溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹python如何實現布隆過濾器及原理解析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
一、布隆過濾器簡介
什么是布隆過濾器?
本質上布隆過濾器( BloomFilter )是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”。
相比于傳統的 Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
布隆過濾器原理
布隆過濾器內部維護一個bitArray(位數組), 開始所有數據全部置 0 。當一個元素過來時,能過多個哈希函數(hash2,hash3,hash4....)計算不同的在哈希值,并通過哈希值找到對應的bitArray下標處,將里面的值 0 置為 1 。 需要說明的是,布隆過濾器有一個誤判率的概念,誤判率越低,則數組越長,所占空間越大。誤判率越高則數組越小,所占的空間越小。
下面以網址為例來進行說明, 例如布隆過濾器的初始情況如下圖所示:
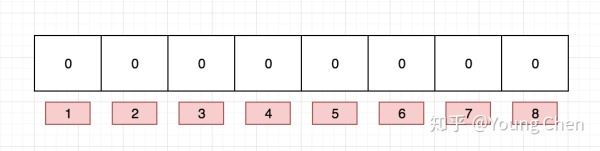
現在我們需要往布隆過濾里中插入baidu這個url,經過3個哈希函數的計算,hash值分別為1,4,7,那么我們就需要對布隆過濾器的對應的bit位置1, 就如圖下所示:
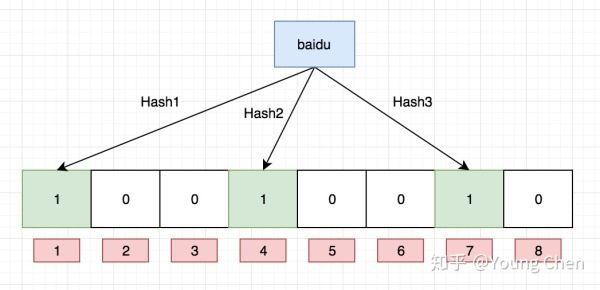
接下來,需要繼續往布隆過濾器中添加tencent這個url,然后它計算出來的hash值分別3,4,8,繼續往對應的bit位置1。這里就需要注意一個點, 上面兩個url最后計算出來的hash值都有4,這個現象也是布隆不能確認某個元素一定存在的原因,最后如下圖所示:
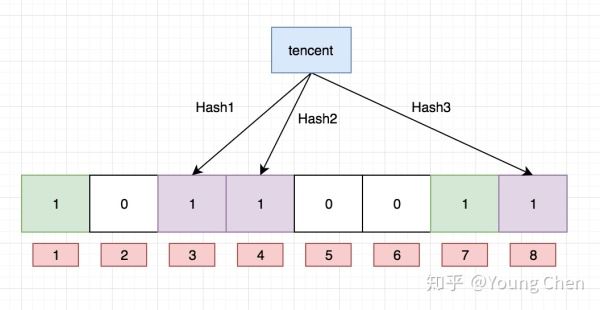
布隆過濾器的查詢也很簡單,例如我們需要查找python,只需要計算出它的hash值, 如果該值為2,4,7,那么因為對應bit位上的數據有一個不為1, 那么一定可以斷言python不存在,但是如果它計算的hash值是1,3,7,那么就只能判斷出python可能存在,這個例子就可以看出來, 我們沒有存入python,但是由于其他key存儲的時候返回的hash值正好將python計算出來的hash值對應的bit位占用了,這樣就不能準確地判斷出python是否存在。
因此, 隨著添加的值越來越多, 被占的bit位越來越多, 這時候誤判的可能性就開始變高,如果布隆過濾器所有bit位都被置為1的話,那么所有key都有可能存在, 這時候布隆過濾器也就失去了過濾的功能。至此,選擇一個合適的過濾器長度就顯得非常重要。
從上面布隆過濾器的實現原理可以看出,它不支持刪除, 一旦將某個key對應的bit位置0,可能會導致同樣bit位的其他key的存在性判斷錯誤。
布隆過濾器的準確性
布隆過濾器的核心思想有兩點:
多個hash,增大隨機性,減少hash碰撞的概率擴大數組范圍,使hash值均勻分布,進一步減少hash碰撞的概率。
雖然布隆過濾器已經盡可能的減小hash碰撞的概率了,但是,并不能徹底消除,因此正如上面的小例子所舉的小例子的結果來看, 布隆過濾器只能告訴我們某樣東西一定不存在以及它可能存在。
關于布隆過濾器的數組大小以及相應的hash函數個數的選擇, 可以參考網上的其他博客或者是這個維基百科上對應詞條上的結果: Probability of false positives .

