溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹mysql中聚集索引和非聚集索引有哪些區別,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
區別:1、聚集索引在葉子節點存儲的是表中的數據,而非聚集索引在葉子節點存儲的是主鍵和索引列;2、聚集索引中表記錄的排列順序和索引的排列順序一致,而非聚集索引的排列順序不一致;3、聚集索引每張表只能有一個,而非聚集索引可以有多個。
本教程操作環境:windows7系統、mysql8版本、Dell G3電腦。
MySQL的Innodb存儲引擎的索引分為聚集索引和非聚集索引兩大類,理解聚集索引和非聚集索引可通過對比漢語字典的索引。漢語字典提供了兩類檢索漢字的方式,第一類是拼音檢索(前提是知道該漢字讀音),比如拼音為cheng的漢字排在拼音chang的漢字后面,根據拼音找到對應漢字的頁碼(因為按拼音排序,二分查找很快就能定位),這就是我們通常所說的字典序;第二類是部首筆畫檢索,根據筆畫找到對應漢字,查到漢字對應的頁碼。拼音檢索就是聚集索引,因為存儲的記錄(數據庫中是行數據、字典中是漢字的詳情記錄)是按照該索引排序的;筆畫索引,雖然筆畫相同的字在筆畫索引中相鄰,但是實際存儲頁碼卻不相鄰,這是非聚集索引。
索引中鍵值的邏輯順序決定了表中相應行的物理順序。
聚集索引確定表中數據的物理順序。聚集索引類似于電話簿,后者按姓氏排列數據。 聚集索引對于那些經常要搜索范圍值的列特別有效。使用聚集索引找到包含第一個值的行后,便可以確保包含后續索引值的行在物理相鄰。例如,如果應用程序執行 的一個查詢經常檢索某一日期范圍內的記錄,則使用聚集索引可以迅速找到包含開始日期的行,然后檢索表中所有相鄰的行,直到到達結束日期。這樣有助于提高此 類查詢的性能。同樣,如果對從表中檢索的數據進行排序時經常要用到某一列,則可以將該表在該列上聚集(物理排序),避免每次查詢該列時都進行排序,從而節 省成本。
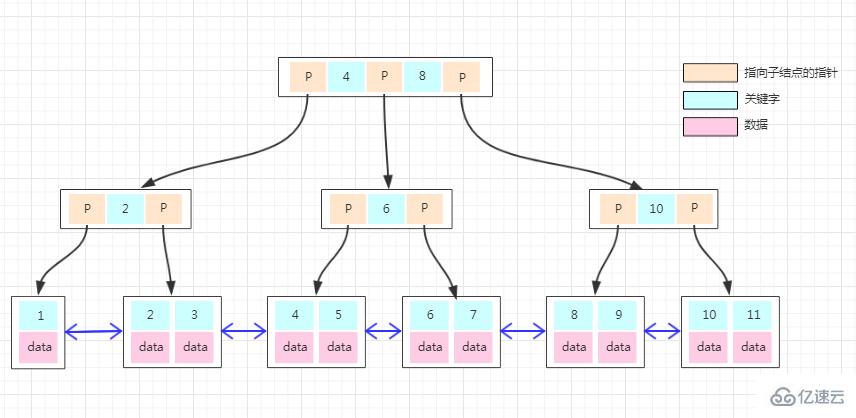
以上是innodb的b+tree索引結構
我們知道b+tree是從b-tree演變而來,一棵m階的B-Tree有如下特性:
1、每個結點最多m個子結點。
2、除了根結點和葉子結點外,每個結點最少有m/2(向上取整)個子結點。
3、如果根結點不是葉子結點,那根結點至少包含兩個子結點。
4、所有的葉子結點都位于同一層。
5、每個結點都包含k個元素(關鍵字),這里m/2≤k<m,這里m/2向下取整。
6、每個節點中的元素(關鍵字)從小到大排列。
7、每個元素(關鍵字)字左結點的值,都小于或等于該元素(關鍵字)。右結點的值都大于或等于該元素(關鍵字)。
b+tree的特點是:
1、所有的非葉子節點只存儲關鍵字信息。
2、所有衛星數據(具體數據)都存在葉子結點中。
3、所有的葉子結點中包含了全部元素的信息。
4、所有葉子節點之間都有一個鏈指針。
