溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、爬蟲時,出現urllib.error.HTTPError: HTTP Error 403: Forbidden
Traceback (most recent call last): File "D:/訪問web.py", line 75, in <module> downHtml(url=url) File "D:/urllib訪問web.py", line 44, in downHtml html=request.urlretrieve(url=url,filename='%s/%s.txt'%(savedir,get_domain_url(url=url))) File "C:\Python35\lib\urllib\request.py", line 187, in urlretrieve with contextlib.closing(urlopen(url, data)) as fp: File "C:\Python35\lib\urllib\request.py", line 162, in urlopen return opener.open(url, data, timeout) File "C:\Python35\lib\urllib\request.py", line 471, in open response = meth(req, response) File "C:\Python35\lib\urllib\request.py", line 581, in http_response 'http', request, response, code, msg, hdrs) File "C:\Python35\lib\urllib\request.py", line 503, in error result = self._call_chain(*args) File "C:\Python35\lib\urllib\request.py", line 443, in _call_chain result = func(*args) File "C:\Python35\lib\urllib\request.py", line 686, in http_error_302 return self.parent.open(new, timeout=req.timeout) File "C:\Python35\lib\urllib\request.py", line 471, in open response = meth(req, response) File "C:\Python35\lib\urllib\request.py", line 581, in http_response 'http', request, response, code, msg, hdrs) File "C:\Python35\lib\urllib\request.py", line 509, in error return self._call_chain(*args) File "C:\Python35\lib\urllib\request.py", line 443, in _call_chain result = func(*args) File "C:\Python35\lib\urllib\request.py", line 589, in http_error_default raise HTTPError(req.full_url, code, msg, hdrs, fp) urllib.error.HTTPError: HTTP Error 403: Forbidden
二、分析:
之所以出現上面的異常,是因為如果用 urllib.request.urlopen 方式打開一個URL,服務器端只會收到一個單純的對于該頁面訪問的請求,但是服務器并不知道發送這個請求使用的瀏覽器,操作系統,硬件平臺等信息,而缺失這些信息的請求往往都是非正常的訪問,例如爬蟲.有些網站為了防止這種非正常的訪問,會驗證請求信息中的UserAgent(它的信息包括硬件平臺、系統軟件、應用軟件和用戶個人偏好),如果UserAgent存在異常或者是不存在,那么這次請求將會被拒絕(如上錯誤信息所示)所以可以嘗試在請求中加入UserAgent的信息
三、方案:
對于Python 3.x來說,在請求中添加UserAgent的信息非常簡單,代碼如下
#如果不加上下面的這行出現會出現urllib.error.HTTPError: HTTP Error 403: Forbidden錯誤
#主要是由于該網站禁止爬蟲導致的,可以在請求加上頭信息,偽裝成瀏覽器訪問User-Agent,具體的信息可以通過火狐的FireBug插件查詢
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
req = urllib.request.Request(url=chaper_url, headers=headers)
urllib.request.urlopen(req).read()而使用request.urlretrieve庫下載時,如下解決:
opener=request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36')]
request.install_opener(opener)
request.urlretrieve(url=url,filename='%s/%s.txt'%(savedir,get_domain_url(url=url)))四、效果圖:
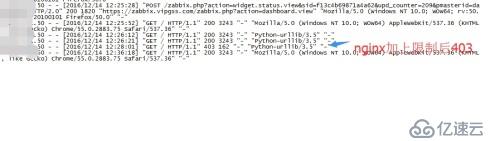
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





