溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
ArrayList源碼分析--jdk1.8
LinkedList源碼分析--jdk1.8
HashMap源碼分析--jdk1.8
AQS源碼分析--jdk1.8
ReentrantLock源碼分析--jdk1.8
??1. HashMap是可以動態擴容的數組,基于數組、鏈表、紅黑樹實現的集合。
??2. HashMap支持鍵值對取值、克隆、序列化,元素無序,key不可重復value可重復,都可為null。
??3. HashMap初始默認長度16,超出擴容2倍,填充因子0.75f。
??4.HashMap當鏈表的長度大于8的且數組大小大于64時,鏈表結構轉變為紅黑樹結構。
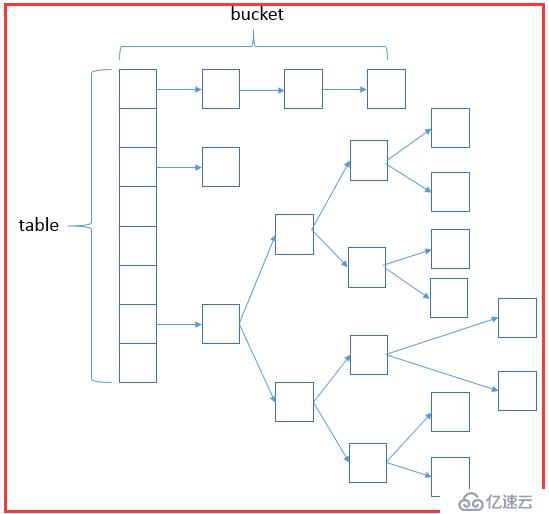
??數據結構是集合的精華所在,數據結構往往也限制了集合的作用和側重點,了解各種數據結構是我們分析源碼的必經之路。
??HashMap的數據結構如下:數組+鏈表+紅黑樹
/*
* 用數組+鏈表+紅黑樹實現的集合,支持鍵值對查找
*/
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/**
* 默認初始容量-必須是2的冪
* 1*2的4次方 默認長度16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* 最大容量
* 1*2的30次方 最大容量1073741824
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默認的填充因子 0.75
* 負載因子0.75是對空間和時間效率的一個平衡選擇,建議大家不要修改,除非在時間和空間比較特殊的情況下,
* 如果內存空間很多而又對時間效率要求很高,可以降低負載因子Load factor的值;
* 相反,如果內存空間緊張而對時間效率要求不高,可以增加負載因子loadFactor的值,這個值可以大于1
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 當桶(bucket)上的節點數大于這個值時會轉成紅黑樹
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 當桶(bucket)上的節點數小于這個值時樹轉鏈表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 桶中結構轉化為紅黑樹對應的table的最小大小
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Node是單向鏈表,它實現了Map.Entry接口
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//構造函數Hash值 鍵 值 下一個節點
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
// 實現接口定義的方法,且該方法不可被重寫
// 設值,返回舊值
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//構造函數Hash值 鍵 值 下一個節點
/*
* 重寫父類Object的equals方法,且該方法不可被自己的子類再重寫
* 判斷相等的依據是,只要是Map.Entry的一個實例,并且鍵鍵、值值都相等就返回True
*/
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
/**
*使用默認初始容量(16)和默認加載因子(0.75)構造一個空的 HashMap
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* 使用默認加載因子0.75f,容量使用參數initialCapacity
*/
public HashMap(int initialCapacity) {
// 調用HashMap(int, float)型構造函數
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* @param initialCapacity the initial capacity 初始容量
* @param loadFactor the load factor 加載因子
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否則報錯
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否則為最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能為非數字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 初始化threshold大小
this.threshold = tableSizeFor(initialCapacity);
}
/**
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 將m中的所有元素添加至HashMap中
putMapEntries(m, false);
}
/**
* Returns a power of two size for the given target capacity.
