溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java負載均衡算法有什么作用”,在日常操作中,相信很多人在Java負載均衡算法有什么作用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Java負載均衡算法有什么作用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
負載均衡在Java領域中有著廣泛深入的應用,不管是大名鼎鼎的nginx,還是微服務治理組件如dubbo,feign等,負載均衡的算法在其中都有著實際的使用
負載均衡的核心思想在于其底層的算法思想,比如大家熟知的算法有 輪詢,隨機,最小連接,加權輪詢等,在現實中不管怎么配置,都離不開其算法的核心原理,下面將結合實際代碼對常用的負載均衡算法做一些全面的總結。
輪詢即排好隊,一個接一個的輪著來。從數據結構上,有一個環狀的節點,節點上面布滿了服務器,服務器之間首尾相連,帶有順序性。當請求過來的時候,從某個節點的服務器開始響應,那么下一次請求再來,就依次由后面的服務器響應,由此繼續
按照這個描述,我們很容易聯想到,可以使用一個雙向(雙端)鏈表的數據結構來模擬實現這個算法
1、定義一個server類,用于標識服務器中的鏈表節點
class Server {
Server prev;
Server next;
String name;
public Server(String name) {
this.name = name;
}
}2、核心代碼
/**
* 輪詢
*/
public class RData {
private static Logger logger = LoggerFactory.getLogger(RData.class);
//標識當前服務節點,每次請求過來時,返回的是current節點
private Server current;
public RData(String serverName) {
logger.info("init servers : " + serverName);
String[] names = serverName.split(",");
for (int i = 0; i < names.length; i++) {
Server server = new Server(names[i]);
//當前為空,說明首次創建
if (current == null) {
//current就指向新創建server
this.current = server;
//同時,server的前后均指向自己
current.prev = current;
current.next = current;
} else {
//說明已經存在機器了,則按照雙向鏈表的功能,進行節點添加
addServer(names[i]);
}
}
}
//添加機器節點
