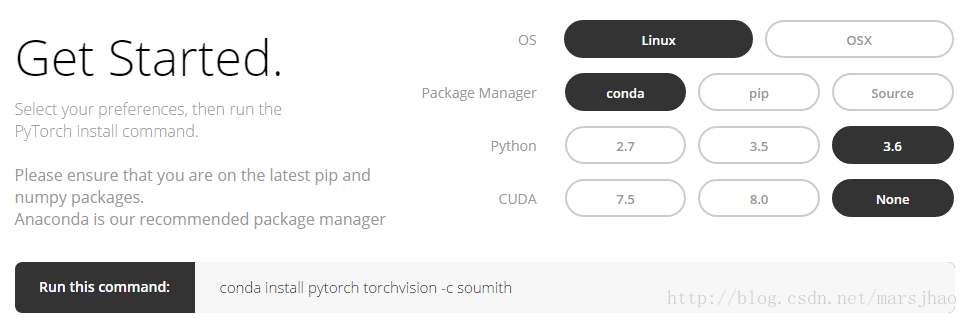
按上圖的選項選擇后即可得到Linux下conda指令:
conda install pytorch torchvision -c soumith
目前PyTorch僅支持MacOS和Linux,暫不支持Windows。安裝 PyTorch 會安裝兩個模塊,一個是torch,一個 torchvision, torch 是主模塊,用來搭建神經網絡的,torchvision 是輔模塊,有數據庫,還有一些已經訓練好的神經網絡等著你直接用,比如 (VGG, AlexNet, ResNet)。
2. Numpy與Torch
torch_data = torch.from_numpy(np_data)可以將numpy(array)格式轉換為torch(tensor)格式;torch_data.numpy()又可以將torch的tensor格式轉換為numpy的array格式。注意Torch的Tensor和numpy的array會共享他們的存儲空間,修改一個會導致另外的一個也被修改。
對于1維(1-D)的數據,numpy是以行向量的形式打印輸出,而torch是以列向量的形式打印輸出的。
其他例如sin, cos, abs,mean等numpy中的函數在torch中用法相同。需要注意的是,numpy中np.matmul(data, data)和data.dot(data)矩陣相乘會得到相同結果;torch中torch.mm(tensor, tensor)是矩陣相乘的方法,得到一個矩陣,tensor.dot(tensor)會把tensor轉換為1維的tensor,然后逐元素相乘后求和,得到與一個實數。
相關代碼:
import torch import numpy as np np_data = np.arange(6).reshape((2, 3)) torch_data = torch.from_numpy(np_data) # 將numpy(array)格式轉換為torch(tensor)格式 tensor2array = torch_data.numpy() print( '\nnumpy array:\n', np_data, '\ntorch tensor:', torch_data, '\ntensor to array:\n', tensor2array, ) # torch數據格式在print的時候前后自動添加換行符 # abs data = [-1, -2, 2, 2] tensor = torch.FloatTensor(data) print( '\nabs', '\nnumpy: \n', np.abs(data), '\ntorch: ', torch.abs(tensor) ) # 1維的數據,numpy是行向量形式顯示,torch是列向量形式顯示 # sin print( '\nsin', '\nnumpy: \n', np.sin(data), '\ntorch: ', torch.sin(tensor) ) # mean print( '\nmean', '\nnumpy: ', np.mean(data), '\ntorch: ', torch.mean(tensor) ) # 矩陣相乘 data = [[1,2], [3,4]] tensor = torch.FloatTensor(data) print( '\nmatrix multiplication (matmul)', '\nnumpy: \n', np.matmul(data, data), '\ntorch: ', torch.mm(tensor, tensor) ) data = np.array(data) print( '\nmatrix multiplication (dot)', '\nnumpy: \n', data.dot(data), '\ntorch: ', tensor.dot(tensor) )
3. Variable
PyTorch中的神經網絡來自于autograd包,autograd包提供了Tensor所有操作的自動求導方法。
autograd.Variable這是這個包中最核心的類。可以將Variable理解為一個裝有tensor的容器,它包裝了一個Tensor,并且幾乎支持所有的定義在其上的操作。一旦完成運算,便可以調用 .backward()來自動計算出所有的梯度。也就是說只有把tensor置于Variable中,才能在神經網絡中實現反向傳遞、自動求導等運算。
可以通過屬性 .data 來訪問原始的tensor,而關于這一Variable的梯度則可通過 .grad屬性查看。
相關代碼:
import torch
from torch.autograd import Variable
tensor = torch.FloatTensor([[1,2],[3,4]])
variable = Variable(tensor, requires_grad=True)
# 打印展示Variable類型
print(tensor)
print(variable)
t_out = torch.mean(tensor*tensor) # 每個元素的^ 2
v_out = torch.mean(variable*variable)
print(t_out)
print(v_out)
v_out.backward() # Variable的誤差反向傳遞
# 比較Variable的原型和grad屬性、data屬性及相應的numpy形式
print('variable:\n', variable)
# v_out = 1/4 * sum(variable*variable) 這是計算圖中的 v_out 計算步驟
# 針對于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2
print('variable.grad:\n', variable.grad) # Variable的梯度
print('variable.data:\n', variable.data) # Variable的數據
print(variable.data.numpy()) #Variable的數據的numpy形式
部分輸出結果:
variable:
Variable containing:
1 2
3 4
[torch.FloatTensor of size 2x2]
variable.grad:
Variable containing:
0.5000 1.0000
1.5000 2.0000
[torch.FloatTensor of size 2x2]
variable.data:
1 2
3 4
[torch.FloatTensor of size 2x2]
[[ 1. 2.]