* 返回大于initialCapacity的最小的二次冪數值
* 16 32 64 128
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
?? HashMap extends AbstractMap
?? AbstractMap extends Object
??java中所有類都繼承Object,所以HashMap的繼承結構如上圖。
?? 1. AbstractMap是一個抽象類,實現了Map<K,V>接口,Map<K,V>定義了一些Map(K,V)鍵值對通用方法,而AbstractMap抽象類中可以有抽象方法,還可以有具體的實現方法,AbstractMap實現接口中一些通用的方法,實現了基礎的/get/remove/containsKey/containsValue/keySet方法,HashMap再繼承AbstractMap,拿到通用基礎的方法,然后自己在實現一些自己特有的方法,這樣的好處是:讓代碼更簡潔,繼承結構最底層的類中通用的方法,減少重復代碼,從上往下,從抽象到具體,越來越豐富,可復用。
?? 2.HashMap實現了Map<K,V>、Cloneable、Serializable接口
?? ??1)Map<K,V>接口,定義了Map鍵值對通用的方法,1.8中為了加強接口的能力,使得接口可以存在具體的方法,前提是方法需要被default或static關鍵字所修飾,Map中實現了一些通用方法實現,使接口更加抽象。
?? ??2)Cloneable接口,可以使用Object.Clone()方法。
?? ??3)Serializable接口,序列化接口,表明該類可以被序列化,什么是序列化?簡單的說,就是能夠從類變成字節流傳輸,反序列化,就是從字節流變成原來的類




?? ??1)V put(K key, V value);//map添加元素
/**
* 新增元素
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* onlyIfAbsent默認傳false,覆蓋更改現有值
* onlyIfAbsent傳true,不覆蓋更改現有值
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果table為空 或者 長度為0
if ((tab = table) == null || (n = tab.length) == 0)
//擴容
n = (tab = resize()).length;
//計算index,并對null做處理
// (n - 1) & hash 確定元素存放在哪個桶中,桶為空,新生成結點放入桶中(此時,這個結點是放在數組中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已經存在元素
else {
Node<K,V> e; K k;
//如果key存在 直接覆蓋 value
// 比較桶中第一個元素(數組中的結點)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 將第一個元素賦值給e,用e來記錄
e = p;
//如果table[i]是紅黑樹 直接在紅黑樹中插入
// hash值不相等,即key不相等;為紅黑樹結點
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果是鏈表 則遍歷鏈表
else {
// 在鏈表最末插入結點
for (int binCount = 0; ; ++binCount) {
// 到達鏈表的尾部
if ((e = p.next) == null) {
// 在尾部插入新結點
p.next = newNode(hash, key, value, null);
// 結點數量達到閾值,轉化為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循環
break;
}
// 判斷鏈表中結點的key值與插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循環
break;
// 用于遍歷桶中的鏈表,與前面的e = p.next組合,可以遍歷鏈表
p = e;
}
}
// 表示在桶中找到key值、hash值與插入元素相等的結點
if (e != null) { // existing mapping for key
// 記錄e的value
V oldValue = e.value;
// onlyIfAbsent為false或者舊值為null
if (!onlyIfAbsent || oldValue == null)
//用新值替換舊值
e.value = value;
// 訪問后回調
afterNodeAccess(e);
// 返回舊值
return oldValue;
}
}
// 結構性修改
++modCount;
// 實際大小大于閾值則擴容
if (++size > threshold)
resize();
// 插入后回調,用來回調移除最早放入Map的對象(LinkedHashMap中實現了,HashMap中為空實現)
afterNodeInsertion(evict);
return null;
}
static final int hash(Object key) {
int h;
// h = key.hashCode() 為第一步 取hashCode值
// h ^ (h >>> 16) 為第二步 高位參與運算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}?? ??2)putAll(Map<? extends K, ? extends V> m);//添加Map全部元素
/**
* 添加Map全部元素
*/
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
/**
* Implements Map.putAll and Map constructor
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判斷table是否已經初始化
if (table == null) { // pre-size
// 未初始化,s為m的實際元素個數
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 計算得到的t大于閾值,則初始化閾值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素個數大于閾值,進行擴容處理
else if (s > threshold)
resize();
// 將m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
/**
* 擴容
* ①.在jdk1.8中,resize方法是在hashmap中的鍵值對大于閥值時或者初始化時,就調用resize方法進行擴容;
* ②.每次擴展的時候,都是擴展2倍:16、32、64、128...