private void addServer(String serverName) {
logger.info("add new server : " + serverName);
Server server = new Server(serverName);
Server next = this.current.next;
//在當前節點后插入新節點
this.current.next = server;
server.prev = this.current;
//由于是雙向鏈表,修改下一節點的prev指針
server.next = next;
next.prev = server;
}
//機器節點移除,修改節點的指向即可
private void removeServer() {
logger.info("remove current = " + current.name);
this.current.prev.next = this.current.next;
this.current.next.prev = this.current.prev;
this.current = current.next;
}
//請求。由當前節點處理
private void request() {
logger.info("handle server is : " + this.current.name);
this.current = current.next;
}
public static void main(String[] args) throws Exception {
//初始化兩臺機器
RData rr = new RData("192.168.10.0,192.168.10.1");
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
rr.request();
}
}
}).start();
//3s后,3號機器加入清單
Thread.currentThread().sleep(2000);
rr.addServer("192.168.10.3");
//3s后,當前服務節點被移除
Thread.currentThread().sleep(3000);
rr.removeServer();
}
}結合注釋對代碼進行理解,這段代碼解釋開來就是考察對雙端鏈表的底層能力,操作鏈表結構時,最重要的就是要搞清在節點的添加和移除時,理清節點的前后指向,然后再理解這段代碼時就沒有難度了,下面運行下程序
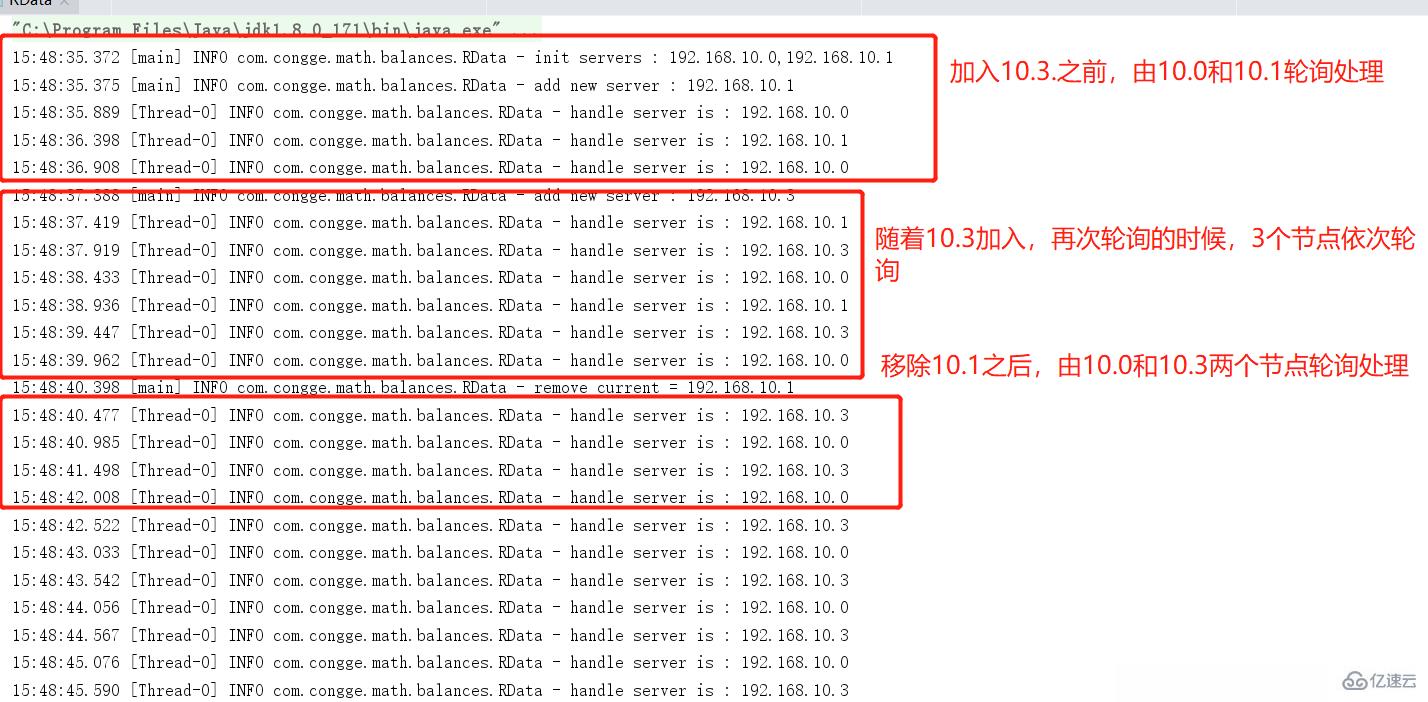
輪詢算法優缺點小結
實現簡單,機器列表可自由加減,節點尋找時間復雜度為o(1)
無法針對節點做偏向性定制處理,節點處理能力強弱無法做區分對待,比如某些處理能力強配置高的服務器更希望承擔更多的請求這個就做不到
從可提供的服務器列表中隨機取一個提供響應。
既然是隨機存取的場景,很容易想到使用數組可以更高效的通過下標完成隨機讀取,這個算法的模擬比較簡單,下面直接上代碼
