溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python數據可視化實例應用分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
數據可視化是指用圖形或表格的方式來呈現數據。圖表能夠清楚地呈現數據性質, 以及數據間或屬性間的關系,可以輕易地讓人看圖釋義。用戶通過探索圖(Exploratory Graph)可以了解數據的特性、尋找數據的趨勢、降低數據的理解門檻。
本章主要采用 Pandas 的方式來畫圖,而不是使用 Matplotlib 模塊。其實 Pandas 已經把 Matplotlib 的畫圖方法整合到 DataFrame 中,因此在實際應用中,用戶不需要直接引用 Matplotlib 也可以完成畫圖的工作。
折線圖(line chart)是最基本的圖表,可以用來呈現不同欄位連續數據之間的關系。繪制折線圖使用的是 plot.line() 的方法,可以設置顏色、形狀等參數。在使用上,拆線圖繪制方法完全繼承了 Matplotlib 的用法,所以程序最后也必須調用 plt.show() 產生圖,如圖8.4 所示。
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
散布圖(Scatter Chart)用于檢視不同欄位離散數據之間的關系。繪制散布圖使用的是 df.plot.scatter(),如圖8.5所示。
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
直方圖(Histogram Chart)通常用于同一欄位,呈現連續數據的分布狀況,與直方圖類似的另一種圖是長條圖(Bar Chart),用于檢視同一欄位,如圖 8.6 所示。
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
圓餅圖(Pie Chart)可以用于檢視同一欄位各類別所占的比例,而箱形圖(Box Chart)則用于檢視同一欄位或比較不同欄位數據的分布差異,如圖 8.7 所示。
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],?gsize=(10,5))
本節利用兩個真實的數據集實際展示數據探索的幾種手法。
在美國社區調查(American Community Survey)中,每年約有 350 萬個家庭被問到關于他們是誰及他們如何生活的詳細問題。調查的內容涵蓋了許多主題,包括祖先、教育、工作、交通、互聯網使用和居住。
先觀察數據的樣子與特性,以及每個欄位代表的意義、種類和范圍。
# 讀取數據
df = pd.read_csv("./ss13husa.csv")
# 欄位種類數量
df.shape
# (756065,231)
# 欄位數值范圍
df.describe()先將兩個 ss13pusa.csv 串連起來,這份數據總共包含 30 萬筆數據,3 個欄位:SCHL ( 學歷,School Level)、 PINCP ( 收入,Income) 和 ESR ( 工作狀態,Work Status)。
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接兩份數據
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)依據學歷對數據進行分群,觀察不同學歷的數量比例,接著計算他們的平均收入。
group = df['ac_survey'].groupby(by=['SCHL']) print('學歷分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())波士頓房屋數據集(Boston House Price Dataset)包含有關波士頓地區的房屋信息, 包 506 個數據樣本和 13 個特征維度。
數據來源:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/。
數據名稱:Boston House Price Dataset。
先觀察數據的樣子與特性,以及每個欄位代表的意義、種類和范圍。
可以用直方圖的方式畫出房價(MEDV)的分布,如圖 8.8 所示。
df = pd.read_csv("./housing.data")
# 欄位種類數量
df.shape
# (506, 14)
#欄位數值范圍df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()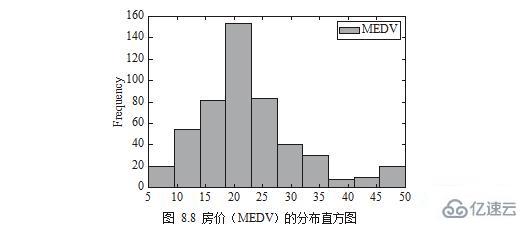
注:圖中英文對應筆者在代碼中或數據中指定的名字,實踐中讀者可將它們替換成自己需要的文字。
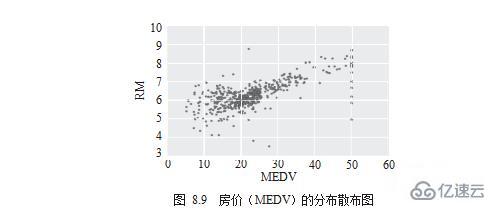
接下來需要知道的是哪些維度與“房價”關系明顯。先用散布圖的方式來觀察,如圖8.9所示。
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()
最后,計算相關系數并用聚類熱圖(Heatmap)來進行視覺呈現,如圖 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
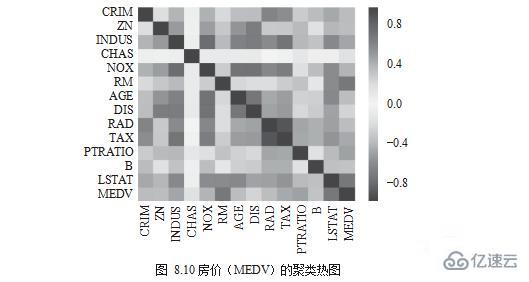
顏色為紅色,表示正向關系;顏色為藍色,表示負向關系;顏色為白色,表示沒有關系。RM 與房價關聯度偏向紅色,為正向關系;LSTAT、PTRATIO 與房價關聯度偏向深藍, 為負向關系;CRIM、RAD、AGE 與房價關聯度偏向白色,為沒有關系。
“Python數據可視化實例應用分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





