溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Pytorch怎么實現簡單的垃圾分類”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Pytorch怎么實現簡單的垃圾分類”吧!
垃圾數據都放在了名字為「垃圾圖片庫」的文件夾里。
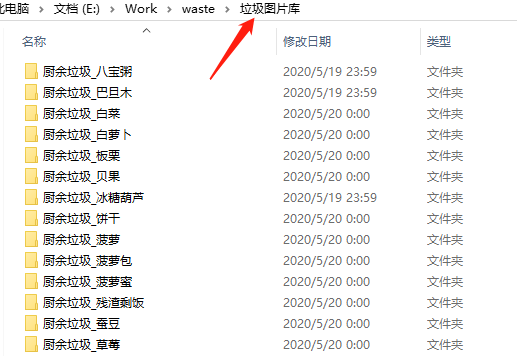
首先,我們需要寫個腳本根據文件夾名,生成對應的標簽文件(dir_label.txt)。
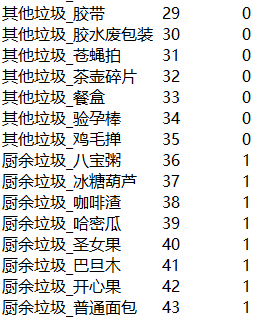
前面是小分類標簽,后面是大分類標簽。
然后再將數據集分為訓練集(train.txt)、驗證集(val.txt)、測試集(test.txt)。
訓練集和驗證集用于訓練模型,測試集用于驗收最終模型效果。
此外,在使用圖片訓練之前還需要檢查下圖片質量,使用 PIL 的 Image 讀取,捕獲 Error 和 Warning 異常,對有問題的圖片直接刪除即可。
寫個腳本生成三個 txt 文件,訓練集 48045 張,驗證集 5652 張,測試集 2826 張。
腳本很簡單,代碼就不貼了,直接提供處理好的文件。
處理好的四個 txt 文件可以直接下載。
編寫 dataset.py 讀取數據,看一下效果。
import torch
from PIL import Image
import os
import glob
from torch.utils.data import Dataset
import random
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Garbage_Loader(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])
self.val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img = Image.open(img_path)
img = img.convert('RGB')
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
if __name__ == "__main__":
train_dataset = Garbage_Loader("train.txt", True)
print("數據個數:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=1,
shuffle=True)
for image, label in train_loader:
print(image.shape)
print(label)讀取 train.txt 文件,加載數據。數據預處理,是將圖片等比例填充到尺寸為 280 * 280 的純黑色圖片上,然后再 resize 到 224 * 224 的尺寸。
這是圖片分類里,很常規的一種預處理方法。
此外,針對訓練集,使用 pytorch 的 transforms 添加了水平翻轉和垂直翻轉的隨機操作,這也是很常見的一種數據增強方法。
運行結果:
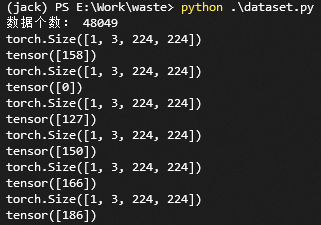
OK,搞定!開始寫訓練代碼!
我們使用一個常規的網絡 ResNet50 ,這是一個非常常見的提取特征的網絡結構。
創建 train.py 文件,編寫如下代碼:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
import time
import os
import shutil
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
"""
Author : Jack Cui
Wechat : https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
from tensorboardX import SummaryWriter
def accuracy(output, target, topk=(1,)):
"""
計算topk的準確率
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
class_to = pred[0].cpu().numpy()
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res, class_to
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
根據 is_best 存模型,一般保存 valid acc 最好的模型
"""
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best_' + filename)
def train(train_loader, model, criterion, optimizer, epoch, writer):
"""
訓練代碼
參數:
train_loader - 訓練集的 DataLoader
model - 模型
criterion - 損失函數
optimizer - 優化器
epoch - 進行第幾個 epoch
writer - 用于寫 tensorboardX
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
writer.add_scalar('loss/train_loss', losses.val, global_step=epoch)
def validate(val_loader, model, criterion, epoch, writer, phase="VAL"):
"""
驗證代碼
參數:
val_loader - 驗證集的 DataLoader
model - 模型
criterion - 損失函數
epoch - 進行第幾個 epoch
writer - 用于寫 tensorboardX
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Test-{0}: [{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
phase, i, len(val_loader),
batch_time=batch_time,
loss=losses,
top1=top1, top5=top5))
print(' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(phase, top1=top1, top5=top5))
writer.add_scalar('loss/valid_loss', losses.val, global_step=epoch)
return top1.avg, top5.avg
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
if __name__ == "__main__":
