溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用Python采集某度貼吧排行榜”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
我們首先確定我們的目標網址,對我們需要獲取的數據。
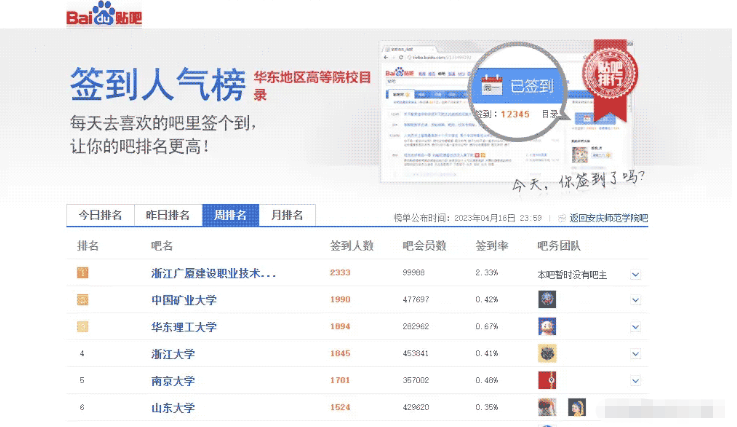
我們要把每一行的數據獲取下來,我們接下來用到開發者工具。我們看評論是在什么位置。是不是在網頁源代碼中。接下來,我們發送請求,獲取網頁源代碼。
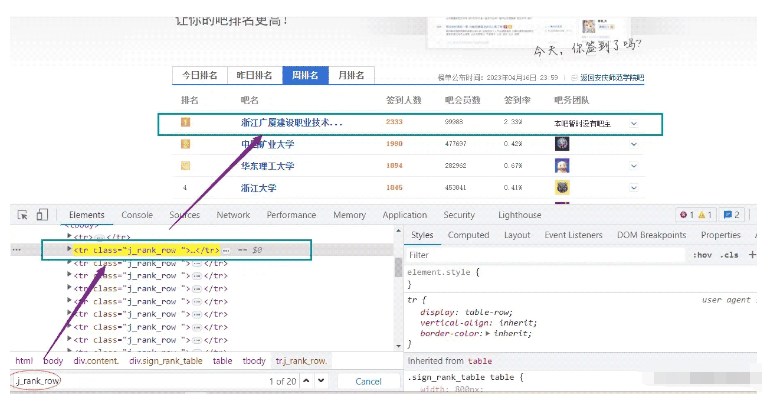
我們這里可以看到,我們選擇一個css選擇器,取匹配我們要的數據。
url = f'https://tieba.baidu.com/sign/index?kw=%B0%B2%C7%EC%CA%A6%B7%B6%D1%A7%D4%BA&type=2&pn=1' # 158 res = requests.get(url)
代碼使用requests庫的get()函數來請求這個URL,并將結果存儲在變量res中。
我們還可以獲取其他信息,比如講,排名,學校,人數,簽到率之類的。
selector = parsel.Selector(res.text)
info_lists = selector.css('.j_rank_row')這段代碼首先導入了parsel庫,然后使用Selector函數創建了一個選擇器對象selector。res.text是從響應中獲取的文本內容,css()方法用于選擇CSS樣式,.j_rank_row是CSS選擇器,用于選擇所有.j_rank_row類的元素。
接下來,代碼使用selector.css()方法選擇所有.j_rank_row類的元素,并將它們存儲在info_lists變量中。這些元素將成為BeautifulSoup對象soup的一部分。
上面我們已經得到了.j_rank_row位置,接下來,就是把內容獲取下來。我們看看代碼怎么寫。
for info_list in info_lists:
rank = info_list.css('.rank_index div::text').get()
# print(rank)
name = info_list.css('.forum_name a::text').get()
signin = info_list.css('.forum_sign_num::text').get()
theTotalNumberOf = info_list.css('.forum_member::text').get()
signInToRate = info_list.css('.forum_sign_rate::text').get()這段代碼將遍歷info_lists列表中的每個元素,并使用CSS選擇器選擇.rank_index類的元素,然后使用.rank_index div::text選擇.rank_index類的文本內容,使用.forum_name a::text選擇.forum_name類的文本內容,使用.forum_sign_num::text選擇.forum_sign_num類的文本內容,使用.forum_member::text選擇.forum_member類的文本內容,使用.forum_sign_rate::text選擇.forum_sign_rate類的文本內容。
