溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本人免費整理了Java高級資料,涵蓋了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并發分布式等教程,一共30G,需要自己領取。
傳送門:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
在上一篇文章中總結了雖然這種回答似乎不能獲取什么內容,可以google下。在<<深入理解Java虛擬機>>中看到的定義。原文如下: 當多個線程訪問同一個對象時,如果不用考慮這些線程在運行時環境下的調度和交替運行,也不需要進行額外的同步,或者在調用方進行任何其他的協調操作,調用這個對象的行為都可以獲取正確的結果,那這個對象是線程安全的。
關于定義的理解這是一個仁者見仁智者見智的事情。出現線程安全的問題一般是因為主內存和工作內存數據不一致性和重排序導致的,而解決線程安全的問題最重要的就是理解這兩種問題是怎么來的,那么,理解它們的核心在于理解java內存模型(JMM)。
在多線程條件下,多個線程肯定會相互協作完成一件事情,一般來說就會涉及到多個線程間相互通信告知彼此的狀態以及當前的執行結果等,另外,為了性能優化,還會涉及到編譯器指令重排序和處理器指令重排序。下面會一一來聊聊這些知識。
線程間協作通信可以類比人與人之間的協作的方式,在現實生活中,之前網上有個流行語“你媽喊你回家吃飯了”,就以這個生活場景為例,小.明在外面玩耍,小.明媽媽在家里做飯,做晚飯后準備叫小.明回家吃飯,那么就存在兩種方式:
小.明媽媽要去上班了十分緊急這個時候手機又沒有電了,于是就在桌子上貼了一張紙條“飯做好了,放在...”小.明回家后看到紙條如愿吃到媽媽做的飯菜,那么,如果將小.明媽媽和小.明作為兩個線程,那么這張紙條就是這兩個線程間通信的共享變量,通過讀寫共享變量實現兩個線程間協作;
還有一種方式就是,媽.媽.的手機還有電,媽媽在趕去坐公交的路上給小.明打了個電話,這種方式就是通知機制來完成協作。同樣,可以引申到線程間通信機制。
通過上面這個例子,應該有些認識。在并發編程中主要需要解決兩個問題:1. 線程之間如何通信;2.線程之間如何完成同步(這里的線程指的是并發執行的活動實體)。通信是指線程之間以何種機制來交換信息,主要有兩種:共享內存和消息傳遞。這里,可以分別類比上面的兩個舉例。
java內存模型是共享內存的并發模型,線程之間主要通過讀-寫共享變量來完成隱式通信。如果程序員不能理解Java的共享內存模型在編寫并發程序時一定會遇到各種各樣關于內存可見性的問題。
1.哪些是共享變量
在java程序中所有實例域,靜態域和數組元素都是放在堆內存中(所有線程均可訪問到,是可以共享的),而局部變量,方法定義參數和異常處理器參數不會在線程間共享。共享數據會出現線程安全的問題,而非共享數據不會出現線程安全的問題。關于JVM運行時內存區域在后面的文章會講到。
2.JMM抽象結構模型
我們知道CPU的處理速度和主存的讀寫速度不是一個量級的,為了平衡這種巨大的差距,每個CPU都會有緩存。因此,共享變量會先放在主存中,每個線程都有屬于自己的工作內存,并且會把位于主存中的共享變量拷貝到自己的工作內存,之后的讀寫操作均使用位于工作內存的變量副本,并在某個時刻將工作內存的變量副本寫回到主存中去。JMM就從抽象層次定義了這種方式,并且JMM決定了一個線程對共享變量的寫入何時對其他線程是可見的。

如圖為JMM抽象示意圖,線程A和線程B之間要完成通信的話,要經歷如下兩步:
線程A從主內存中將共享變量讀入線程A的工作內存后并進行操作,之后將數據重新寫回到主內存中;
線程B從主存中讀取最新的共享變量
從橫向去看看,線程A和線程B就好像通過共享變量在進行隱式通信。這其中有很有意思的問題,如果線程A更新后數據并沒有及時寫回到主存,而此時線程B讀到的是過期的數據,這就出現了“臟讀”現象。可以通過同步機制(控制不同線程間操作發生的相對順序)來解決或者通過volatile關鍵字使得每次volatile變量都能夠強制刷新到主存,從而對每個線程都是可見的。
一個好的內存模型實際上會放松對處理器和編譯器規則的束縛,也就是說軟件技術和硬件技術都為同一個目標而進行奮斗:在不改變程序執行結果的前提下,盡可能提高并行度。JMM對底層盡量減少約束,使其能夠發揮自身優勢。因此,在執行程序時,為了提高性能,編譯器和處理器常常會對指令進行重排序。一般重排序可以分為如下三種:

編譯器優化的重排序。編譯器在不改變單線程程序語義的前提下,可以重新安排語句的執行順序;
