溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用pytorch完成kaggle貓狗圖像識別方式,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
kaggle是一個為開發商和數據科學家提供舉辦機器學習競賽、托管數據庫、編寫和分享代碼的平臺,在這上面有非常多的好項目、好資源可供機器學習、深度學習愛好者學習之用。
碰巧最近入門了一門非常的深度學習框架:pytorch,所以今天我和大家一起用pytorch實現一個圖像識別領域的入門項目:貓狗圖像識別。
深度學習的基礎就是數據,咱們先從數據談起。此次使用的貓狗分類圖像一共25000張,貓狗分別有12500張,我們先來簡單的瞅瞅都是一些什么圖片。
我們從下載文件里可以看到有兩個文件夾:train和test,分別用于訓練和測試。以train為例,打開文件夾可以看到非常多的小貓圖片,圖片名字從0.jpg一直編碼到9999.jpg,一共有10000張圖片用于訓練。
而test中的小貓只有2500張。仔細看小貓,可以發現它們姿態不一,有的站著,有的瞇著眼睛,有的甚至和其他可識別物體比如桶、人混在一起。
同時,小貓們的圖片尺寸也不一致,有的是豎放的長方形,有的是橫放的長方形,但我們最終需要是合理尺寸的正方形。小狗的圖片也類似,在這里就不重復了。
緊接著我們了解一下特別適用于圖像識別領域的神經網絡:卷積神經網絡。學習過神經網絡的同學可能或多或少地聽說過卷積神經網絡。這是一種典型的多層神經網絡,擅長處理圖像特別是大圖像的相關機器學習問題。
卷積神經網絡通過一系列的方法,成功地將大數據量的圖像識別問題不斷降維,最終使其能夠被訓練。CNN最早由Yann LeCun提出并應用在手寫體識別上。
一個典型的CNN網絡架構如下:
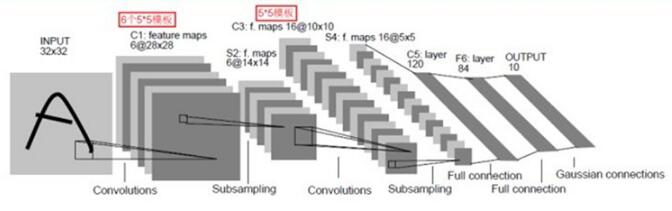
這是一個典型的CNN架構,由卷基層、池化層、全連接層組合而成。其中卷基層與池化層配合,組成多個卷積組,逐層提取特征,最終完成分類。
聽到上述一連串的術語如果你有點蒙了,也別怕,因為這些復雜、抽象的技術都已經在pytorch中一一實現,我們要做的不過是正確的調用相關函數,
我在粘貼代碼后都會做更詳細、易懂的解釋。
import os
import shutil
import torch
import collections
from torchvision import transforms,datasets
from __future__ import print_function, division
import os
import torch
import pylab
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode一個正常的CNN項目所需要的庫還是蠻多的。
import math from PIL import Image class Resize(object): """Resize the input PIL Image to the given size. Args: size (sequence or int): Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size) interpolation (int, optional): Desired interpolation. Default is ``PIL.Image.BILINEAR`` """ def __init__(self, size, interpolation=Image.BILINEAR): # assert isinstance(size, int) or (isinstance(size, collections.Iterable) and len(size) == 2) self.size = size self.interpolation = interpolation def __call__(self, img): w,h = img.size min_edge = min(img.size) rate = min_edge / self.size new_w = math.ceil(w / rate) new_h = math.ceil(h / rate) return img.resize((new_w,new_h))
這個稱為Resize的庫用于給圖像進行縮放操作,本來是不需要親自定義的,因為transforms.Resize已經實現這個功能了,但是由于目前還未知的原因,我的庫里沒有提供這個函數,所以我需要親自實現用來代替transforms.Resize。
如果你的torch里面已經有了這個Resize函數就不用像我這樣了。