/**
* 隨機
*/
public class RandomMath {
private static List<String> ips;
public RandomMath(String nodeNames) {
System.out.println("init servers : " + nodeNames);
String[] nodes = nodeNames.split(",");
//初始化服務器列表,長度取機器數
ips = new ArrayList<>(nodes.length);
for (String node : nodes) {
ips.add(node);
}
}
//請求處理
public void request() {
Random ra = new Random();
int i = ra.nextInt(ips.size());
System.out.println("the handle server is :" + ips.get(i));
}
//添加節點,注意,添加節點可能會造成內部數組擴容
void addnode(String nodeName) {
System.out.println("add new node : " + nodeName);
ips.add(nodeName);
}
//移除
void remove(String nodeName) {
System.out.println("remove node is: " + nodeName);
ips.remove(nodeName);
}
public static void main(String[] args) throws Exception {
RandomMath rd = new RandomMath("192.168.10.1,192.168.10.2,192.168.10.3");
//使用一個線程,模擬不間斷的請求
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
rd.request();
}
}
}).start();
//間隔3秒之后,添加一臺新的機器
Thread.currentThread().sleep(3000);
rd.addnode("192.168.10.4");
//3s后,當前服務節點被移除
Thread.currentThread().sleep(3000);
rd.remove("192.168.10.2");
}
}運行代碼觀察結果:
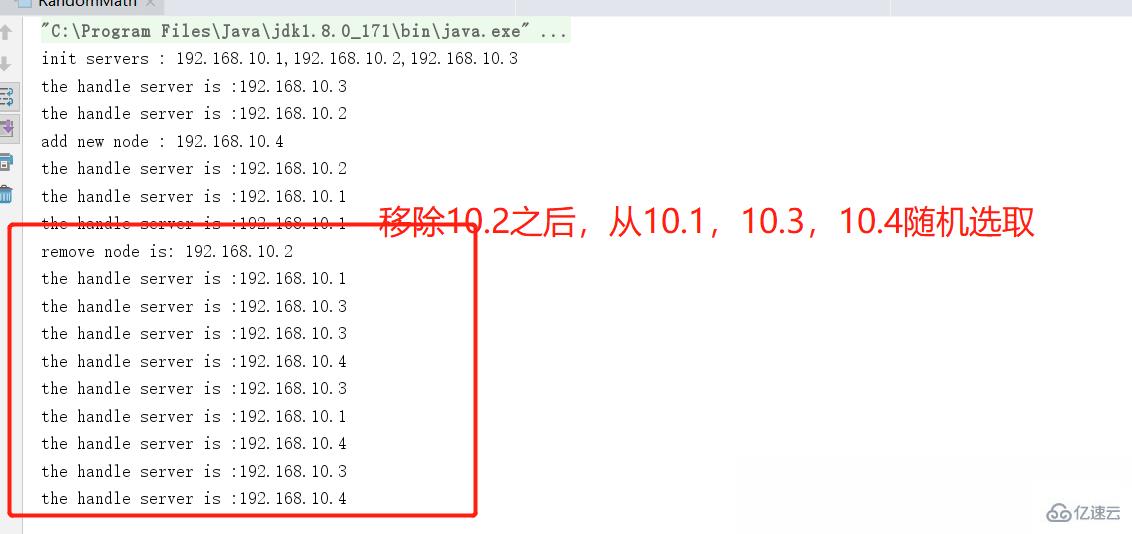
隨機算法小結
隨機算法簡單高效
適合一個服務器集群中,各個機器配置差不多的情況,和輪詢一樣,無法根據各個服務器本身的配置做一些定向的區分對待
在隨機選擇的基礎上,機器仍然是被隨機被篩選,但是做一組加權值,根據權值不同,機器列表中的各個機器被選中的概率不同,從這個角度理解,可認為隨機是一種等權值的特殊情況
