溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關布隆過濾器的工作原理是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
布隆過濾器
布隆過濾器是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 “一定不存在或者可能存在”。
相比于傳統的 List、Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
布隆過濾器的工作原理
假設一個長度為m的bit類型的數組,即數組中每個位置只占一個bit,每個bit只有兩種狀態:0,1,所有bit的初始狀態都為0。
再假設一共有k個哈希函數,這些函數的輸出域大于或者等于m,并且這些哈希函數,彼此之間相互獨立,每個哈希函數計算出來的結果是獨立的,可能相同也可能不相同,對每一個計算出來的結果都對m取余(%m),然后再將數組下標位置置為1。
我們這里假設m為13,k為3的布隆過濾器,來看看布隆過濾器的工作原理:

當我們要映射一個值到布隆過濾器時,首先計算三個哈希函數的值,然后對13取余,映射到對應位中,圖中映射到2,6,10,這樣我們就完成了一個值的映射。
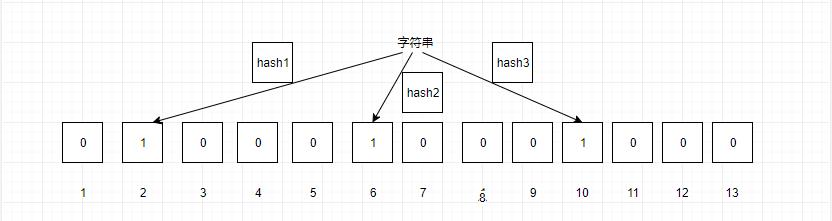
那么怎么判斷一個值是否存在,當一個值輸入時,通過三個哈希函數,然后取余,我們就可以得到對應的三個位置,我們只需要判斷這三個位置是否都為1,如果都為1,則該值存儲,反之不存在。
但是有一個特殊情況,前面說了不同的哈希函數可能計算可能相同也可能不相同,而且不同的哈希函數對不同的值計算出來的值可能一樣,這就造成一個結果,一個值通過哈希和取余得到的位置,早就被其它值給置1了,當我們存儲的值過多,而這個bit數組過小,都會造成這種情況更多的發生,一個值明明不存在,而它的所有位置早就被其它不同值置1,造成了誤判,這里就對布隆過濾器提出了一個指標:失誤率p。
在同樣數據規模下,不同大小的bit數組及不同數量k的哈希函數對誤判率的結果:
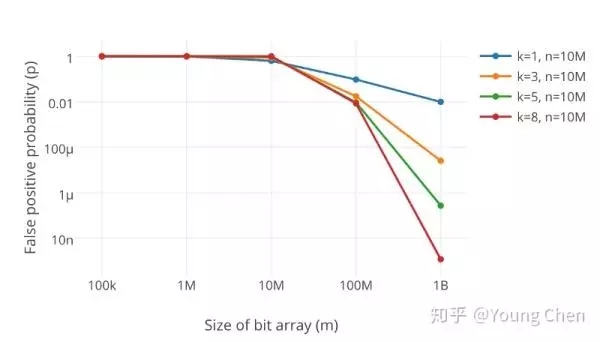
如何選取最合適的m(bit數組的大小)及k(哈希函數的數量),在已知n(需要映射的值得數量)及失誤率p的情況下:
m的選取:
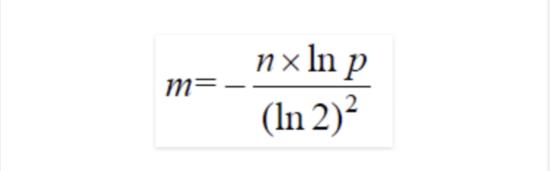
k的選取:

給個例子:假設n=100億,p=0.01%
通過公式計算出來m=19.19n,向上取整位20n,即2000億個bit,也就是25gb。
通過公式計算出來k=14。
計算真實失誤率:

根據公式計算出來的真實失誤率位0.006%。
c語言實現
#include <stdio.h>
#define Size 100
#define BitSIZE Size * 4 * 8
//c語言中一個整型數據類型4個字節
int bit[Size]={0};
int SDBMHash(char *str)
{
unsigned int hash = 0;
while (*str)
{
// equivalent to: hash = 65599*hash + (*str++);
hash = (*str++) + (hash << 6) + (hash << 16) - hash;
}
return (hash & 0x7FFFFFFF);
}
int RSHash(char *str)
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while (*str)
{
hash = hash * a + (*str++);
a *= b;
}
return (hash & 0x7FFFFFFF);
}
int JSHash(char *str)
{
unsigned int hash = 1315423911;
while (*str)
{
hash ^= ((hash << 5) + (*str++) + (hash >> 2));
}
return (hash & 0x7FFFFFFF);
}
void Insert(int hash){
//int value = hash%BitSIZE; ([0-3200]范圍的值)
//int listindex = value / 32; (listindex為數組下標)
//int bitindex = value % 32; (某位)
int value = hash%BitSIZE;
int listindex = value / 32;
int bitindex = value % 32;
int temp = bit[listindex];
bit[listindex] = bit[listindex] & (1 << bitindex);
bit[listindex] = bit[listindex] | temp;
}
int Serach(int hash){
int value = hash%BitSIZE;
int listindex = value / 32;
int bitindex = value % 32;
if (bit[listindex] | (1 << bitindex)){
return 1;
}
return 0;
}
int main () {
char str1[] = "abc123";
//在布隆過濾器中插入某值
Insert(SDBMHash(str1));
Insert(RSHash(str1));
Insert(JSHash(str1));
//在布隆過濾器中判斷某值是否存在
int i = 0;
i = i+Serach(SDBMHash(str1));
i = i+Serach(RSHash(str1));
i = i+Serach(JSHash(str1));
if(i == 3){
printf("字符串:%s存在\n",str1);
}
return 0;
}上述就是小編為大家分享的布隆過濾器的工作原理是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





