溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Mysql常見的慢查詢優化方式有哪些”,在日常操作中,相信很多人在Mysql常見的慢查詢優化方式有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Mysql常見的慢查詢優化方式有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、第一步.開啟mysql慢查詢
方式一:
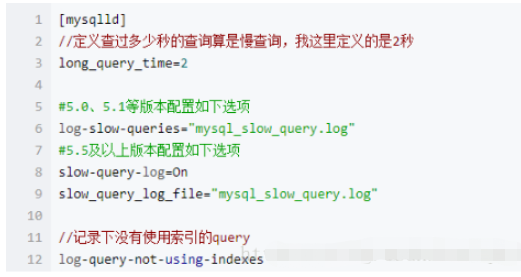
修改配置文件 在 my.ini 增加幾行: 主要是慢查詢的定義時間(超過2秒就是慢查詢),以及慢查詢log日志記錄( slow_query_log)
方法二:通過MySQL數據庫開啟慢查詢:

直接分析mysql慢查詢日志 ,利用explain關鍵字可以模擬優化器執行SQL查詢語句,來分析sql慢查詢語句
例如:執行EXPLAIN SELECT * FROM res_user ORDER BYmodifiedtime LIMIT 0,1000
得到如下結果: 顯示結果分析:
table | type | possible_keys | key |key_len | ref | rows | Extra EXPLAIN列的解釋:
table 顯示這一行的數據是關于哪張表的
type 這是重要的列,顯示連接使用了何種類型。從最好到最差的連接類型為const、eq_reg、ref、range、indexhe和ALL
rows 顯示需要掃描行數
key 使用的索引
(1)索引沒起作用的情況
1. 使用LIKE關鍵字的查詢語句
在使用LIKE關鍵字進行查詢的查詢語句中,如果匹配字符串的第一個字符為“%”,索引不會起作用。只有“%”不在第一個位置索引才會起作用。
2. 使用多列索引的查詢語句
MySQL可以為多個字段創建索引。一個索引最多可以包括16個字段。對于多列索引,只有查詢條件使用了這些字段中的第一個字段時,索引才會被使用。
(2)優化數據庫結構
合理的數據庫結構不僅可以使數據庫占用更小的磁盤空間,而且能夠使查詢速度更快。數據庫結構的設計,需要考慮數據冗余、查詢和更新的速度、字段的數據類型是否合理等多方面的內容。
1. 將字段很多的表分解成多個表
對于字段比較多的表,如果有些字段的使用頻率很低,可以將這些字段分離出來形成新表。因為當一個表的數據量很大時,會由于使用頻率低的字段的存在而變慢。
2. 增加中間表
對于需要經常聯合查詢的表,可以建立中間表以提高查詢效率。通過建立中間表,把需要經常聯合查詢的數據插入到中間表中,然后將原來的聯合查詢改為對中間表的查詢,以此來提高查詢效率。
(3)分解關聯查詢
將一個大的查詢分解為多個小查詢是很有必要的。
很多高性能的應用都會對關聯查詢進行分解,就是可以對每一個表進行一次單表查詢,然后將查詢結果在應用程序中進行關聯,很多場景下這樣會更高效,例如:
SELECT * FROM tag JOIN tag_post ON tag_id = tag.id JOIN post ON tag_post.post_id = post.id WHERE tag.tag = 'mysql'; 分解為: SELECT * FROM tag WHERE tag = 'mysql'; SELECT * FROM tag_post WHERE tag_id = 1234; SELECT * FROM post WHERE post.id in (123,456,567);
(4)優化LIMIT分頁
在系統中需要分頁的操作通常會使用limit加上偏移量的方法實現,同時加上合適的order by 子句。如果有對應的索引,通常效率會不錯,否則MySQL需要做大量的文件排序操作。
一個非常令人頭疼問題就是當偏移量非常大的時候,例如可能是limit 10000,20這樣的查詢,這是mysql需要查詢10020條然后只返回最后20條,前面的10000條記錄都將被舍棄,這樣的代價很高。
優化此類查詢的一個最簡單的方法是盡可能的使用索引覆蓋掃描,而不是查詢所有的列。然后根據需要做一次關聯操作再返回所需的列。對于偏移量很大的時候這樣做的效率會得到很大提升。
對于下面的查詢:
select id,title from collect limit 90000,10;
該語句存在的最大問題在于limit M,N中偏移量M太大(我們暫不考慮篩選字段上要不要添加索引的影響),導致每次查詢都要先從整個表中找到滿足條件 的前M條記錄,之后舍棄這M條記錄并從第M+1條記錄開始再依次找到N條滿足條件的記錄。如果表非常大,且篩選字段沒有合適的索引,且M特別大那么這樣的代價是非常高的。 試想,如我們下一次的查詢能從前一次查詢結束后標記的位置開始查找,找到滿足條件的100條記錄,并記下下一次查詢應該開始的位置,以便于下一次查詢能直接從該位置 開始,這樣就不必每次查詢都先從整個表中先找到滿足條件的前M條記錄,舍棄,在從M+1開始再找到100條滿足條件的記錄了。