然后,代碼將獲取每個元素的.rank_index div::text文本內容,并使用.get()方法獲取其中的.rank_index值。接下來,代碼將獲取每個元素的.forum_name a::text文本內容,并使用.get()方法獲取其中的.forum_name值。接下來,代碼將獲取每個元素的.forum_sign_num::text文本內容,并使用.get()方法獲取其中的.forum_sign_num值。接下來,代碼將獲取每個元素的.forum_member::text文本內容,并使用.get()方法獲取其中的.forum_member值。最后,代碼將獲取每個元素的.forum_sign_rate::text文本內容,并使用.get()方法獲取其中的.forum_sign_rate值。
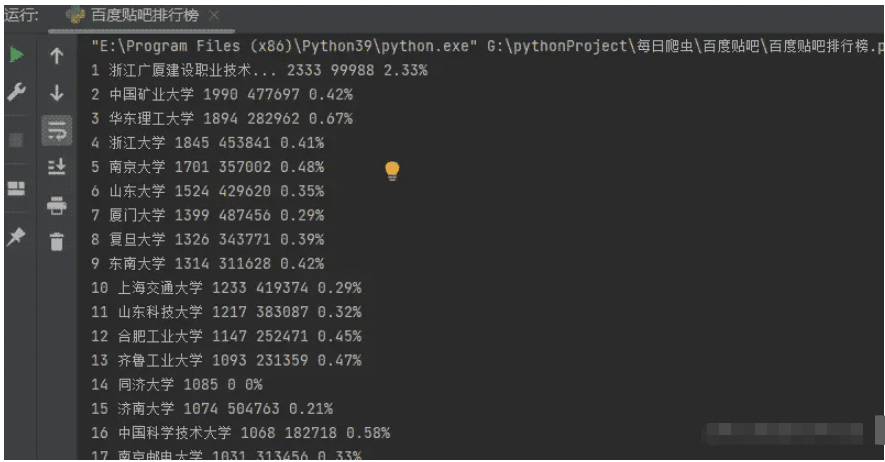
我們把獲取到的內容保存成csv文件,之前我們說了很多遍,直接上代碼。
f = open('百度貼吧排行榜.csv', mode='a', encoding='utf-8_sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['排名', '學校', '簽到人數', '吧會員數', '簽到率'])
csv_writer.writeheader()這段代碼打開了一個名為“百度貼吧排行榜.csv”的文件,并創建了一個名為“csv_writer”的CSV寫入器對象。mode='a'參數指定文件以追加模式打開,encoding='utf-8_sig'參數指定文件編碼為UTF-8-sig,newline=''參數指定行尾符為空字符串。
然后,csv_writer.writeheader()方法被調用,它將寫入CSV文件的標題行。這些標題行包括排名、學校、簽到人數、吧會員數和簽到率。
我們把上面的數據保存成字典的格式,寫入csv文件。
dit = {
'排名': rank,
'學校': name,
'簽到人數': signin,
'吧會員數': theTotalNumberOf,
'簽到率': signInToRate,
}
# print(dit)
csv_writer.writerow(dit)這段代碼創建了一個字典dit,其中包含了每個元素的值。然后,它使用csv_writer.writerow()方法將字典寫入CSV文件中。
具體來說,這段代碼首先打開了一個名為“百度貼吧排行榜.csv”的文件,并創建了一個名為“csv_writer”的CSV寫入器對象。然后,它使用csv_writer.writeheader()方法寫入了CSV文件的標題行,包括排名、學校、簽到人數、吧會員數和簽到率。最后,它使用csv_writer.writerow()方法將字典dit寫入CSV文件中。
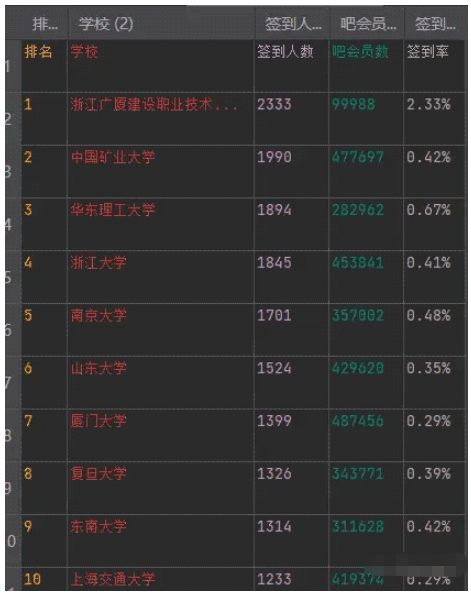
“怎么使用Python采集某度貼吧排行榜”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