指令級并行的重排序。現代處理器采用了指令級并行技術來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序;
內存系統的重排序。由于處理器使用緩存和讀/寫緩沖區,這使得加載和存儲操作看上去可能是在亂序執行的。
如圖,1屬于編譯器重排序,而2和3統稱為處理器重排序。這些重排序會導致線程安全的問題,一個很經典的例子就是DCL問題,這個在以后的文章中會具體去聊。針對編譯器重排序,JMM的編譯器重排序規則會禁止一些特定類型的編譯器重排序;針對處理器重排序,編譯器在生成指令序列的時候會通過插入內存屏障指令來禁止某些特殊的處理器重排序。
那么什么情況下,不能進行重排序了?下面就來說說數據依賴性。
有如下代碼:
??double?pi?=?3.14?//A ?double?r?=?1.0???//B ?double?area?=?pi?*?r?*?r?//C
這是一個計算圓面積的代碼,由于A,B之間沒有任何關系,對最終結果也不會存在關系,它們之間執行順序可以重排序。因此可以執行順序可以是A->B->C或者B->A->C執行最終結果都是3.14,即A和B之間沒有數據依賴性。
具體的定義為:如果兩個操作訪問同一個變量,且這兩個操作有一個為寫操作,此時這兩個操作就存在數據依賴性這里就存在三種情況:1. 讀后寫;2.寫后寫;3. 寫后讀,者三種操作都是存在數據依賴性的,如果重排序會對最終執行結果會存在影響。
編譯器和處理器在重排序時,會遵守數據依賴性,編譯器和處理器不會改變存在數據依賴性關系的兩個操作的執行順序
另外,還有一個比較有意思的就是as-if-serial語義。
as-if-serial
as-if-serial語義的意思是:不管怎么重排序(編譯器和處理器為了提供并行度),(單線程)程序的執行結果不能被改變。編譯器,runtime和處理器都必須遵守as-if-serial語義。as-if-serial語義把單線程程序保護了起來,遵守as-if-serial語義的編譯器,runtime和處理器共同為編寫單線程程序的程序員創建了一個幻覺:單線程程序是按程序的順序來執行的。
比如上面計算圓面積的代碼,在單線程中,會讓人感覺代碼是一行一行順序執行上,實際上A,B兩行不存在數據依賴性可能會進行重排序,即A,B不是順序執行的。as-if-serial語義使程序員不必擔心單線程中重排序的問題干擾他們,也無需擔心內存可見性問題。
4. happens-before規則
上面的內容講述了重排序原則,一會是編譯器重排序一會是處理器重排序,如果讓程序員再去了解這些底層的實現以及具體規則,那么程序員的負擔就太重了,嚴重影響了并發編程的效率。因此,JMM為程序員在上層提供了六條規則,這樣我們就可以根據規則去推論跨線程的內存可見性問題,而不用再去理解底層重排序的規則。下面以兩個方面來說。
4.1 happens-before定義
happens-before的概念最初由Leslie Lamport在其一篇影響深遠的論文(《Time,Clocks and the Ordering of Events in a Distributed System》)中提出,有興趣的可以google一下。JSR-133使用happens-before的概念來指定兩個操作之間的執行順序。由于這兩個操作可以在一個線程之內,也可以是在不同線程之間。
因此,JMM可以通過happens-before關系向程序員提供跨線程的內存可見性保證(如果A線程的寫操作a與B線程的讀操作b之間存在happens-before關系,盡管a操作和b操作在不同的線程中執行,但JMM向程序員保證a操作將對b操作可見)。
具體的定義為:
1)如果一個操作happens-before另一個操作,那么第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
2)兩個操作之間存在happens-before關系,并不意味著Java平臺的具體實現必須要按照happens-before關系指定的順序來執行。如果重排序之后的執行結果,與按happens-before關系來執行的結果一致,那么這種重排序并不非法(也就是說,JMM允許這種重排序)。
上面的1)是JMM對程序員的承諾。從程序員的角度來說,可以這樣理解happens-before關系:如果A happens-before B,那么Java內存模型將向程序員保證——A操作的結果將對B可見,且A的執行順序排在B之前。注意,這只是Java內存模型向程序員做出的保證!
