溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“MYSQL之on和where的區別是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“MYSQL之on和where的區別是什么”文章吧。
多表查詢語法結構:
table_reference {[INNER] JOIN | {LEFT|RIGHT} [OUTER] JOIN} table_reference ON conditional_expr在多表查詢時,ON和where都表示篩選條件,on先執行,where后執行。
外連接時,on條件是在生成臨時表時使用的條件,它不管on中的條件是否為真,都會返回左邊表中的記錄。而where條件是在臨時表生成好后,再對臨時表進行過濾的條件。
如:
SELECT * FROM emp e LEFT JOIN dept d ON e.deptno=d.`deptno` AND e.`deptno`=40;
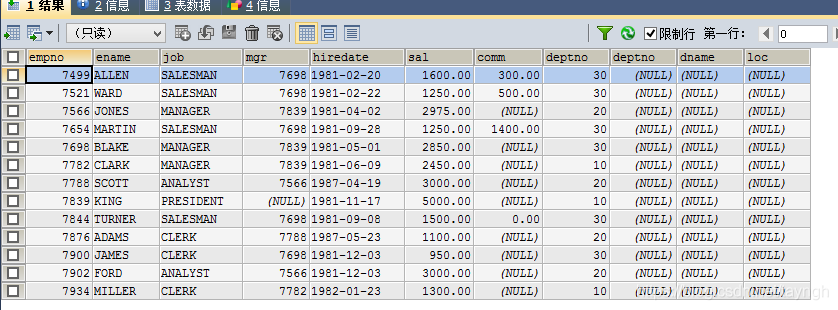
SELECT * FROM emp e LEFT JOIN dept d ON e.deptno=d.`deptno` WHERE e.`deptno`=40;

來我們分析一下為什么會造成以上兩種不同的結果。
on是生成臨時表時使用的條件,上面我們采用的是左外連接,左外連接是以左表為基礎的,左表的記錄將會全部表示出來,而右表只會顯示符合搜索條件的記錄。也就是說emp是左表,dept是右表,條件是emp的deptno與dept中的deptno相等且為40時才連接,但emp表中不存在deptno為40的記錄,也就是右表沒有符合條件的記錄,而記錄不足的地方均用NULL來補充。
而where是在臨時表生成好后,再對臨時表進行過濾。也就是說emp表與dept的連接條件只是emp的deptno與dept中的deptno相等,然后在對生成的臨時表進行篩選,由于emp表中不存在deptno為40的記錄,所以未找到符合條件的記錄。
由于內連接是從結果表中刪除與其他被連接表中沒有匹配行的所有行,所有在內連接時on和where的結果是相同的。而左外、右外與全連接由于它的特殊性,on和where造成的差別大小取決于表達式和表中的數據。
數據庫在通過連接兩張或多張表來返回記錄時,都會生成一張中間的臨時表,然后再將這張臨時表返回給用戶。
在使用left jion時,on和where條件的區別如下:
1、 on條件是在生成臨時表時使用的條件,它不管on中的條件是否為真,都會返回左邊表中的記錄。
2、where條件是在臨時表生成好后,再對臨時表進行過濾的條件。這時已經沒有left join的含義(必須返回左邊表的記錄)了,條件不為真的就全部過濾掉。假設有兩張表:
表1:tab1
id | size |
1 | 10 |
2 | 20 |
3 | 30 |
表2:tab2
size | name |
10 | AAA |
20 | BBB |
20 | CCC |
兩條SQL:
1、select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name='AAA' 2、select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name='AAA')
第一條SQL的過程:
| 1、中間表on條件:tab1.size = tab2.size | tab1.idtab1.sizetab2.sizetab2.name11010AAA22020BBB22020CCC330(null)(null) |
2、再對中間表過濾where 條件:tab2.name=’AAA’ | tab1.idtab1.sizetab2.sizetab2.name11010AAA |
第二條SQL的過程:
| 1、中間表on條件:tab1.size = tab2.size and tab2.name=’AAA’(條件不為真也會返回左表中的記錄) | tab1.idtab1.sizetab2.sizetab2.name11010AAA220(null)(null)330(null)(null) |
其實以上結果的關鍵原因就是left join,right join,full join的特殊性,不管on上的條件是否為真都會返回left或right表中的記錄,full則具有left和right的特性的并集。
而inner jion沒這個特殊性,則條件放在on中和where中,返回的結果集是相同的。
on、where、having這三個都可以加條件的子句中,on是最先執行,where次之,having最后。有時候如果這先后順序不影響中間結果的話,那最終結果是相同的。但因為on是先把不符合條件的記錄過濾后才進行統計,它就可以減少中間運算要處理的數據,按理說應該速度是最快的。
根據上面的分析,可以知道where也應該比having快點的,因為它過濾數據后才進行sum,所以having是最慢的。但也不是說having沒用,因為有時在步驟3還沒出來都不知道那個記錄才符合要求時,就要用having了。
在兩個表聯接時才用on的,所以在一個表的時候,就剩下where跟having比較了。在這單表查詢統計的情況下,如果要過濾的條件沒有涉及到要計算字段,那它們的結果是一樣的,只是where可以使用rushmore技術,而having就不能,在速度上后者要慢。
如果要涉及到計算的字段,就表示在沒計算之前,這個字段的值是不確定的,根據上篇寫的工作流程,where的作用時間是在計算之前就完成的,而having就是在計算后才起作用的,所以在這種情況下,兩者的結果會不同。
在多表聯接查詢時,on比where更早起作用。系統首先根據各個表之間的聯接條件,把多個表合成一個臨時表后,再由where進行過濾,然后再計算,計算完后再由having進行過濾。由此可見,要想過濾條件起到正確的作用,首先要明白這個條件應該在什么時候起作用,然后再決定放在那里。
Ps:JOIN聯表中ON、WHERE后面跟條件的區別對于JOIN的連表操作,這里就不細述了,當我們在對表進行JOIN關聯操作時,對于ON和WHERE后面的條件,不清楚大家有沒有注意過,有什么區別,可能有的朋友會認為跟在它們后面的條件是一樣的,你可以跟在ON后面,如果愿意,也可以跟在WHERE后面。它們在ON和WHERE后面究竟有一個什么樣的區別呢?
對于JOIN參與的表的關聯操作,如果需要不滿足連接條件的行也在我們的查詢范圍內的話,我們就必需把連接條件放在ON后面,而不能放在WHERE后面,如果我們把連接條件放在了WHERE后面,那么所有的LEFT、RIGHT,等這些操作將不起任何作用,對于這種情況,它的效果就完全等同于INNER連接。對于那些不影響選擇行的條件,放在ON或者WHERE后面就可以。
記住:所有的連接條件都必需要放在ON后面,不然前面的所有 LEFT 和 RIGHT 關聯將作為擺設,而不起任何作用。
我們在進行表連接查詢的時候一般都會使用JOIN xxx ON xxx的語法,ON語句的執行是在JOIN語句之前的,也就是說兩張表數據行之間進行匹配的時候,會先判斷數據行是否符合ON語句后面的條件,再決定是否JOIN。
口訣:先執行 ON,后執行 WHERE;ON 是建立關聯關系,WHERE 是對關聯關系的篩選。
以上就是關于“MYSQL之on和where的區別是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