data_transform = transforms.Compose([ Resize(84), transforms.CenterCrop(84), transforms.ToTensor(), transforms.Normalize(mean = [0.5,0.5,0.5],std = [0.5,0.5,0.5]) ]) train_dataset = datasets.ImageFolder(root = 'train/',transform = data_transform) train_loader = torch.utils.data.DataLoader(train_dataset,batch_size = 4,shuffle = True,num_workers = 4) test_dataset = datasets.ImageFolder(root = 'test/',transform = data_transform) test_loader = torch.utils.data.DataLoader(test_dataset,batch_size = 4,shuffle = True,num_workers = 4)
transforms是一個提供針對數據(這里指的是圖像)進行轉化的操作庫,Resize就是上上段代碼提供的那個類,主要用于把一張圖片縮放到某個尺寸,在這里我們把需求暫定為要把圖像縮放到84 x 84這個級別,這個就是可供調整的參數,大家為部署好項目以后可以試著修改這個參數,比如改成200 x 200,你就發現你可以去玩一盤游戲了~_~。
CenterCrop用于從中心裁剪圖片,目標是一個長寬都為84的正方形,方便后續的計算。
ToTenser()就比較重要了,這個函數的目的就是讀取圖片像素并且轉化為0-1的數字。
Normalize作為墊底的一步也很關鍵,主要用于把圖片數據集的數值轉化為標準差和均值都為0.5的數據集,這樣數據值就從原來的0到1轉變為-1到1。
class Net(nn.Module): def __init__(self): super(Net,self).__init__() self.conv1 = nn.Conv2d(3,6,5) self.pool = nn.MaxPool2d(2,2) self.conv2 = nn.Conv2d(6,16,5) self.fc1 = nn.Linear(16 * 18 * 18,800) self.fc2 = nn.Linear(800,120) self.fc3 = nn.Linear(120,2) def forward(self,x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1,16 * 18 * 18) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()
好了,最復雜的一步就是這里了。在這里,我們首先定義了一個Net類,它封裝了所以訓練的步驟,包括卷積、池化、激活以及全連接操作。
__init__函數首先定義了所需要的所有函數,這些函數都會在forward中調用。我們從conv1說起。conv1實際上就是定義一個卷積層,3,6,5分別是什么意思?
3代表的是輸入圖像的像素數組的層數,一般來說就是你輸入的圖像的通道數,比如這里使用的小貓圖像都是彩色圖像,由R、G、B三個通道組成,所以數值為3;6代表的是我們希望進行6次卷積,每一次卷積都能生成不同的特征映射數組,用于提取小貓和小狗的6種特征。
每一個特征映射結果最終都會被堆疊在一起形成一個圖像輸出,再作為下一步的輸入;5就是過濾框架的尺寸,表示我們希望用一個5 * 5的矩陣去和圖像中相同尺寸的矩陣進行點乘再相加,形成一個值。
定義好了卷基層,我們接著定義池化層。池化層所做的事說來簡單,其實就是因為大圖片生成的像素矩陣實在太大了,我們需要用一個合理的方法在降維的同時又不失去物體特征,所以深度學習學者們想出了一個稱為池化的技術,說白了就是從左上角開始,每四個元素(2 * 2)合并成一個元素,用這一個元素去代表四個元素的值,所以圖像體積一下子降為原來的四分之一。
再往下一行,我們又一次碰見了一個卷基層:conv2,和conv1一樣,它的輸入也是一個多層像素數組,輸出也是一個多層像素數組,不同的是這一次完成的計算量更大了,我們看這里面的參數分別是6,16,5。
之所以為6是因為conv1的輸出層數為6,所以這里輸入的層數就是6;16代表conv2的輸出層數,和conv1一樣,16代表著這一次卷積操作將會學習小貓小狗的16種映射特征,特征越多理論上能學習的效果就越好,大家可以嘗試一下別的值,看看效果是否真的編變好。
conv2使用的過濾框尺寸和conv1一樣,所以不再重復。最后三行代碼都是用于定義全連接網絡的,接觸過神經網絡的應該就不再陌生了,主要是需要解釋一下fc1。