* ③.擴展后Node對象的位置要么在原位置,要么移動到原偏移量兩倍(2次冪)的位置。
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶數組
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap大于的話,就是hash桶數組不為空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就賦值為整數最大的閥值
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果當前hash桶數組的長度在擴容后仍然小于最大容量 并且oldCap大于默認值16,就擴充為原來的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 雙倍擴容閥值threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//計算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶數組
table = newTab;//將新數組的值復制給舊的hash桶數組
if (oldTab != null) {//進行擴容操作,復制Node對象值到新的hash桶數組
//把每個bucket都移動到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果舊的hash桶數組在j結點處不為空,復制給e
oldTab[j] = null;//將舊的hash桶數組在j結點處設置為空,方便gc
if (e.next == null)//如果e后面沒有Node結點
newTab[e.hash & (newCap - 1)] = e;//直接對e的hash值對新的數組長度求模獲得存儲位置
else if (e instanceof TreeNode)//如果e是紅黑樹的類型,那么添加到紅黑樹中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 鏈表優化重hash的代碼塊
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//將Node結點的next賦值給next
if ((e.hash & oldCap) == 0) {//如果結點e的hash值與原hash桶數組的長度作與運算為0 原索引
if (loTail == null)//如果loTail為null
loHead = e;//將e結點賦值給loHead
else
loTail.next = e;//否則將e賦值給loTail.next
loTail = e;//然后將e復制給loTail
}
// 原索引+oldCap
else {//如果結點e的hash值與原hash桶數組的長度作與運算不為0
if (hiTail == null)//如果hiTail為null
hiHead = e;//將e賦值給hiHead
else
hiTail.next = e;//如果hiTail不為空,將e復制給hiTail.next
hiTail = e;//將e復制個hiTail
}
} while ((e = next) != null);//直到e為空
//原索引放到bucket里
if (loTail != null) {//如果loTail不為空
loTail.next = null;//將loTail.next設置為空
newTab[j] = loHead;//將loHead賦值給新的hash桶數組[j]處
}
//原索引+oldCap放到bucket里
if (hiTail != null) {//如果hiTail不為空
hiTail.next = null;//將hiTail.next賦值為空
newTab[j + oldCap] = hiHead;//將hiHead賦值給新的hash桶數組[j+舊hash桶數組長度]
}
}
}
}
}
return newTab;
}?? ??3)V putIfAbsent(K key, V value);//如果key存在,則跳過,不覆蓋value值,onlyIfAbsent傳true,不覆蓋更改現有值
/**
* 如果key存在則跳過,不覆蓋value值,onlyIfAbsent傳true,不覆蓋更改現有值
* 如果key不存在則put
* @param key
* @param value
* @return
*/
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}?? ??4)merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction);//用某種方法更新原來的value值
/**
* 用某種方法更新原來的value值
* BiFunction支持函數式變成,lambda表達式,如:String::concat拼接
* @param key
* @param value
* @param remappingFunction
* @return
*/
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (value == null)
throw new NullPointerException();
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;// 該key原來的節點對象
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)//判斷是否需要擴容
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)// 取出old Node對象
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
if (old != null) {//如果 old Node 存在
V v;
if (old.value != null)
// 如果old存在,執行lambda,算出新的val并寫入old Node后返回。
v = remappingFunction.apply(old.value, value);
else
v = value;
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
return v;
}
if (value != null) {
//如果old不存在且傳入的newVal不為null,則put新的kv
if (t != null)
t.putTreeVal(this, tab, hash, key, value);
else {
tab[i] = newNode(hash, key, value, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return value;
}?? ??5)compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction);//根據已知的 k v 算出新的v并put
/**
* 根據已知的 k v 算出新的v并put。
* 如果根據key獲取的oldVal為空則lambda中涉及到oldVal的計算會報空指針。
* 如:map.compute("a", (key, oldVal) -> oldVal + 1); 如果oldVal為null,則空指針
* 源碼和merge類似
* BiFunction返回值作為新的value,BiFunction有二個參數
* @param key
* @param remappingFunction
* @return
*/
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
V oldValue = (old == null) ? null : old.value;
V v = remappingFunction.apply(key, oldValue);
if (old != null) {
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
}
else if (v != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return v;