上面的2)是JMM對編譯器和處理器重排序的約束原則。正如前面所言,JMM其實是在遵循一個基本原則:只要不改變程序的執行結果(指的是單線程程序和正確同步的多線程程序),編譯器和處理器怎么優化都行。
JMM這么做的原因是:程序員對于這兩個操作是否真的被重排序并不關心,程序員關心的是程序執行時的語義不能被改變(即執行結果不能被改變)。因此,happens-before關系本質上和as-if-serial語義是一回事。
下面來比較一下as-if-serial和happens-before:
as-if-serial VS happens-before
as-if-serial語義保證單線程內程序的執行結果不被改變,happens-before關系保證正確同步的多線程程序的執行結果不被改變。
as-if-serial語義給編寫單線程程序的程序員創造了一個幻境:單線程程序是按程序的順序來執行的。happens-before關系給編寫正確同步的多線程程序的程序員創造了一個幻境:正確同步的多線程程序是按happens-before指定的順序來執行的。
as-if-serial語義和happens-before這么做的目的,都是為了在不改變程序執行結果的前提下,盡可能地提高程序執行的并行度。
4.2 具體規則
具體的一共有六項規則:
程序順序規則:一個線程中的每個操作,happens-before于該線程中的任意后續操作。
監視器鎖規則:對一個鎖的解鎖,happens-before于隨后對這個鎖的加鎖。
volatile變量規則:對一個volatile域的寫,happens-before于任意后續對這個volatile域的讀。
傳遞性:如果A happens-before B,且B happens-before C,那么A happens-before C。
start()規則:如果線程A執行操作ThreadB.start()(啟動線程B),那么A線程的ThreadB.start()操作happens-before于線程B中的任意操作。
join()規則:如果線程A執行操作ThreadB.join()并成功返回,那么線程B中的任意操作happens-before于線程A從ThreadB.join()操作成功返回。
程序中斷規則:對線程interrupted()方法的調用先行于被中斷線程的代碼檢測到中斷時間的發生。
對象finalize規則:一個對象的初始化完成(構造函數執行結束)先行于發生它的finalize()方法的開始。
下面以一個具體的例子來講下如何使用這些規則進行推論:
依舊以上面計算圓面積的進行描述。利用程序順序規則(規則1)存在三個happens-before關系:
1. A happens-before B;
2. B happens-before C;
3. A happens-before C。
這里的第三個關系是利用傳遞性進行推論的。
A happens-before B,定義1要求A執行結果對B可見,并且A操作的執行順序在B操作之前,但與此同時利用定義中的第二條,A,B操作彼此不存在數據依賴性,兩個操作的執行順序對最終結果都不會產生影響,在不改變最終結果的前提下,允許A,B兩個操作重排序,即happens-before關系并不代表了最終的執行順序。
5. 總結
上面已經聊了關于JMM的兩個方面:
1. JMM的抽象結構(主內存和線程工作內存);
2. 重排序以及happens-before規則。
接下來,我們來做一個總結。從兩個方面進行考慮。
1. 如果讓我們設計JMM應該從哪些方面考慮,也就是說JMM承擔哪些功能;
2. happens-before與JMM的關系;
3. 由于JMM,多線程情況下可能會出現哪些問題?