上圖的縱坐標p是誤判率,橫坐標n表示插入的元素個數,m表示布隆過濾器的bit長度,當然上圖結果成立都假設hash函數的個數k滿足條件k = (m/n)ln2(忽略k是整數)。
從上面的結果來看, 選擇合適后誤判率還是比較低的。
布隆過濾器的應用
網頁爬蟲對URL的去重,避免爬取相同的URL地址
反垃圾郵件,從數十億個垃圾郵件列表中判斷某郵箱是否垃圾郵箱(同理,垃圾短信)
緩存穿透,將所有可能存在的數據緩存放到布隆過濾器中,當黑客訪問不存在的緩存時迅速返回避免緩存及DB掛掉。
黑名單過濾,
二、python中使用布隆過濾器
先去這個網站下載bitarray這個依賴 https://www.lfd.uci.edu/~gohlke/pythonlibs/#bitarray
直接安裝會報錯error: Microsoft Visual C++ 14.0 is required. Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/
安裝wheel文件, 防止我們主動安裝報這樣的錯誤pip3 install bitarray-1.1.0-cp36-cp36m-win_amd64.whl
pip3 install pybloom_live
使用案例:
from pybloom_live import ScalableBloomFilter, BloomFilter # 可自動擴容的布隆過濾器 bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001) url1 = 'http://www.baidu.com' url2 = 'http://qq.com' bloom.add(url1) print(url1 in bloom) print(url2 in bloom) Copy # BloomFilter 是定長的 from pybloom_live import BloomFilter url1 = 'http://www.baidu.com' url2 = 'http://qq.com' bf = BloomFilter(capacity=1000) bf.add(url1) print(url1 in bf) print(url2 in bf)
三、redis中使用布隆過濾器
詳細的文檔可以參考官方文檔。
這個模塊不僅僅實現了布隆過濾器,還實現了 CuckooFilter(布谷鳥過濾器),以及 TopK功能。CuckooFilter是在 BloomFilter的基礎上主要解決了BloomFilter不能刪除的缺點。 下面只說明了布隆過濾器
安裝
傳統的redis服務器安裝 RedisBloom 插件,詳情可以參考centos中安裝redis插件bloom-filter
我這里使用docker進行安裝,簡單快捷。
docker pull redislabs/rebloom:latest docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest docker exec -it redis-redisbloom /bin/bash
命令
命令使用非常簡單。
reserve
bf.reserve {key} {error_rate} {size}創建一個空的名為key的布隆過濾器,并設置一個期望的錯誤率和初始大小。{error_rate}過濾器的錯誤率在0-1之間,
127.0.0.1:6379> bf.reserve black_male 0.001 1000 OK
add, madd
bf.add {key} {item}
bf.madd {key} {item} [item…]
往過濾器中添加元素。如果key不存在,過濾器會自動創建。
