溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Python浮點數乘法和整形乘除法的效率實例分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
我們每次把整形加減自身/10,來模擬上下浮動10%,并把浮點形乘1.1(0.9)并修正eps精度誤差。
測試代碼如下:
int main()
{
const int N=1e8;
int64_t t1=clk();
for(int i=0;i<N;i++)
{
long long x=i;
x=x+x/10;
x=x-x/10;
}
int64_t t2=clk();
for(int i=0;i<N;i++)
{
double x=i;
x=x*1.1+1e-5;
x=x*0.9-1e-5;
}
int64_t t3=clk();
cout<<"long long "<<t2-t1<<endl;
cout<<"double "<<t3-t2<<endl;
}結果:
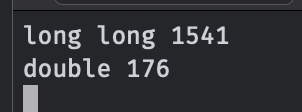
long long花了1541ms,是double的幾乎十倍。
除法相較于加減乘有較大的常數。
現在再試試另一種方法,即把0.9x<y<1.1x變成9x<10y<11x的形式,這樣不就全是整形乘法了嗎?但是三次整形乘法和兩次浮點乘法兩次浮點加減法哪個慢呢?
測試代碼如下:
int main()
{
const int N=1e8;
int64_t t1=clk();
for(int i=0;i<N;i++)
{
long long x=i;
x=x*11;
x=x*9;
x=x*10;
}
int64_t t2=clk();
for(int i=0;i<N;i++)
{
double x=i;
x=x*1.1+1e-5;
x=x*0.9-1e-5;
}
int64_t t3=clk();
cout<<"long long "<<t2-t1<<endl;
cout<<"double "<<t3-t2<<endl;
}結果:
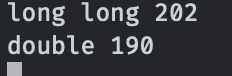
我們可以看到,雖然單次浮點乘法的常數會略大于整形乘法,但是三次整形乘法還是慢于兩次浮點乘法的。
測試代碼:
int main()
{
const int N=1e8;
int64_t t1=clk();
for(int i=0;i<N;i++)
{
long long x=i;
x=x*11ll;
}
int64_t t2=clk();
for(int i=0;i<N;i++)
{
double x=i;
x=x*1.1;
}
int64_t t3=clk();
cout<<"long long "<<t2-t1<<endl;
cout<<"double "<<t3-t2<<endl;
}結果:
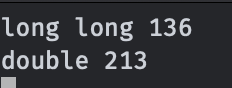
我們可以看到,單次浮點乘法的常數大概會比整形大50%左右,所以三次整形乘法還是略慢于兩次浮點乘法的。
以上就是“Python浮點數乘法和整形乘除法的效率實例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