設計思路依然相同,只是每個機器需要根據權值大小,生成不同數量的節點,節點排隊后,隨機獲取。這里的數據結構主要涉及到隨 機的讀取,所以優選為數組
/**
* 加權隨機
*/
public class WeightRandom {
ArrayList<String> list;
public WeightRandom(String nodes) {
String[] ns = nodes.split(",");
list = new ArrayList<>();
for (String n : ns) {
String[] n1 = n.split(":");
int weight = Integer.valueOf(n1[1]);
for (int i = 0; i < weight; i++) {
list.add(n1[0]);
}
}
}
public void request() {
//下標,隨機數,注意因子
int i = new Random().nextInt(list.size());
System.out.println("the handle server is : " + list.get(i));
}
public static void main(String[] args) throws Exception{
WeightRandom wr = new WeightRandom("192.168.10.1:2,192.168.10.2:1");
for (int i = 0; i < 9; i++) {
Thread.sleep(2000);
wr.request();
}
}
}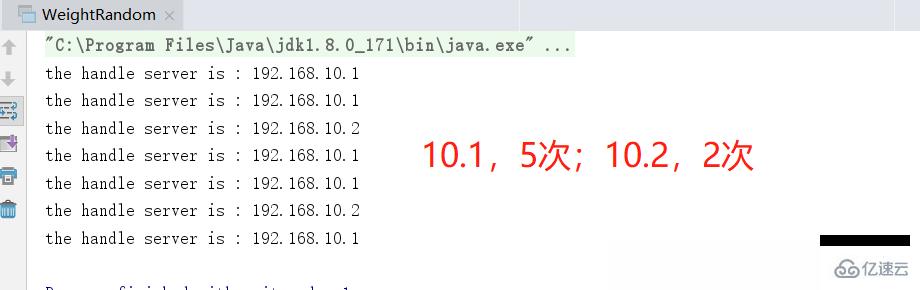
我們不妨將10.1的權重值再調的大點,比如調為3,再次運行一下,這個效果就更明顯了

加權隨機算法小結
為隨機算法的升級和優化
一定程度上解決了服務器節點偏向問題,可以通過指定權重來提升某個機器的偏向
在前面的輪詢算法中我們看到,輪詢只是機械的旋轉不斷在雙向鏈表中進行移動,而加權輪詢則彌補了所有機器被一視同仁的缺點。在輪詢的基礎上,服務器初始化 時,各個機器攜帶一個權重值
加權輪詢的算法思想不是很好理解,下面我以一個圖進行說明:
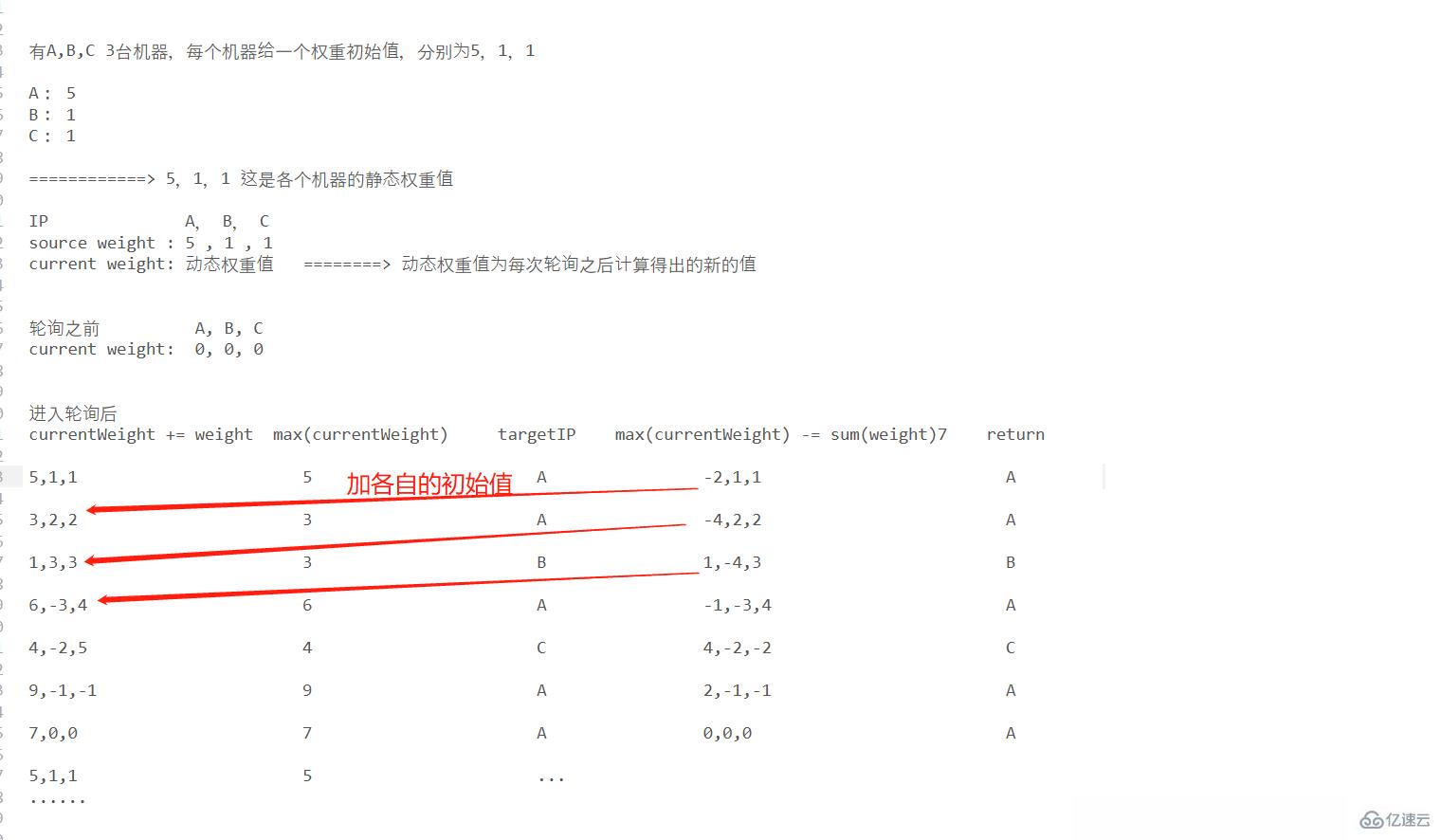

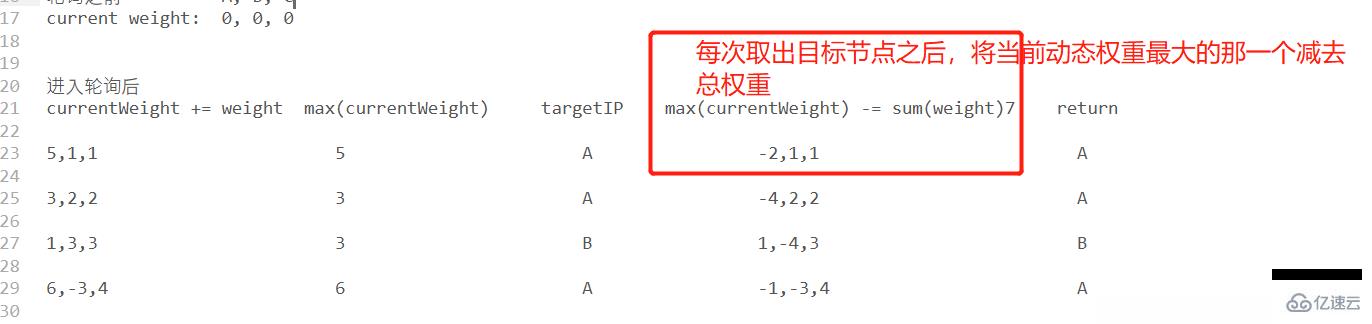
加權輪詢算法的初衷是希望通過這樣一套算法保證整體的請求平滑性,從上圖中也可以發現,經過幾輪的循環之后,由可以回到最初的結果,而且在某一個輪詢中,不同機器根據權重值的不同,請求被讀取的概率也會不同
實現思路和輪詢差不多,整體仍然是鏈表結構,不同的是,每個具體的節點需加上權重值屬性
1、節點屬性類
class NodeServer {
int weight;
int currentWeight;
String ip;