5.1 JMM的設計

JMM是語言級的內存模型,在我的理解中JMM處于中間層,包含了兩個方面:
(1)內存模型;
(2)重排序以及happens-before規則。
同時,為了禁止特定類型的重排序會對編譯器和處理器指令序列加以控制。
而上層會有基于JMM的關鍵字和J.U.C包下的一些具體類用來方便程序員能夠迅速高效率的進行并發編程。站在JMM設計者的角度,在設計JMM時需要考慮兩個關鍵因素:
程序員對內存模型的使用?程序員希望內存模型易于理解、易于編程。程序員希望基于一個強內存模型來編寫代碼。
編譯器和處理器對內存模型的實現?編譯器和處理器希望內存模型對它們的束縛越少越好,這樣它們就可以做盡可能多的優化來提高性能。編譯器和處理器希望實現一個弱內存模型。
另外還要一個特別有意思的事情就是關于重排序問題,更簡單的說,重排序可以分為兩類:
會改變程序執行結果的重排序。
不會改變程序執行結果的重排序。
JMM對這兩種不同性質的重排序,采取了不同的策略,如下。
對于會改變程序執行結果的重排序,JMM要求編譯器和處理器必須禁止這種重排序。
對于不會改變程序執行結果的重排序,JMM對編譯器和處理器不做要求(JMM允許這種 重排序)
JMM的設計圖為:

從圖可以看出:
JMM向程序員提供的happens-before規則能滿足程序員的需求。JMM的happens-before規則不但簡單易懂,而且也向程序員提供了足夠強的內存可見性保證(有些內存可見性保證其實并不一定真實存在,比如上面的A happens-before B)。
JMM對編譯器和處理器的束縛已經盡可能少。從上面的分析可以看出,JMM其實是在遵循一個基本原則:只要不改變程序的執行結果(指的是單線程程序和正確同步的多線程程序),編譯器和處理器怎么優化都行。例如,如果編譯器經過細致的分析后,認定一個鎖只會被單個線程訪問,那么這個鎖可以被消除。再如,如果編譯器經過細致的分析后,認定一個volatile變量只會被單個線程訪問,那么編譯器可以把這個volatile變量當作一個普通變量來對待。這些優化既不會改變程序的執行結果,又能提高程序的執行效率。
5.2 happens-before與JMM的關系
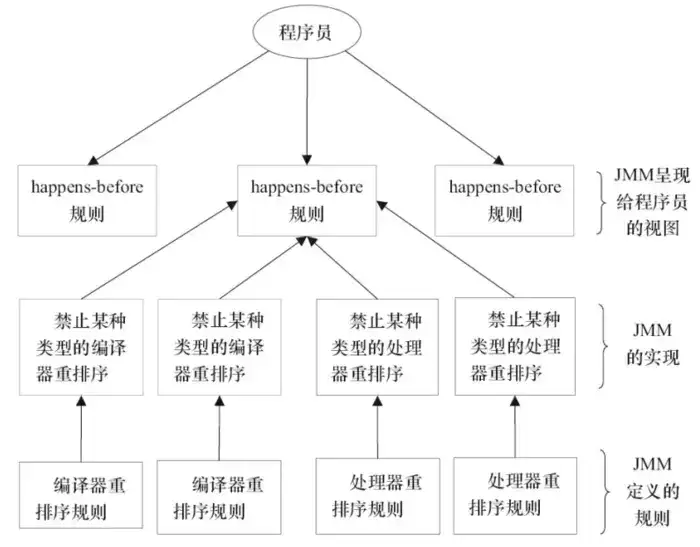
一個happens-before規則對應于一個或多個編譯器和處理器重排序規則。對于Java程序員來說,happens-before規則簡單易懂,它避免Java程序員為了理解JMM提供的內存可見性保證而去學習復雜的重排序規則以及這些規則的具體實現方法
5.3 今后可能需要關注的問題
從上面內存抽象結構來說,可能出在數據“臟讀”的現象,這就是數據可見性的問題,另外,重排序在多線程中不注意的話也容易存在一些問題,比如一個很經典的問題就是DCL(雙重檢驗鎖),這就是需要禁止重排序,另外,在多線程下原子操作例如i++不加以注意的也容易出現線程安全的問題。但總的來說,在多線程開發時需要從原子性,有序性,可見性三個方面進行考慮。J.U.C包下的并發工具類和并發容器也是需要花時間去掌握的,這些東西在以后得文章中多會一一進行討論。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





