溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
概述
本文主要介紹一種降維方法,PCA(Principal Component Analysis,主成分分析)。降維致力于解決三類問題。
1. 降維可以緩解維度災難問題;
2. 降維可以在壓縮數據的同時讓信息損失最小化;
3. 理解幾百個維度的數據結構很困難,兩三個維度的數據通過可視化更容易理解。
PCA簡介
在理解特征提取與處理時,涉及高維特征向量的問題往往容易陷入維度災難。隨著數據集維度的增加,算法學習需要的樣本數量呈指數級增加。有些應用中,遇到這樣的大數據是非常不利的,而且從大數據集中學習需要更多的內存和處理能力。另外,隨著維度的增加,數據的稀疏性會越來越高。在高維向量空間中探索同樣的數據集比在同樣稀疏的數據集中探索更加困難。
主成分分析也稱為卡爾胡寧-勒夫變換(Karhunen-Loeve Transform),是一種用于探索高維數據結構的技術。PCA通常用于高維數據集的探索與可視化。還可以用于數據壓縮,數據預處理等。PCA可以把可能具有相關性的高維變量合成線性無關的低維變量,稱為主成分( principal components)。新的低維數據集會盡可能的保留原始數據的變量。
PCA將數據投射到一個低維子空間實現降維。例如,二維數據集降維就是把點投射成一條線,數據集的每個樣本都可以用一個值表示,不需要兩個值。三維數據集可以降成二維,就是把變量映射成一個平面。一般情況下,nn維數據集可以通過映射降成kk維子空間,其中k≤nk≤n。
假如你是一本養花工具宣傳冊的攝影師,你正在拍攝一個水壺。水壺是三維的,但是照片是二維的,為了更全面的把水壺展示給客戶,你需要從不同角度拍幾張圖片。下圖是你從四個方向拍的照片:

第一張圖里水壺的背面可以看到,但是看不到前面。第二張圖是拍前面,可以看到壺嘴,這張圖可以提供了第一張圖缺失的信息,但是壺把看不到了。從第三張俯視圖里無法看出壺的高度。第四張圖是你真正想要的,水壺的高度,頂部,壺嘴和壺把都清晰可見。
PCA的設計理念與此類似,它可以將高維數據集映射到低維空間的同時,盡可能的保留更多變量。PCA旋轉數據集與其主成分對齊,將最多的變量保留到第一主成分中。假設我們有下圖所示的數據集:
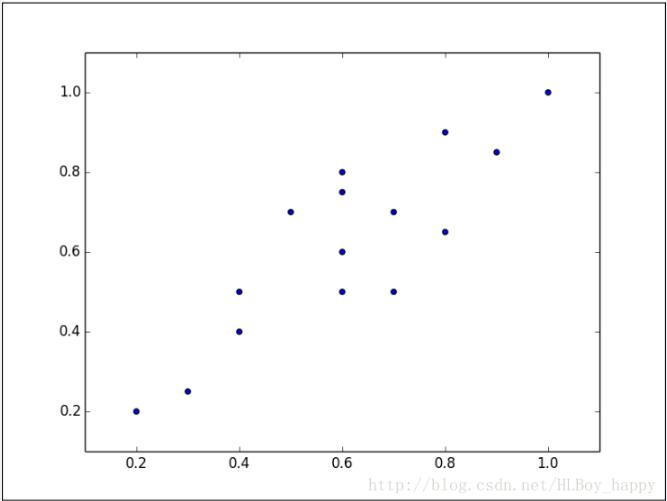
數據集看起來像一個從原點到右上角延伸的細長扁平的橢圓。要降低整個數據集的維度,我們必須把點映射成一條線。下圖中的兩條線都是數據集可以映射的,映射到哪條線樣本變化最大?