public NodeServer(String ip, int weight) {
this.ip = ip;
this.weight = weight;
this.currentWeight = 0;
}
@Override
public String toString() {
return String.valueOf(currentWeight);
}
}2、核心代碼
/**
* 加權輪詢
*/
public class WeightRDD {
//所有機器節點列表
ArrayList<NodeServer> list;
//總權重
int total;
//機器節點初始化 , 格式:a#4,b#2,c#1,實際操作時可根據自己業務定制
public WeightRDD(String nodes) {
String[] ns = nodes.split(",");
list = new ArrayList<>(ns.length);
for (String n : ns) {
String[] n1 = n.split("#");
int weight = Integer.valueOf(n1[1]);
list.add(new NodeServer(n1[0], weight));
total += weight;
}
}
public NodeServer getCurrent() {
for (NodeServer node : list) {
node.currentWeight += node.weight;
}
NodeServer current = list.get(0);
int i = 0;
//從列表中獲取當前的currentWeight最大的那個作為待響應的節點
for (NodeServer node : list) {
if (node.currentWeight > i) {
i = node.currentWeight;
current = node;
}
}
return current;
}
//請求,每次得到請求的節點之后,需要對當前的節點的currentWeight值減去 sumWeight
public void request() {
NodeServer node = this.getCurrent();
System.out.print(list.toString() + "‐‐‐");
System.out.print(node.ip + "‐‐‐");
node.currentWeight -= total;
System.out.println(list);
}
public static void main(String[] args) throws Exception {
WeightRDD wrr = new WeightRDD("192.168.10.1#4,192.168.10.2#2,192.168.10.3#1");
//7次執行請求,觀察結果