[ 3. 4.]]
4. 激勵函數activationfunction
Torch的激勵函數都在torch.nn.functional中,relu,sigmoid, tanh, softplus都是常用的激勵函數。
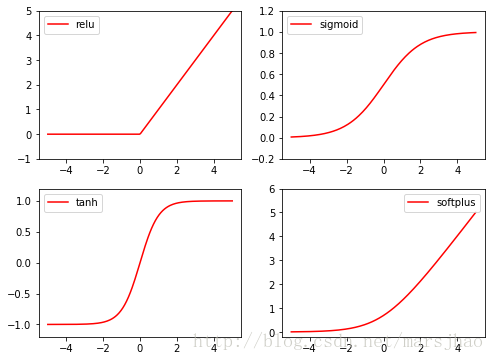
相關代碼:
import torch import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) x_variable = Variable(x) #將x放入Variable x_np = x_variable.data.numpy() # 經過4種不同的激勵函數得到的numpy形式的數據結果 y_relu = F.relu(x_variable).data.numpy() y_sigmoid = F.sigmoid(x_variable).data.numpy() y_tanh = F.tanh(x_variable).data.numpy() y_softplus = F.softplus(x_variable).data.numpy() plt.figure(1, figsize=(8, 6)) plt.subplot(221) plt.plot(x_np, y_relu, c='red', label='relu') plt.ylim((-1, 5)) plt.legend(loc='best') plt.subplot(222) plt.plot(x_np, y_sigmoid, c='red', label='sigmoid') plt.ylim((-0.2, 1.2)) plt.legend(loc='best') plt.subplot(223) plt.plot(x_np, y_tanh, c='red', label='tanh') plt.ylim((-1.2, 1.2)) plt.legend(loc='best') plt.subplot(224) plt.plot(x_np, y_softplus, c='red', label='softplus') plt.ylim((-0.2, 6)) plt.legend(loc='best') plt.show()
二、PyTorch實現回歸
先看完整代碼:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 將1維的數據轉換為2維數據
y = x.pow(2) + 0.2 * torch.rand(x.size())
# 將tensor置入Variable中
x, y = Variable(x), Variable(y)
#plt.scatter(x.data.numpy(), y.data.numpy())
#plt.show()
# 定義一個構建神經網絡的類
class Net(torch.nn.Module): # 繼承torch.nn.Module類
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 獲得Net類的超類(父類)的構造方法
# 定義神經網絡的每層結構形式
# 各個層的信息都是Net類對象的屬性
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隱藏層線性輸出
self.predict = torch.nn.Linear(n_hidden, n_output) # 輸出層線性輸出
# 將各層的神經元搭建成完整的神經網絡的前向通路
def forward(self, x):
x = F.relu(self.hidden(x)) # 對隱藏層的輸出進行relu激活
x = self.predict(x)
return x
# 定義神經網絡
net = Net(1, 10, 1)
print(net) # 打印輸出net的結構
# 定義優化器和損失函數
optimizer = torch.optim.SGD(net.parameters(), lr=0.5) # 傳入網絡參數和學習率
loss_function = torch.nn.MSELoss() # 最小均方誤差
# 神經網絡訓練過程
plt.ion() # 動態學習過程展示
plt.show()
for t in range(300):
prediction = net(x) # 把數據x喂給net,輸出預測值
loss = loss_function(prediction, y) # 計算兩者的誤差,要注意兩個參數的順序
optimizer.zero_grad() # 清空上一步的更新參數值
loss.backward() # 誤差反相傳播,計算新的更新參數值
optimizer.step() # 將計算得到的更新值賦給net.parameters()
# 可視化訓練過程
if (t+1) % 10 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'L=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
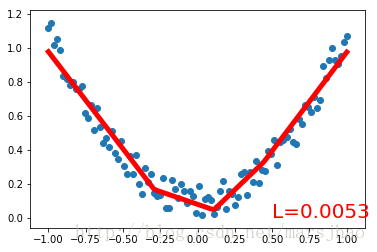
首先創建一組帶噪聲的二次函數擬合數據,置于Variable中。定義一個構建神經網絡的類Net,繼承torch.nn.Module類。Net類的構造方法中定義輸入神經元、隱藏層神經元、輸出神經元數量的參數,通過super()方法獲得Net父類的構造方法,以屬性的方式定義Net的各個層的結構形式;定義Net的forward()方法將各層的神經元搭建成完整的神經網絡前向通路。
