溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下怎么使用Pytorch完成圖像分類任務的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
深度學習的基礎就是數據,完成圖像分類,當然數據也必不可少。先使用爬蟲爬取陽臺圖片1200張以及非陽臺圖片1200張,圖片的名字從0.jpg一直編到2400.jpg,把爬取的圖片放置在同一個文件夾中命名為image。
針對百度圖片的爬蟲代碼也放上,方便大家使用,代碼可以爬取任意自定義的圖片:
import requests
import os
import urllib
class Spider_baidu_image():
def __init__(self):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36'}
self.headers_image = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36',
'Referer': 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1557124645631_R&pv=&ic=&nc=1&z=&hd=1&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E8%83%A1%E6%AD%8C'}
self.keyword = input("請輸入搜索圖片關鍵字:")
self.paginator = int(input("請輸入搜索頁數,每頁30張圖片:"))
def get_param(self):
"""
獲取url請求的參數,存入列表并返回
:return:
"""
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1, self.paginator + 1):
params.append(
'tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0©right=0&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=star&pn={}&rn=30&gsm=78&1557125391211='.format(
keyword, keyword, 30 * i))
return params
def get_urls(self, params):
"""
由url參數返回各個url拼接后的響應,存入列表并返回
:return:
"""
urls = []
for i in params:
urls.append(self.url + i)
return urls
def get_image_url(self, urls):
image_url = []
for url in urls:
json_data = requests.get(url, headers=self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self, image_url):
"""
根據圖片url,在本地目錄下新建一個以搜索關鍵字命名的文件夾,然后將每一個圖片存入。
:param image_url:
:return:
"""
cwd = os.getcwd()
file_name = os.path.join(cwd, self.keyword)
if not os.path.exists(self.keyword):
os.mkdir(file_name)
for index, url in enumerate(image_url, start=1):
with open(file_name + '\\{}.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=self.headers_image).content)
if index != 0 and index % 30 == 0:
print('{}第{}頁下載完成'.format(self.keyword, index / 30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url)
if __name__ == '__main__':
spider = Spider_baidu_image()
spider()每個圖片要加上對應的標簽,那么在txt文檔當中,選取圖片的名稱,在其后加上標簽。如果是陽臺,則標簽為1,如果不是陽臺,則標簽為0。在2400張圖片中,分成兩個txt文檔為訓練集和驗證集“train.txt”和“val.txt”(如下圖2,3所示)

圖2

圖3
通過觀察自己爬取的圖片,可以發現陽臺各式各樣,有的半開放,有的是封閉式的,有的甚至和其他可識別物體花,草混在一起。同時,圖片尺寸也不一致,有的是豎放的長方形,有的是橫放的長方形,但我們最終需要是合理尺寸的正方形。所以我們使用Resize的庫用于給圖像進行縮放操作,我這里把圖片縮放到84*84的級別。除縮放操作以外還需對數據進行預處理:
torchvision.transforms是pytorch中的圖像預處理包
一般用Compose把多個步驟整合到一起:
比如說
transforms.Compose([ transforms.CenterCrop(84), transforms.ToTensor(), ])
這樣就把兩個步驟整合到一起
CenterCrop用于從中心裁剪圖片,目標是一個長寬都為84的正方形,方便后續的計算。除CenterCrop外補充一個RandomCrop是在一個隨機的位置進行裁剪。
ToTenser()這個函數的目的就是讀取圖片像素并且轉化為0-1的數字(進行歸一化操作)。
代碼如下:
data_transforms = {
'train': transforms.Compose([
transforms.Resize(84),
transforms.CenterCrop(84),
# 轉換成tensor向量
transforms.ToTensor(),
# 對圖像進行歸一化操作
# [0.485, 0.456, 0.406],RGB通道的均值與標準差
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(84),
transforms.CenterCrop(84),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}解決對圖像的處理過后,想要開始訓練網絡模型,首先要解決的就是圖像數據的讀入,Pytorch使用DataLoader來實現圖像數據讀入,代碼如下:
class my_Data_Set(nn.Module):
def __init__(self, txt, transform=None, target_transform=None, loader=None):
super(my_Data_Set, self).__init__()
# 打開存儲圖像名與標簽的txt文件
fp = open(txt, 'r')
images = []
labels = []