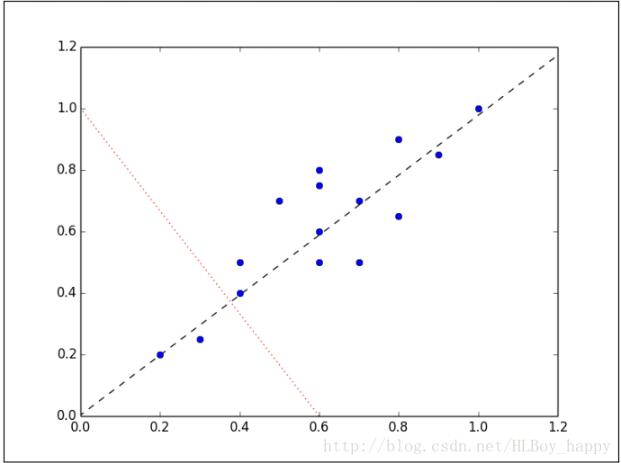
顯然,樣本映射到黑色虛線的變化比映射到紅色點線的變化要大的多。實際上,這條黑色虛線就是第一主成分。第二主成分必須與第一主成分正交,也就是說第二主成分必須是在統計學上獨立的,會出現在與第一主成分垂直的方向,如下圖所示:
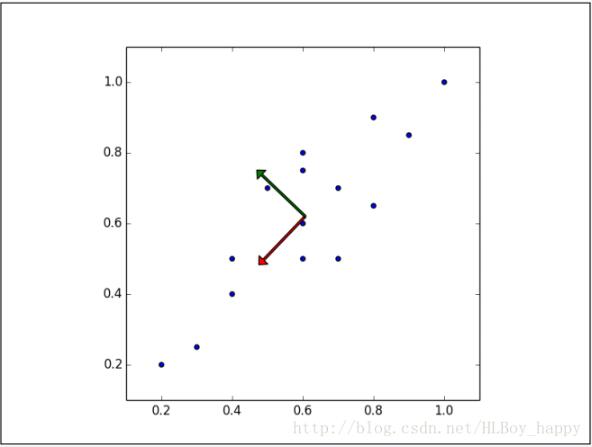
后面的每個主成分也會盡量多的保留剩下的變量,唯一的要求就是每一個主成分需要和前面的主成分正交。
現在假設數據集是三維的,散點圖看起來像是沿著一個軸旋轉的圓盤。
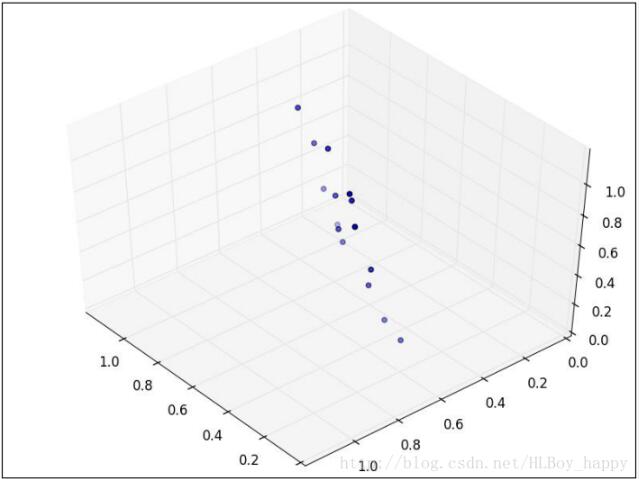
這些點可以通過旋轉和變換使圓盤完全變成二維的。現在這些點看著像一個橢圓,第三維上基本沒有變量,可以被忽略。
當數據集不同維度上的方差分布不均勻的時候,PCA最有用。(如果是一個球殼形數據集,PCA不能有效的發揮作用,因為各個方向上的方差都相等;沒有丟失大量的信息維度一個都不能忽略)。
python實現PCA降維代碼
# coding=utf-8
from sklearn.decomposition import PCA
from pandas.core.frame import DataFrame
import pandas as pd
import numpy as np
l=[]
with open('test.csv','r') as fd:
line= fd.readline()
while line:
if line =="":
continue
line = line.strip()
word = line.split(",")
l.append(word)
line= fd.readline()
data_l=DataFrame(l)
print (data_l)
dataMat = np.array(data_l)
pca_sk = PCA(n_components=2)
newMat = pca_sk.fit_transform(dataMat)
data1 = DataFrame(newMat)
data1.to_csv('test_PCA.csv',index=False,header=False)
以上這篇python實現PCA降維的示例詳解就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