# -------------------------------------------- step 1/4 : 加載數據 ---------------------------
train_dir_list = 'train.txt'
valid_dir_list = 'val.txt'
batch_size = 64
epochs = 80
num_classes = 214
train_data = Garbage_Loader(train_dir_list, train_flag=True)
valid_data = Garbage_Loader(valid_dir_list, train_flag=False)
train_loader = DataLoader(dataset=train_data, num_workers=8, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=8, pin_memory=True, batch_size=batch_size)
train_data_size = len(train_data)
print('訓練集數量:%d' % train_data_size)
valid_data_size = len(valid_data)
print('驗證集數量:%d' % valid_data_size)
# ------------------------------------ step 2/4 : 定義網絡 ------------------------------------
model = models.resnet50(pretrained=True)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, num_classes)
model = model.cuda()
# ------------------------------------ step 3/4 : 定義損失函數和優化器等 -------------------------
lr_init = 0.0001
lr_stepsize = 20
weight_decay = 0.001
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=0.1)
writer = SummaryWriter('runs/resnet50')
# ------------------------------------ step 4/4 : 訓練 -----------------------------------------
best_prec1 = 0
for epoch in range(epochs):
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)
# 在驗證集上測試效果
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase="VAL")
is_best = valid_prec1 > best_prec1
best_prec1 = max(valid_prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': 'resnet50',
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best,
filename='checkpoint_resnet50.pth.tar')
writer.close()代碼并不復雜,網絡結構直接使 torchvision 的 ResNet50 模型,并且采用 ResNet50 的預訓練模型。算法采用交叉熵損失函數,優化器選擇 Adam,并采用 StepLR 進行學習率衰減。
保存模型的策略是選擇在驗證集準確率最高的模型。
batch size 設為 64,GPU 顯存大約占 8G,顯存不夠的,可以調整 batch size 大小。
模型訓練完成,就可以寫測試代碼了,看下效果吧!
創建 infer.py 文件,編寫如下代碼:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
import torch.nn as nn
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def softmax(x):
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x, 0)
return softmax_x
with open('dir_label.txt', 'r', encoding='utf-8') as f:
labels = f.readlines()
labels = list(map(lambda x:x.strip().split('\t'), labels))
if __name__ == "__main__":
test_list = 'test.txt'
test_data = Garbage_Loader(test_list, train_flag=False)
test_loader = DataLoader(dataset=test_data, num_workers=1, pin_memory=True, batch_size=1)
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
model = model.cuda()
# 加載訓練好的模型
checkpoint = torch.load('model_best_checkpoint_resnet50.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
model.eval()
for i, (image, label) in enumerate(test_loader):
src = image.numpy()
src = src.reshape(3, 224, 224)
src = np.transpose(src, (1, 2, 0))
image = image.cuda()
label = label.cuda()
pred = model(image)
pred = pred.data.cpu().numpy()[0]
score = softmax(pred)
pred_id = np.argmax(score)
plt.imshow(src)
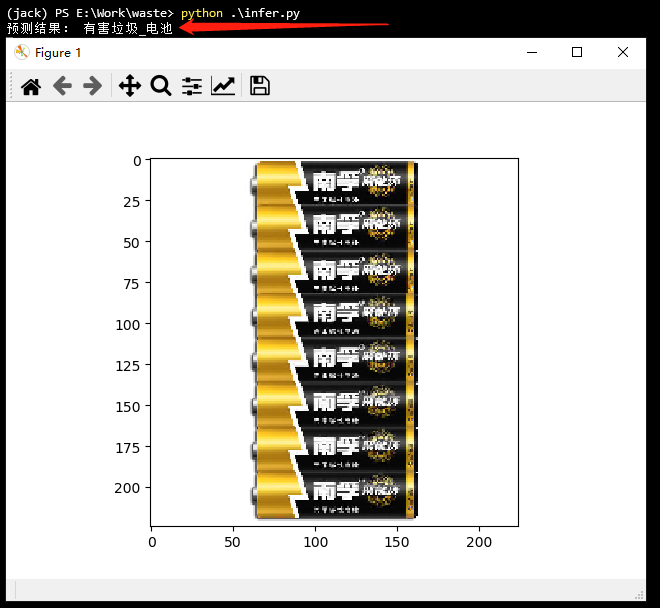
print('預測結果:', labels[pred_id][0])
plt.show()這里需要注意的是,DataLoader 讀取的數據需要進行通道轉換,才能顯示。
預測結果:
感謝各位的閱讀,以上就是“Pytorch怎么實現簡單的垃圾分類”的內容了,經過本文的學習后,相信大家對Pytorch怎么實現簡單的垃圾分類這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