for (int i = 0; i < 7; i++) {
Thread.currentThread().sleep(2000);
wrr.request();
}
}
}從打印輸出結果來看,也是符合預期效果的,具有更大權重的機器,在輪詢中被請求到的可能性更大
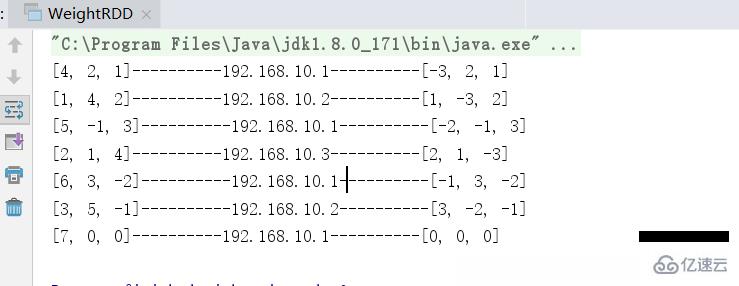
即對當前訪問的ip地址做一個hash值,相同的key將會被路由到同一臺機器去。常見于分布式集群環境下,用戶登錄 時的請求路由和會話保持
源地址hash算法可以有效解決在跨地域機器部署情況下請求響應的問題,這一特點使得源地址hash算法具有某些特殊的應用場景
該算法的核心邏輯是需要自定義一個能結合實際業務場景的hash算法,從而確保請求能夠盡可能達到源IP機器進行處理
源地址hash算法的實現比較簡單,下面直接上代碼
/**
* 源地址請求hash
*/
public class SourceHash {
private static List<String> ips;
//節點初始化
public SourceHash(String nodeNames) {
System.out.println("init list : " + nodeNames);
String[] nodes = nodeNames.split(",");
ips = new ArrayList<>(nodes.length);
for (String node : nodes) {
ips.add(node);
}
}
//添加節點
void addnode(String nodeName) {
System.out.println("add new node : " + nodeName);
ips.add(nodeName);
}
//移除節點
void remove(String nodeName) {
System.out.println("remove one node : " + nodeName);
ips.remove(nodeName);
}
//ip進行hash
private int hash(String ip) {
int last = Integer.valueOf(ip.substring(ip.lastIndexOf(".") + 1, ip.length()));
return last % ips.size();
}
//請求模擬
void request(String ip) {
int i = hash(ip);
System.out.println("req ip : " + ip + "‐‐>" + ips.get(i));
}
public static void main(String[] args) throws Exception {