定義好Net類后,定義神經網絡實例,Net類實例可以直接print打印輸出神經網絡的結構信息。接著定義神經網絡的優化器和損失函數。定義好這些后就可以進行訓練了。optimizer.zero_grad()、loss.backward()、optimizer.step()分別是清空上一步的更新參數值、進行誤差的反向傳播并計算新的更新參數值、將計算得到的更新值賦給net.parameters()。循環迭代訓練過程。
運行結果:
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
三、PyTorch實現簡單分類
完整代碼:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 生成數據
# 分別生成2組各100個數據點,增加正態噪聲,后標記以y0=0 y1=1兩類標簽,最后cat連接到一起
n_data = torch.ones(100,2)
# torch.normal(means, std=1.0, out=None)
x0 = torch.normal(2*n_data, 1) # 以tensor的形式給出輸出tensor各元素的均值,共享標準差
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # 組裝(連接)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
# 置入Variable中
x, y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2)
print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.012)
loss_func = torch.nn.CrossEntropyLoss()
plt.ion()
plt.show()
for t in range(100):
out = net(x)
loss = loss_func(out, y) # loss是定義為神經網絡的輸出與樣本標簽y的差別,故取softmax前的值
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 2 == 0:
plt.cla()
# 過了一道 softmax 的激勵函數后的最大概率才是預測值
# torch.max既返回某個維度上的最大值,同時返回該最大值的索引值
prediction = torch.max(F.softmax(out), 1)[1] # 在第1維度取最大值并返回索引值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y)/200 # 預測中有多少和真實值一樣
plt.text(1.5, -4, 'Accu=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
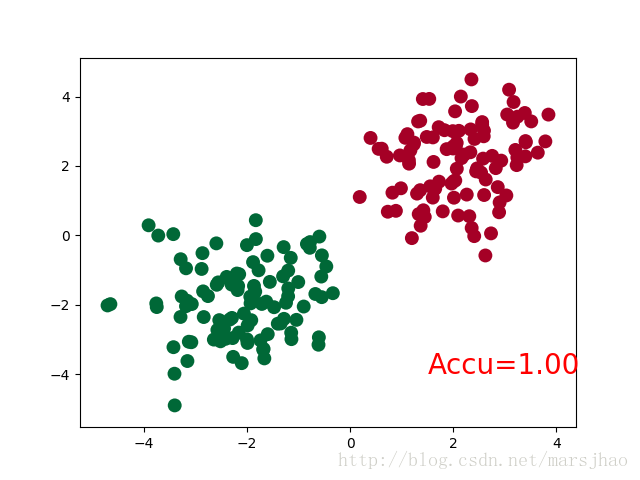
神經網絡結構部分的Net類與前文的回歸部分的結構相同。
需要注意的是,在循環迭代訓練部分,out定義為神經網絡的輸出結果,計算誤差loss時不是使用one-hot形式的,loss是定義在out與y上的torch.nn.CrossEntropyLoss(),而預測值prediction定義為out經過Softmax后(將結果轉化為概率值)的結果。
運行結果:
Net (
(hidden): Linear (2 -> 10)
(out):Linear (10 -> 2)
)
四、補充知識
1. super()函數
在定義Net類的構造方法的時候,使用了super(Net,self).__init__()語句,當前的類和對象作為super函數的參數使用,這條語句的功能是使Net類的構造方法獲得其超類(父類)的構造方法,不影響對Net類單獨定義構造方法,且不必關注Net類的父類到底是什么,若需要修改Net類的父類時只需修改class語句中的內容即可。
2. torch.normal()
torch.normal()可分為三種情況:(1)torch.normal(means,std, out=None)中means和std都是Tensor,兩者的形狀可以不必相同,但Tensor內的元素數量必須相同,一一對應的元素作為輸出的各元素的均值和標準差;(2)torch.normal(mean=0.0, std, out=None)中mean是一個可定義的float,各個元素共享該均值;(3)torch.normal(means,std=1.0, out=None)中std是一個可定義的float,各個元素共享該標準差。
3. torch.cat(seq, dim=0)
torch.cat可以將若干個Tensor組裝連接起來,dim指定在哪個維度上進行組裝。
4. torch.max()
(1)torch.max(input)→ float
input是tensor,返回input中的最大值float。
(2)torch.max(input,dim, keepdim=True, max=None, max_indices=None) -> (Tensor, LongTensor)
同時返回指定維度=dim上的最大值和該最大值在該維度上的索引值。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





