溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“python怎么利用多線程+隊列技術爬取中介網互聯網網站排行榜”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
本次要抓取的目標站點為:中介網,這個網站提供了網站排行榜、互聯網網站排行榜、中文網站排行榜等數據。
網站展示的樣本數據量是 :58341。
采集頁面地址為 https://www.zhongjie.com/top/rank_all_1.html,
UI如下所示:
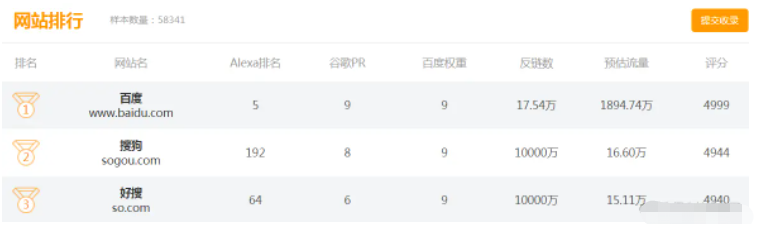
由于頁面存在一個【尾頁】超鏈接,所以直接通過該超鏈接獲取累計頁面即可。
其余頁面遵循簡單分頁規則:
https://www.zhongjie.com/top/rank_all_1.html https://www.zhongjie.com/top/rank_all_2.html
基于此,本次Python爬蟲的解決方案如下,頁面請求使用 requests 庫,頁面解析使用 lxml,多線程使用 threading 模塊,隊列依舊采用 queue 模塊。
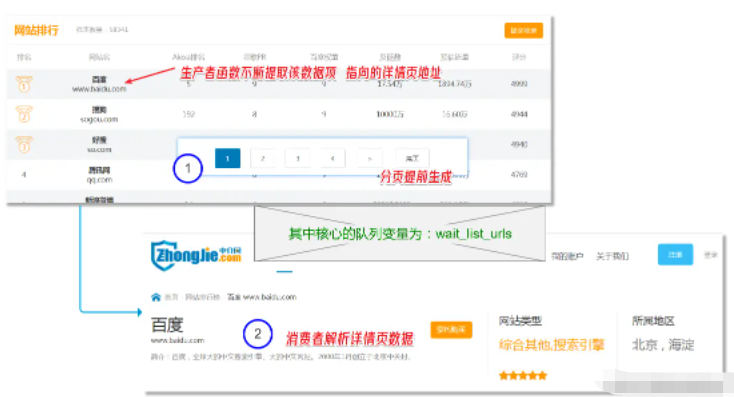
在正式編碼前,先通過一張圖將邏輯進行梳理。
本爬蟲編寫步驟文字描述如下:
預先請求第一頁,解析出總頁碼;
通過生產者不斷獲取域名詳情頁地址,添加到隊列中;
消費者函數從隊列獲取詳情頁地址,解析目標數據。
總頁碼的生成代碼非常簡單
def get_total_page():
# get_headers() 函數,可參考開源代碼分享數據
res = requests.get(
'https://www.zhongjie.com/top/rank_all_1.html', headers=get_headers(), timeout=5)
element = etree.HTML(res.text)
last_page = element.xpath("//a[@class='weiye']/@href")[0]
pattern = re.compile('(\d+)')
page = pattern.search(last_page)
return int(page.group(1))總頁碼生成完畢,就可以進行多線程相關編碼,本案例未編寫存儲部分代碼,留給你自行完成啦,
完整代碼如下所示:
from queue import Queue
import time
import threading
import requests
from lxml import etree
import random
import re
def get_headers():
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)"
]
ua = random.choice(uas)
headers = {
"user-agent": ua
}
return headers
def get_total_page():
res = requests.get(
'https://www.zhongjie.com/top/rank_all_1.html', headers=get_headers(), timeout=5)
element = etree.HTML(res.text)
last_page = element.xpath("//a[@class='weiye']/@href")[0]
pattern = re.compile('(\d+)')
page = pattern.search(last_page)
return int(page.group(1))
# 生產者
def producer():
while True:
# 取一個分類ID
url = urls.get()
urls.task_done()
if url is None:
break
res = requests.get(url=url, headers=get_headers(), timeout=5)
text = res.text
element = etree.HTML(text)
links = element.xpath('//a[@class="copyright_title"]/@href')
for i in links:
wait_list_urls.put("https://www.zhongjie.com" + i)
# 消費者
def consumer():
while True:
url = wait_list_urls.get()
wait_list_urls.task_done()
if url is None:
break
res = requests.get(url=url, headers=get_headers(), timeout=5)
text = res.text
element = etree.HTML(text)
# 數據提取,更多數據提取,可自行編寫 xpath
title = element.xpath('//div[@class="info-head-l"]/h2/text()')
link = element.xpath('//div[@class="info-head-l"]/p[1]/a/text()')
description = element.xpath('//div[@class="info-head-l"]/p[2]/text()')
print(title, link, description)
if __name__ == "__main__":
# 初始化一個隊列
urls = Queue(maxsize=0)
last_page = get_total_page()
for p in range(1, last_page + 1):
urls.put(f"https://www.zhongjie.com/top/rank_all_{p}.html")
wait_list_urls = Queue(maxsize=0)
# 開啟2個生產者線程
for p_in in range(1, 3):
p = threading.Thread(target=producer)
p.start()
# 開啟2個消費者線程
for p_in in range(1, 2):
p = threading.Thread(target=consumer)
p.start()“python怎么利用多線程+隊列技術爬取中介網互聯網網站排行榜”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