SourceHash hash = new SourceHash("192.168.10.1,192.168.10.2");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.addnode("192.168.10.3");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.remove("192.168.10.1");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
}
}請關注核心的方法 hash(),我們模擬9個隨機請求的IP,下面運行下這段程序,觀察輸出結果
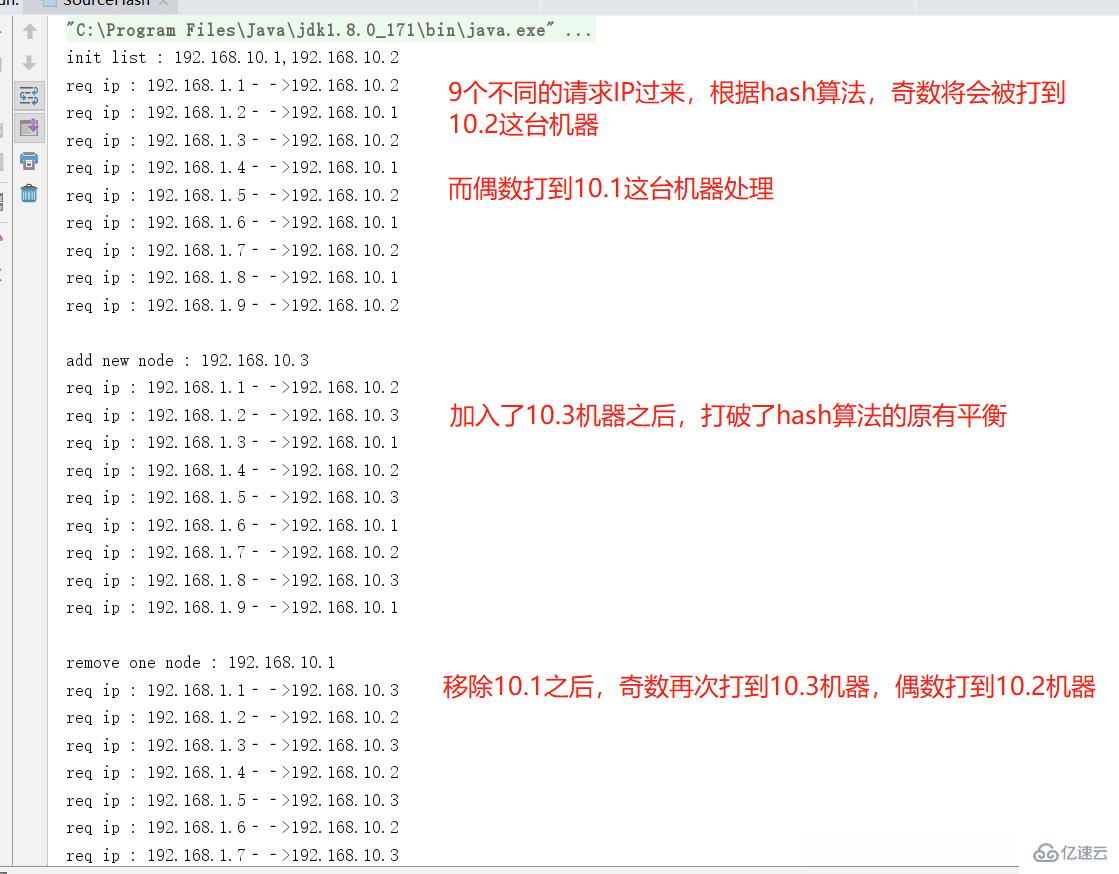
源地址hash算法小結
可以有效匹配同一個源IP從而定向到特定的機器處理
如果hash算法不夠合理,可能造成集群中某些機器壓力非常大
未能很好的解決新節點加入之后打破原來的請求平衡(一致性hash可解決)
即通過統計當前機器的請求連接數,選擇當前連接數最少的機器去響應新請求。前面的各種算法是基于請求的維度,而最小 連接數則是站在機器的連接數量維度
從描述來看,實現這種算法需要定義一個鏈接表記錄機器的節點IP,和機器連接數量的計數器
而為了比較并選擇出最小的連接數的機器,內部采用最小堆做排序處理,請求響應時取堆頂節點即是 最小連接數(可以參考最小頂堆算法)
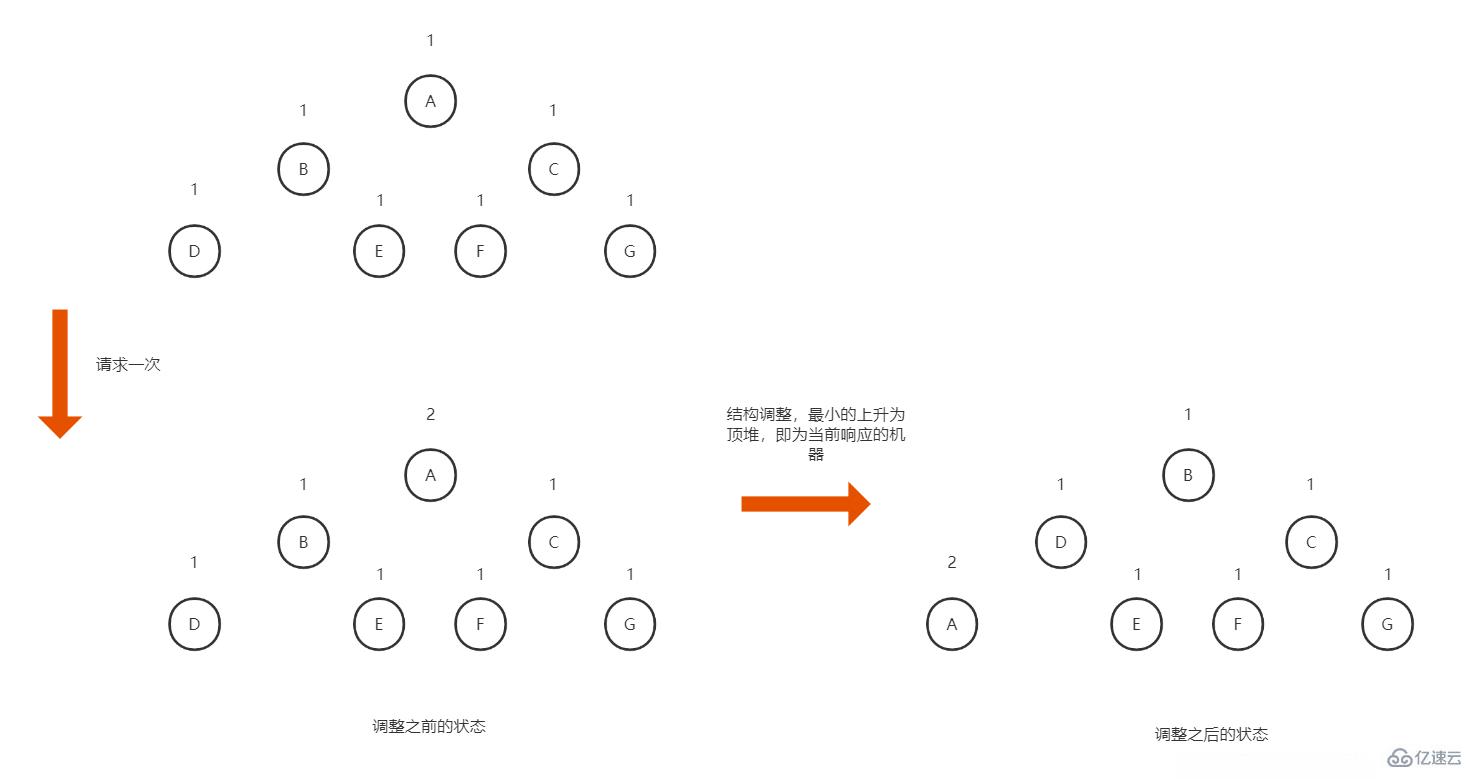
如圖所示,所有機器列表按照類二叉樹的結構進行組裝,組裝的依據按照不同節點的訪問次數,某次請求過來時,選擇堆頂的元素(待響應的機器)返回,然后堆頂機器的請求數量加1,然后通過算法將這個堆頂的元素下沉,把請求數量最小的元素上升為堆頂,以便下次響應最新的請求
1、機器節點
該類記錄了節點的IP以及連接數
class Node {
String name;
AtomicInteger count = new AtomicInteger(0);
public Node(String name) {
this.name = name;
}
public void inc() {
count.getAndIncrement();
}
public int get() {
return count.get();
}
@Override
public String toString() {
return name + "=" + count;
}
}2、核心代碼
/**
* 最小連接數算法
*/
public class LeastRequest {
Node[] nodes;
//節點初始化
public LeastRequest(String ns) {
String[] ns1 = ns.split(",");
nodes = new Node[ns1.length + 1];
for (int i = 0; i < ns1.length; i++) {
nodes[i + 1] = new Node(ns1[i]);
}
}
///節點下沉,與左右子節點比對,選里面最小的交換
