溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、索引結構
在聚集索引上建立非聚集索引,在日常應用中經常發生。
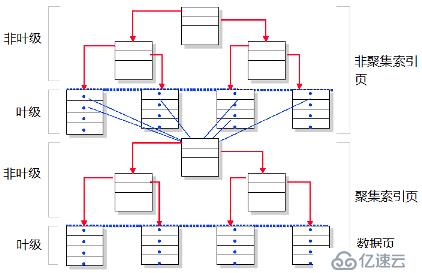
二、實驗[三E]
繼續使用上一篇文章中創建的唯一聚集索引,在此基礎之上新建一個非聚集索引。
1. 創建非聚集索引
| CREATE INDEX IX_person1_UserIDModifyDate ON person1 (UserID,ModifyDate) |
2. 查看索引占用的空間
| DBCC SHOWCONTIG ('person1') WITH ALL_INDEXES |
結果如下:
| DBCC SHOWCONTIG 正在掃描 'person1' 表... 表: 'person1' (389576426);索引 ID: 1,數據庫 ID: 8 已執行 TABLE 級別的掃描。 - 掃描頁數................................: 4000 - 掃描區數..............................: 500 - 區切換次數..............................: 499 - 每個區的平均頁數........................: 8.0 - 掃描密度 [最佳計數:實際計數].......: 100.00% [500:500] - 邏輯掃描碎片 ..................: 0.03% - 區掃描碎片 ..................: 2.20% - 每頁的平均可用字節數.....................: 76.0 - 平均頁密度(滿).....................: 99.06% DBCC SHOWCONTIG 正在掃描 'person1' 表... 已執行 LEAF 級別的掃描。 - 掃描頁數................................: 179 - 掃描區數..............................: 23 - 區切換次數..............................: 22 - 每個區的平均頁數........................: 7.8 - 掃描密度 [最佳計數:實際計數].......: 100.00% [23:23] - 邏輯掃描碎片 ..................: 0.00% - 區掃描碎片 ..................: 4.35% - 每頁的平均可用字節數.....................: 51.3 - 平均頁密度(滿).....................: 99.37% DBCC 執行完畢。如果 DBCC 輸出了錯誤信息,請與系統管理員聯系。 |
3. 查看索引的層次
對于建立在聚集索引上的非聚集索引,
| SELECT index_depth, index_level, record_count, page_count, min_record_size_in_bytes as 'MinLen', max_record_size_in_bytes as 'MaxLen', avg_record_size_in_bytes as 'AvgLen', convert(decimal(6,2),avg_page_space_used_in_percent) as 'PageDensity' FROM sys.dm_db_index_physical_stats (8, OBJECT_ID('person1'),2,NULL,'DETAILED') |
結果如下表所示:
index _depth | Index _level | Record _count | Page _count | MinLen | MaxLen | AvgLen | PageDensity |
2 | 0 | 80000 | 179 | 16 | 16 | 16 | 99.36 |
2 | 1 | 179 | 1 | 22 | 22 | 22 | 53.05 |
根據上表的數據,可以發現它與堆上的非聚集索引的數據是一樣的。該索引共有2層。level=0 是葉級,它有179個頁面,指向底層的聚集索引的根頁;level=1 是這個非聚集索引的根頁,它只有1個頁面,指向葉級的179個索引頁。
三、比較三類索引占用的頁數
比較前面幾個實驗,各類索引占用的頁數如下:
1. 堆
在實驗[三A]中,堆是最原始的結構,index_id = 0,存儲了 80000 條記錄,占用了4000 頁。
2. 聚集索引
聚集索引的 index_id = 1。
唯一聚集索引在葉級將數據頁重新進行物理排序,不會額外增加數據頁。由于索引寬度固定,因此在根級只占用了1個頁,中間級占用了7個頁。一共占用了1+7+4000=4008 頁。與堆相比,非葉級的索引頁多了8頁。
非唯一聚集索引需要在后臺保持數據的唯一,因此在后臺增加了一個 4 字節的uniqueifier 列,有可能需要增加額外的數據頁。在前面的案例中,非唯一聚集索引使用了4009頁,也就是多了9個頁。同時由于索引寬度的開銷較大,中間級占用了10個頁,加上根級占用了1個頁,一共占用了1+10+4009=4020 頁。與堆相比,葉級索引頁(數據頁)多了9頁,非葉級的索引頁多了11頁。
3. 非聚集索引
堆上的非聚集索引與聚集索引上的非聚集索引,index_id >= 2,占用了相同數量的索引頁面,頁面數量為:179+1=180 頁。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