之前在學習的時候比較不理解的也是這一行,為什么是16 * 18 * 18呢?16很好理解,因為最后一次卷積生成的圖像矩陣的高度就是16層,那18 * 18是怎么來的呢?我們回過頭去看一行代碼
transforms.CenterCrop(84)
在這行代碼里我們把訓練圖像裁剪成一個84 * 84的正方形尺寸,所以圖像最早輸入就是一個3 * 84 * 84的數組。經過第一次5 * 5的卷積之后,我們可以得出卷積的結果是一個6 * 80 * 80的矩陣,這里的80就是因為我們使用了一個5 * 5的過濾框,當它從左上角第一個元素開始卷積后,過濾框的中心是從2到78,并不是從0到79,所以結果就是一個80 * 80的圖像了。
經過一個池化層之后,圖像尺寸的寬和高都分別縮小到原來的1/2,所以變成40 * 40。
緊接著又進行了一次卷積,和上一次一樣,長寬都減掉4,變成36 * 36,然后應用了最后一層的池化,最終尺寸就是18 * 18。
所以第一層全連接層的輸入數據的尺寸是16 * 18 * 18。三個全連接層所做的事很類似,就是不斷訓練,最后輸出一個二分類數值。
net類的forward函數表示前向計算的整個過程。forward接受一個input,返回一個網絡輸出值,中間的過程就是一個調用init函數中定義的層的過程。
F.relu是一個激活函數,把所有的非零值轉化成零值。此次圖像識別的最后關鍵一步就是真正的循環訓練操作。
import torch.optim as optim
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.0001,momentum = 0.9)
for epoch in range(3):
running_loss = 0.0
for i,data in enumerate(train_loader,0):
inputs,labels = data
inputs,labels = Variable(inputs),Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = cirterion(outputs,labels)
loss.backward()
optimizer.step()
running_loss += loss.data[0]
if i % 2000 == 1999:
print('[%d %5d] loss: %.3f' % (epoch + 1,i + 1,running_loss / 2000))
running_loss = 0.0
print('finished training!')[1 2000] loss: 0.691 [1 4000] loss: 0.687 [2 2000] loss: 0.671 [2 4000] loss: 0.657 [3 2000] loss: 0.628 [3 4000] loss: 0.626 finished training!
在這里我們進行了三次訓練,每次訓練都是批量獲取train_loader中的訓練數據、梯度清零、計算輸出值、計算誤差、反向傳播并修正模型。我們以每2000次計算的平均誤差作為觀察值。可以看到每次訓練,誤差值都在不斷變小,逐漸學習如何分類圖像。代碼相對性易懂,這里就不再贅述了。
correct = 0
total = 0
for data in test_loader:
images,labels = data
outputs = net(Variable(images))
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 5000 test images: %d %%' % (100 * correct / total))終于來到模型準確度驗證了,這也是開篇提到的test文件夾的用途之所在。程序到這一步時,net是一個已經訓練好的神經網絡了。傳入一個images矩陣,它會輸出相應的分類值,我們拿到這個分類值與真實值做一個比較計算,就可以獲得準確率。在我的計算機上當前準確率是66%,在你的機器上可能值有所不同但不會相差太大。
最后我們做一個小總結。在pytorch中實現CNN其實并不復雜,理論性的底層都已經完成封裝,我們只需要調用正確的函數即可。當前模型中的各個參數都沒有達到相對完美的狀態,有興趣的小伙伴可以多調整參數跑幾次,訓練結果不出意外會越來越好。
另外,由于在一篇文章中既要闡述CNN,又要貼項目代碼會顯得沒有重點,我就沒有兩件事同時做,因為網上已經有很多很好的解釋CNN的文章了,如果看了代碼依然是滿頭霧水的小伙伴可以先去搜關于CNN的文章,再回過頭來看項目代碼應該會更加清晰。
關于“如何使用pytorch完成kaggle貓狗圖像識別方式”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