//目的是始終保持最小堆的頂點元素值最小【結合圖理解】
//ipNum:要下沉的頂點序號
public void down(int ipNum) {
//頂點序號遍歷,只要到1半即可,時間復雜度為O(log2n)
while (ipNum << 1 < nodes.length) {
int left = ipNum << 1;
//右子,左+1即可
int right = left + 1;
int flag = ipNum;
//標記,指向 本節點,左、右子節點里最小的,一開始取自己
if (nodes[left].get() < nodes[ipNum].get()) {
flag = left;
}
//判斷右子
if (right < nodes.length && nodes[flag].get() > nodes[right].get()) {
flag = right;
}
//兩者中最小的與本節點不相等,則交換
if (flag != ipNum) {
Node temp = nodes[ipNum];
nodes[ipNum] = nodes[flag];
nodes[flag] = temp;
ipNum = flag;
} else {
//否則相等,堆排序完成,退出循環即可
break;
}
}
}
//請求,直接取最小堆的堆頂元素就是連接數最少的機器
public void request() {
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
//取堆頂元素響應請求
Node node = nodes[1];
System.out.println(node.name + " accept");
//連接數加1
node.inc();
//排序前的堆
System.out.println("ip list before:" + Arrays.toString(nodes));
//堆頂下沉,通過算法將堆頂下層到合適的位置
down(1);
//排序后的堆
System.out.println("ip list after:" + Arrays.toString(nodes));
}
public static void main(String[] args) {
//假設有7臺機器
LeastRequest lc = new LeastRequest("10.1,10.2,10.3,10.4,10.5,10.6,10.7");
//模擬10個請求連接
for (int i = 0; i < 10; i++) {
lc.request();
}
}
}請關注 down 方法,該方法是實現每次請求之后,將堆頂元素進行移動的關鍵實現,運行這段代碼,結合輸出結果進行理解


到此,關于“Java負載均衡算法有什么作用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