我們發現,b+trre有以下特性:
對一個范圍內的查詢特別有效快速(通過葉子的鏈指針);
對具體的key值查詢僅僅比b-tree低效一點(因為要到葉子一級),但也可以忽略;
索引中索引的邏輯順序與磁盤上行的物理存儲順序不同。
其實按照定義,除了聚集索引以外的索引都是非聚集索引,只是人們想細分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引類比成現實生活中的東西,那么非聚集索引就像新華字典的偏旁字典,他結構順序與實際存放順序不一定一致。
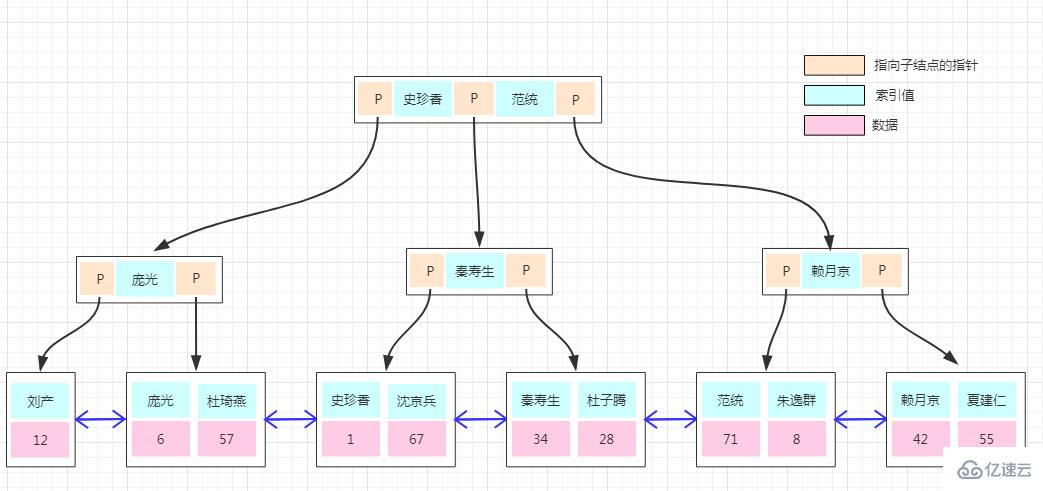
非聚集索引的存儲結構與前面是一樣的,不同的是在葉子結點的數據部分存的不再是具體的數據,而數據的聚集索引的key。所以通過非聚集索引查找的過程是先找到該索引key對應的聚集索引的key,然后再拿聚集索引的key到主鍵索引樹上查找對應的數據,這個過程稱為回表!
舉個例子說明下:
create table student ( `id` INT UNSIGNED AUTO_INCREMENT, `username` VARCHAR(255), `score` INT, PRIMARY KEY(`id`), KEY(`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
聚集索引clustered index(id), 非聚集索引index(username)。
使用以下語句進行查詢,不需要進行二次查詢,直接就可以從非聚集索引的節點里面就可以獲取到查詢列的數據。
select id, username from t1 where username = '小明' select username from t1 where username = '小明'
但是使用以下語句進行查詢,就需要二次的查詢去獲取原數據行的score:
select username, score from t1 where username = '小明'
區別一:
聚集索引:就是以主鍵創建的索引,在葉子節點存儲的是表中的數據
非聚集索引:就是以非主鍵創建的索引(也叫做二級索引),在葉子節點存儲的是主鍵和索引列。
區別二:
聚集索引中表記錄的排列順序和索引的排列順序一致;所以查詢效率快,因為只要找到第一個索引值記錄,其余的連續性的記錄在物理表中也會連續存放,一起就可以查詢到。缺點:新增比較慢,因為為了保證表中記錄的物理順序和索引順序一致,在記錄插入的時候,會對數據頁重新排序。
非聚集索引中表記錄的排列順序和索引的排列順序不一致。
區別三:
聚集索引是物理上連續存在,而非聚集索引是邏輯上的連續,物理存儲不連續。
區別四:
聚集索引每張表只能有一個,非聚集索引可以有多個。
以上是“mysql中聚集索引和非聚集索引有哪些區別”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