}?? ??6)computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction);//當key不存在時才put,如果key存在則無效
/**
* 當key不存在時才put,如果key存在則無效
* 如:computeIfAbsent(keyC, k -> genValue(k));
* Function返回值作為新的value,Function只有一個參數
* @param key
* @param mappingFunction
* @return
*/
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
if (mappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
V oldValue;
if (old != null && (oldValue = old.value) != null) {
afterNodeAccess(old);
return oldValue;
}
}
V v = mappingFunction.apply(key);
if (v == null) {
return null;
} else if (old != null) {
old.value = v;
afterNodeAccess(old);
return v;
}
else if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
return v;
}?? ??7)computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction);//compute方法的補充,如果key存在,則覆蓋新的BiFunction計算出的value值,如果不存在則跳過
/**
* compute方法的補充,如果key存在,則覆蓋新的BiFunction計算出的value值,如果不存在則跳過
* @param key
* @param remappingFunction
* @return
*/
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
Node<K,V> e; V oldValue;
int hash = hash(key);
if ((e = getNode(hash, key)) != null &&
(oldValue = e.value) != null) {
V v = remappingFunction.apply(key, oldValue);
if (v != null) {
e.value = v;
afterNodeAccess(e);
return v;
}
else
removeNode(hash, key, null, false, true);
}
return null;
}?? ??8)V replace(K key, V value);//替換新值
/**
* 如果key存在不為空,則替換新的value值
*/
@Override
public V replace(K key, V value) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;
e.value = value;
afterNodeAccess(e);
return oldValue;
}
return null;
}?? ??9)replace(K key, V oldValue, V newValue);//判斷oldValue是否是當前key的值,再替換新值
/**
* 如果key存在不為空并且oldValue等于當前key的值,則替換新的value值
*/
@Override
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
afterNodeAccess(e);
return true;
}
return false;
}?? ??10)replaceAll(BiFunction<? super K, ? super V, ? extends V> function);//替換新值
/**
* 根據lambda函數替換符合規則的值
*/
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Node<K,V>[] tab;
if (function == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
e.value = function.apply(e.key, e.value);
}
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}總結:
? ?正常情況下會擴容2倍,特殊情況下(新擴展數組大小已經達到了最大值)則只取最大值1 << 30。
? ?

?? ??1)V remove(Object key); //根據key 刪除元素?? ??
/**
* 根據key 刪除元素
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}?
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}?? ??2)remove(Object key, Object value); //根據key,value 刪除元素?
/**
* 根據key,value 刪除元素?
*/
@Override
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
/**
* 返回指定的值
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* @author jiaxiaoxian
* @date 2019年2月12日
* 如果key不為空則返回key的值,否則返回默認值
*/
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}/**
* 返回所有key,以Set結構返回
*/
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
} /**
* 復制,返回此HashMap 的淺拷貝
*/
@SuppressWarnings("unchecked")
@Override
public Object clone() {
HashMap<K,V> result;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
result.reinitialize();
result.putMapEntries(this, false);
return result;
}/**
* 清空HashMap
*/
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}/**
* 是否存在此key
*/
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}/**
* 是否存在此value
*/
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}/**
* 返回key,value的Set結果
*/
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}1)HashMap的key、value都可以存放null,key不可重復,value可重復,是數組鏈表紅黑樹的數據結構。
2)HashMap區別于數組的地方在于能夠自動擴展大小,其中關鍵的方法就是resize()方法,擴容為2倍。
3)HashMap由于本質是數組,在不沖突的情況下,查詢效率很高,hash沖突后會形成鏈表,查找時多一層
遍歷,當鏈表長度到8并且數組長度大于64,轉成紅黑樹存儲,提高查詢效率。
4)初始化數組時推薦給初始長度,反復擴容會增加時耗,影響性能效率,HashMap需要注意負載因子0.75f,
初始16,當長度大于(16*0.75)12的時候會擴容為32,所以初始長度設置需要卻別對待。
5)HashMap是一種散列表,采用(數組 + 鏈表 + 紅黑樹)的存儲結構。
6)當桶的數量大于64且單個桶中元素的數量大于8時,進行樹化。
7)當單個桶中元素數量小于6時,進行反樹化。
8)HashMap是非線程安全的容器。
9)HashMap查找添加元素的時間復雜度都為O(1)。免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。