127.0.0.1:6379> bf.add test 123 (integer) 1 127.0.0.1:6379> bf.madd urls baidu google tencent 1) (integer) 0 2) (integer) 0 3) (integer) 1 # 上面已經存在的值再次添加會返回0, 不存在則返回1
exists, mexists
bf.exists {key} {item}
bf.mexists {key} {item} [item…]
判斷過濾器中是否存在該元素,不存在返回0,存在返回1。
127.0.0.1:6379> bf.exists test 123 (integer) 1 127.0.0.1:6379> bf.mexists urls baidu google hello 1) (integer) 1 2) (integer) 1 3) (integer) 0
四、python程序中使用redisbloom
使用redisbloom這個模塊來操作redis的布隆過濾器插件
pip3 install redisbloom
使用方法,參考官方給出的例子即可。https://github.com/RedisBloom/redisbloom-py
# 自己的簡單使用
from redisbloom.client import Client
# 因為我使用的是虛擬機中docker的redis, 填寫虛擬機的ip地址和暴露的端口
rb = Client(host='192.168.12.78', port=6379)
rb.bfAdd('urls', 'baidu')
rb.bfAdd('urls', 'google')
print(rb.bfExists('urls', 'baidu')) # out: 1
print(rb.bfExists('urls', 'tencent')) # out: 0
rb.bfMAdd('urls', 'a', 'b')
print(rb.bfMExists('urls', 'google', 'baidu', 'tencent')) # out: [1, 1, 0]誤判率的測試demo
def _test1(size, key='book'): """測試size個不存在的""" rb.delete(key) # 先清空原來的key insert(size, key) select(size, key) def _test2(size, error=0.001, key='book'): """指定誤差率和初始大小的布隆過濾器""" rb.delete(key) rb.bfCreate(key, error, size) # 誤差率為0.1%, 初始個數為size insert(size, key) select(size, key) if __name__ == '__main__': # The default error rate is 0.01 and the default initial capacity is 100. # 這個是默認的配置, 初始大小為100, 誤差率默認為0.01 _test1(1000) _test1(10000) _test1(100000) _test2(500000) Copy # 輸出的結果 插入結束... 花費時間: 0.0409s size: 1000, 誤判元素個數: 14, 誤判率1.4000% 查詢結束... 花費時間: 0.0060s ****************************** 插入結束... 花費時間: 0.1389s size: 10000, 誤判元素個數: 110, 誤判率1.1000% 查詢結束... 花費時間: 0.0628s ****************************** 插入結束... 花費時間: 0.5372s size: 100000, 誤判元素個數: 1419, 誤判率1.4190% 查詢結束... 花費時間: 0.4318s ****************************** 插入結束... 花費時間: 1.9484s size: 500000, 誤判元素個數: 152, 誤判率0.0304% 查詢結束... 花費時間: 2.2177s ******************************