# 將圖像名和圖像標簽對應存儲起來
for line in fp:
line.strip('\n')
line.rstrip()
information = line.split()
images.append(information[0])
labels.append(int(information[1]))
self.images = images
self.labels = labels
self.transform = transform
self.target_transform = target_transform
self.loader = loader
# 重寫這個函數用來進行圖像數據的讀取
def __getitem__(self, item):
# 獲取圖像名和標簽
imageName = self.images[item]
label = self.labels[item]
# 讀入圖像信息
image = self.loader(imageName)
# 處理圖像數據
if self.transform is not None:
image = self.transform(image)
return image, label
# 重寫這個函數,來看數據集中含有多少數據
def __len__(self):
return len(self.images)
# 生成Pytorch所需的DataLoader數據輸入格式
train_dataset = my_Data_Set('train.txt', transform=data_transforms['train'], loader=Load_Image_Information)
test_dataset = my_Data_Set('val.txt', transform=data_transforms['val'], loader=Load_Image_Information)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10, shuffle=True)可驗證是否生成了DataLoader格式數據:
# 驗證是否生成DataLoader格式數據 for data in train_loader: inputs, labels = data print(inputs) print(labels) for data in test_loader: inputs, labels = data print(inputs) print(labels)
卷積神經網絡一種典型的多層神經網絡,擅長處理圖像特別是大圖像的相關機器學習問題。卷積神經網絡通過一系列的方法,成功地將大數據量的圖像識別問題不斷降維,最終使其能夠被訓練。卷積神經網絡(CNN)最早由Yann LeCun提出并應用在手寫體識別上。
一個典型的CNN網絡架構如下圖4:
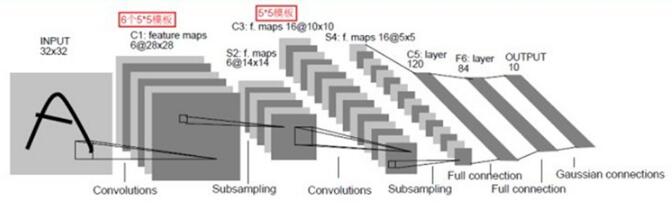
圖4
首先導入Python需要的庫:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset
import numpy as np
import os
from PIL import Image
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.ion()定義一個卷積神經網絡:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 18 * 18, 800) self.fc2 = nn.Linear(800, 120) self.fc3 = nn.Linear(120, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 18 * 18) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()
我們首先定義了一個Net類,它封裝了所以訓練的步驟,包括卷積、池化、激活以及全連接操作。
__init__函數首先定義了所需要的所有函數,這些函數都會在forward中調用。從conv1說起,conv1實際上就是定義一個卷積層,3代表的是輸入圖像的像素數組的層數,一般來說就是輸入的圖像的通道數,比如這里使用的圖像都是彩色圖像,由R、G、B三個通道組成,所以數值為3;6代表的是我們希望進行6次卷積,每一次卷積都能生成不同的特征映射數組,用于提取圖像的6種特征。每一個特征映射結果最終都會被堆疊在一起形成一個圖像輸出,再作為下一步的輸入;5就是過濾框架的尺寸,表示我們希望用一個5 *5的矩陣去和圖像中相同尺寸的矩陣進行點乘再相加,形成一個值。定義好了卷基層,我們接著定義池化層。池化層所做的事說來簡單,其實就是因為大圖片生成的像素矩陣實在太大了,我們需要用一個合理的方法在降維的同時又不失去物體特征,所以使用池化的技術,每四個元素合并成一個元素,用這一個元素去代表四個元素的值,所以圖像體積會降為原來的四分之一。再往下一行,我們又一次碰見了一個卷基層:conv2,和conv1一樣,它的輸入也是一個多層像素數組,輸出也是一個多層像素數組,不同的是這一次完成的計算量更大了,我們看這里面的參數分別是6,16,5。之所以為6是因為conv1的輸出層數為6,所以這里輸入的層數就是6;16代表conv2的輸出層數,和conv1一樣,16代表著這一次卷積操作將會學習圖片的16種映射特征,特征越多理論上能學習的效果就越好。conv2使用的過濾框尺寸和conv1一樣,所以不再重復。
對于fc1,16很好理解,因為最后一次卷積生成的圖像矩陣的高度就是16層,前面我們把訓練圖像裁剪成一個84 * 84的正方形尺寸,所以圖像最早輸入就是一個3 * 84 * 84的數組。經過第一次5 *5的卷積之后,我們可以得出卷積的結果是一個6 * 80 * 80的矩陣,這里的80就是因為我們使用了一個5 *5的過濾框,當它從左上角第一個元素開始卷積后,過濾框的中心是從2到78,并不是從0到79,所以結果就是一個80 * 80的圖像了。經過一個池化層之后,圖像尺寸的寬和高都分別縮小到原來的1/2,所以變成40 * 40。緊接著又進行了一次卷積,和上一次一樣,長寬都減掉4,變成36 * 36,然后應用了最后一層的池化,最終尺寸就是18 * 18。所以第一層全連接層的輸入數據的尺寸是16 * 18 * 18。三個全連接層所做的事很類似,就是不斷訓練,最后輸出一個二分類數值。
net類的forward函數表示前向計算的整個過程。forward接受一個input,返回一個網絡輸出值,中間的過程就是一個調用init函數中定義的層的過程。
F.relu是一個激活函數,把所有的非零值轉化成零值。此次圖像識別的最后關鍵一步就是真正的循環訓練操作。
#訓練
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.5)
for epoch in range(50):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad() # 優化器清零
outputs = net(inputs)
loss = cirterion(outputs, labels)
loss.backward()
optimizer.step() #優化