方法一:慮篩選字段(title)上加索引
title字段加索引 (此效率如何未加驗證)
方法二:先查詢出主鍵id值
select id,title from collect where id>=(select id from collect order by id limit 90000,1) limit 10;
原理:先查詢出90000條數據對應的主鍵id的值,然后直接通過該id的值直接查詢該id后面的數據。
方法三:“關延遲聯”
如果這個表非常大,那么這個查詢可以改寫成如下的方式:
Select news.id, news.description from news inner join (select id from news order by title limit 50000,5) as myNew using(id);
這里的“關延遲聯”將大大提升查詢的效率,它讓MySQL掃描盡可能少的頁面,獲取需要的記錄后再根據關聯列回原表查詢需要的所有列。這個技術也可以用在優化關聯查詢中的limit。
方法四:建立復合索引 acct_id和create_time
select * from acct_trans_log WHERE acct_id = 3095 order by create_time desc limit 0,10
注意sql查詢慢的原因都是:引起filesort
(5)分析具體的SQL語句 1、兩個表選哪個為驅動表,表面是可以以數據量的大小作為依據,但是實際經驗最好交給mysql查詢優化器自己去判斷。 例如: select * from a where id in (select id from b );
對于這條sql語句它的執行計劃其實并不是先查詢出b表的所有id,然后再與a表的id進行比較。
mysql會把in子查詢轉換成exists相關子查詢,所以它實際等同于這條sql語句:select * from a where exists(select * from b where b.id=a.id );
而exists相關子查詢的執行原理是: 循環取出a表的每一條記錄與b表進行比較,比較的條件是a.id=b.id . 看a表的每條記錄的id是否在b表存在,如果存在就行返回a表的這條記錄。
exists查詢有什么弊端?
由exists執行原理可知,a表(外表)使用不了索引,必須全表掃描,因為是拿a表的數據到b表查。而且必須得使用a表的數據到b表中查(外表到里表中),順序是固定死的。
如何優化?
建索引。但是由上面分析可知,要建索引只能在b表的id字段建,不能在a表的id上,mysql利用不上。
這樣優化夠了嗎?還差一些。
由于exists查詢它的執行計劃只能拿著a表的數據到b表查(外表到里表中),雖然可以在b表的id字段建索引來提高查詢效率。
但是并不能反過來拿著b表的數據到a表查,exists子查詢的查詢順序是固定死的。
為什么要反過來?
因為首先可以肯定的是反過來的結果也是一樣的。這樣就又引出了一個更細致的疑問:在雙方兩個表的id字段上都建有索引時,到底是a表查b表的效率高,還是b表查a表的效率高?
該如何進一步優化?
把查詢修改成inner join連接查詢:select * from a inner join b on a.id=b.id; (但是僅此還不夠,接著往下看)
為什么不用left join 和 right join?
這時候表之間的連接的順序就被固定住了,比如左連接就是必須先查左表全表掃描,然后一條一條的到另外表去查詢,右連接同理。仍然不是最好的選擇。
為什么使用inner join就可以?
inner join中的兩張表,如: a inner join b,但實際執行的順序是跟寫法的順序沒有半毛錢關系的,最終執行也可能會是b連接a,順序不是固定死的。如果on條件字段有索引的情況下,同樣可以使用上索引。
那我們又怎么能知道a和b什么樣的執行順序效率更高?
你不知道,我也不知道。誰知道?mysql自己知道。讓mysql自己去判斷(查詢優化器)。具體表的連接順序和使用索引情況,mysql查詢優化器會對每種情況做出成本評估,最終選擇最優的那個做為執行計劃。
在inner join的連接中,mysql會自己評估使用a表查b表的效率高還是b表查a表高,如果兩個表都建有索引的情況下,mysql同樣會評估使用a表條件字段上的索引效率高還是b表的。
利用explain字段查看執行時運用到的key(索引)
而我們要做的就是:把兩個表的連接條件的兩個字段都各自建立上索引,然后explain 一下,查看執行計劃,看mysql到底利用了哪個索引,最后再把沒有使用索引的表的字段索引給去掉就行了。
到此,關于“Mysql常見的慢查詢優化方式有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