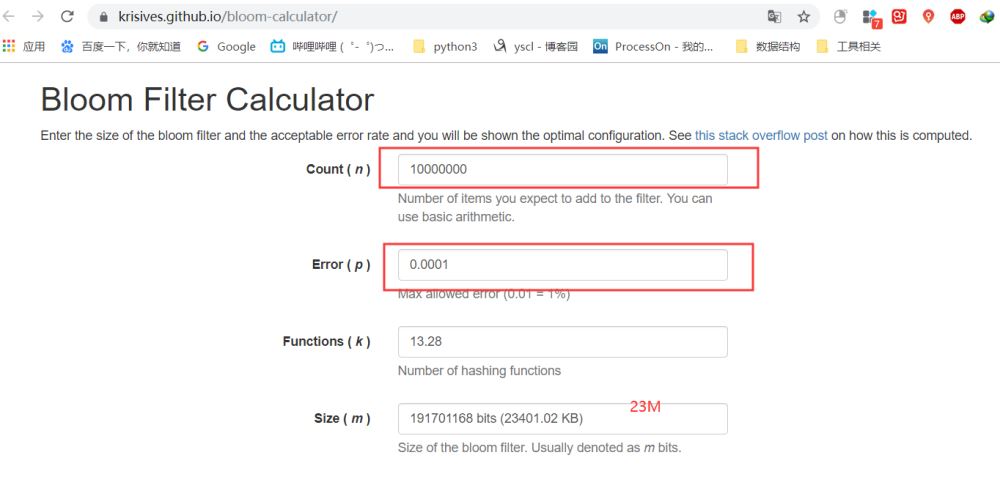
如果想要布隆過濾器知道具體的耗費內存大小以及對應的錯誤率的信息, 可以使用查看這個布隆過濾器計算器計算出最后的結果。就如下面所示, 1kw數據, 誤差為0.01%, 只需要23M內存。
五、緩存擊穿
現在又回到開頭的問題, 解決緩存擊穿的問題。
什么是緩存擊穿
我們通常使用redis作為數據緩存,當請求進來時先通過key去redis緩存查詢,如果緩存中數據不存在,需要去查詢數據庫的數據。當數據庫和緩存中都不存在的數據來查詢時候,請求都打在數據庫的請求中。如果這種請求量很大,會給數據庫造成更大的壓力進而影響系統的性能。
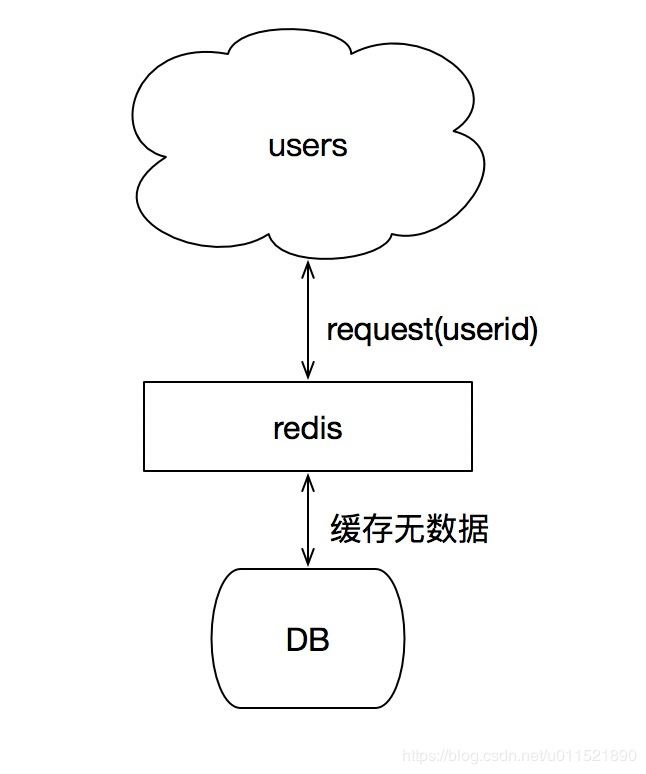
解決這類問題的方法
方法一:當DB和redis中都不存在key,在DB返回null時,在redis中插入`當key再次請求時,redis直接返回null`,而不用再次請求DB。
方法二:使用redis提供的redisbloom,同樣是將存在的key放入到過濾器中。當請求進來時,先去過濾器中校驗是否存在,如果不存在直接返回null。
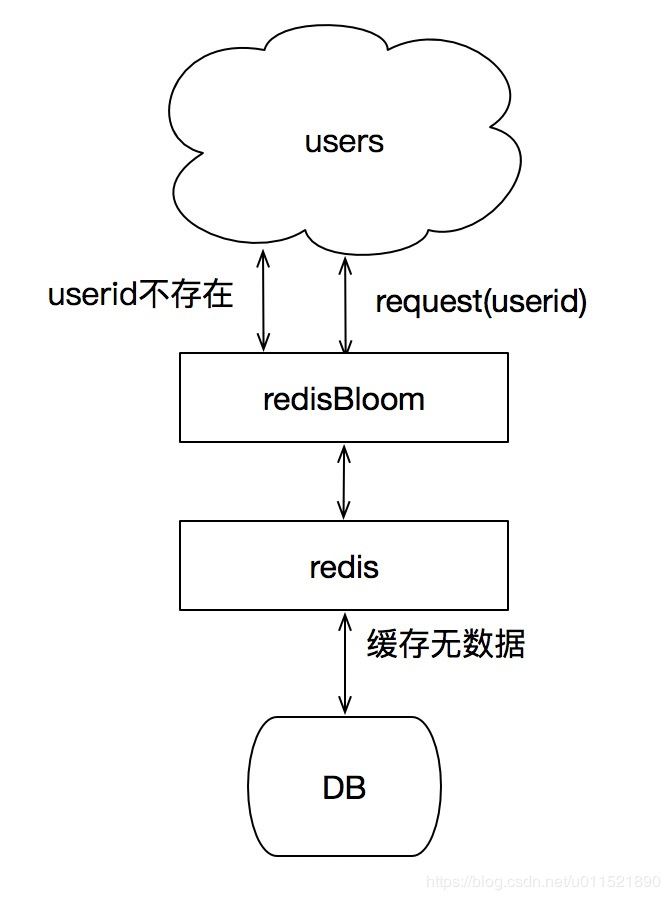
黑名單的小例子
import redis
from redisbloom.client import Client
# 創建一個連接池來進行使用
pool = redis.ConnectionPool(host='192.168.12.78', port=6379, max_connections=100)
def create_key(key, error, capacity):
rb = Client(connection_pool=pool)
rb.bfCreate(key, errorRate=error, capacity=capacity)
def get_item(key, item):
"""判斷是否存在"""
rb = Client(connection_pool=pool)
return rb.bfExists(key, item)
def add_item(key, item):
"""添加值"""
rb = Client(connection_pool=pool)
return rb.bfAdd(key, item)
if __name__ == '__main__':
# 添加黑名單, 誤差為0.001, 大小為1000
create_key('blacklist', 0.001, 1000)
add_item('blacklist', 'user:1')
add_item('blacklist', 'user:2')
add_item('blacklist', 'user:3')
add_item('blacklist', 'user:4')
print('user:1是否在黑名單-> ', get_item('blacklist', 'user:1'))
print('user:2是否在黑名單-> ', get_item('blacklist', 'user:2'))
print('user:6是否在黑名單-> ', get_item('blacklist', 'user:6'))以上是“python如何實現布隆過濾器及原理解析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