running_loss += loss.item()
if i % 200 == 199:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('finished training!')在這里我們進行了50次訓練,每次訓練都是批量獲取train_loader中的訓練數據、梯度清零、計算輸出值、計算誤差、反向傳播并修正模型。我們以每200次計算的平均誤差作為觀察值。
下面進行測試環節:
#測試
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 400 test images: %d %%' % (100 * correct / total))最后會得到一個識別的準確率。
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset
import numpy as np
import os
from PIL import Image
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.ion()
data_transforms = {
'train': transforms.Compose([
transforms.Resize(84),
transforms.CenterCrop(84),
# 轉換成tensor向量
transforms.ToTensor(),
# 對圖像進行歸一化操作
# [0.485, 0.456, 0.406],RGB通道的均值與標準差
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(84),
transforms.CenterCrop(84),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
def Load_Image_Information(path):
# 圖像存儲路徑
image_Root_Dir= r'C:/Users/wbl/Desktop/pythonProject1/image/'
# 獲取圖像的路徑
iamge_Dir = os.path.join(image_Root_Dir, path)
# 以RGB格式打開圖像
# Pytorch DataLoader就是使用PIL所讀取的圖像格式
return Image.open(iamge_Dir).convert('RGB')
class my_Data_Set(nn.Module):
def __init__(self, txt, transform=None, target_transform=None, loader=None):
super(my_Data_Set, self).__init__()
# 打開存儲圖像名與標簽的txt文件
fp = open(txt, 'r')
images = []
labels = []
# 將圖像名和圖像標簽對應存儲起來
for line in fp:
line.strip('\n')
line.rstrip()
information = line.split()
images.append(information[0])
labels.append(int(information[1]))
self.images = images
self.labels = labels
self.transform = transform
self.target_transform = target_transform
self.loader = loader
# 重寫這個函數用來進行圖像數據的讀取
def __getitem__(self, item):
# 獲取圖像名和標簽
imageName = self.images[item]
label = self.labels[item]
# 讀入圖像信息
image = self.loader(imageName)
# 處理圖像數據
if self.transform is not None:
image = self.transform(image)
return image, label
# 重寫這個函數,來看數據集中含有多少數據
def __len__(self):
return len(self.images)
# 生成Pytorch所需的DataLoader數據輸入格式
train_dataset = my_Data_Set('train.txt', transform=data_transforms['train'], loader=Load_Image_Information)
test_dataset = my_Data_Set('val.txt', transform=data_transforms['val'], loader=Load_Image_Information)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10, shuffle=True)
'''
# 驗證是否生成DataLoader格式數據
for data in train_loader:
inputs, labels = data
print(inputs)
print(labels)
for data in test_loader:
inputs, labels = data
print(inputs)
print(labels)
'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 18 * 18, 800)
self.fc2 = nn.Linear(800, 120)
self.fc3 = nn.Linear(120, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 18 * 18)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
#訓練
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.5)
for epoch in range(50):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad() # 優化器清零
outputs = net(inputs)
loss = cirterion(outputs, labels)
loss.backward()
optimizer.step() #優化
running_loss += loss.item()
if i % 200 == 199:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('finished training!')
#測試
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 400 test images: %d %%' % (100 * correct / total))以上就是“怎么使用Pytorch完成圖像分類任務”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





