溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“pytorch中的transforms.ToTensor和transforms.Normalize怎么實現”,內容詳細,步驟清晰,細節處理妥當,希望這篇“pytorch中的transforms.ToTensor和transforms.Normalize怎么實現”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
最近看pytorch時,遇到了對圖像數據的歸一化,如下圖所示:

該怎么理解這串代碼呢?我們一句一句的來看,先看transforms.ToTensor(),我們可以先轉到官方給的定義,如下圖所示:

大概的意思就是說,transforms.ToTensor()可以將PIL和numpy格式的數據從[0,255]范圍轉換到[0,1] ,具體做法其實就是將原始數據除以255。另外原始數據的shape是(H x W x C),通過transforms.ToTensor()后shape會變為(C x H x W)。這樣說我覺得大家應該也是能理解的,這部分并不難,但想著還是用一些例子來加深大家的映像
先導入一些包
import cv2 import numpy as np import torch from torchvision import transforms
定義一個數組模型圖片,注意數組數據類型需要時np.uint8【官方圖示中給出】
data = np.array([ [[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]], [[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]], [[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]], [[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]], [[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]] ],dtype='uint8')
這是可以看看data的shape,注意現在為(W H C)。
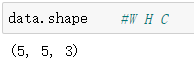
使用transforms.ToTensor()將data進行轉換
data = transforms.ToTensor()(data)
這時候我們來看看data中的數據及shape。
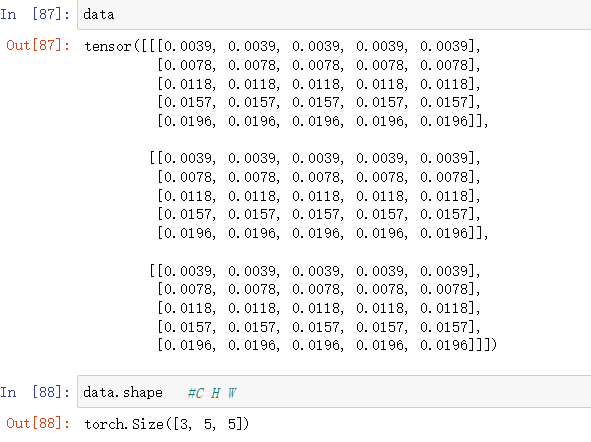
很明顯,數據現在都映射到了[0, 1]之間,并且data的shape發生了變換。
**注意:不知道大家是如何理解三維數組的,這里提供我的一個方法。
原始的data的shape為(5,5,3),則其表示有5個(5 , 3)的二維數組,即我們把最外層的[]去掉就得到了5個五行三列的數據。同樣的,變換后data的shape為(3,5,5),則其表示有3個(5 , 5)的二維數組,即我們把最外層的[]去掉就得到了3個五行五列的數據。
相信通過前面的敘述大家應該對transforms.ToTensor有了一定的了解,下面將來說說這個transforms.Normalize????????????同樣的,我們先給出官方的定義,如下圖所示:
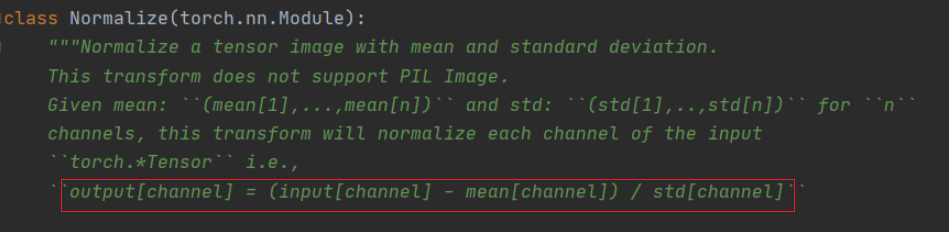
可以看到這個函數的輸出output[channel] = (input[channel] - mean[channel]) / std[channel]。這里[channel]的意思是指對特征圖的每個通道都進行這樣的操作。【mean為均值,std為標準差】接下來我們看第一張圖片中的代碼,即

這里的第一個參數(0.5,0.5,0.5)表示每個通道的均值都是0.5,第二個參數(0.5,0.5,0.5)表示每個通道的方差都為0.5。【因為圖像一般是三個通道,所以這里的向量都是1x3的】有了這兩個參數后,當我們傳入一個圖像時,就會按照上面的公式對圖像進行變換。【注意:這里說圖像其實也不夠準確,因為這個函數傳入的格式不能為PIL Image,我們應該先將其轉換為Tensor格式】
說了這么多,那么這個函數到底有什么用呢?我們通過前面的ToTensor已經將數據歸一化到了0-1之間,現在又接上了一個Normalize函數有什么用呢?其實Normalize函數做的是將數據變換到了[-1,1]之間。之前的數據為0-1,當取0時,output =(0 - 0.5)/ 0.5 = -1;當取1時,output =(1 - 0.5)/ 0.5 = 1。這樣就把數據統一到了[-1,1]之間了那么問題又來了,數據統一到[-1,1]有什么好處呢?數據如果分布在(0,1)之間,可能實際的bias,就是神經網絡的輸入b會比較大,而模型初始化時b=0的,這樣會導致神經網絡收斂比較慢,經過Normalize后,可以加快模型的收斂速度。【這句話是再網絡上找到最多的解釋,自己也不確定其正確性】
讀到這里大家是不是以為就完了呢?這里還想和大家嘮上一嘮上面的兩個參數(0.5,0.5,0.5)是怎么得來的呢?這是根據數據集中的數據計算出的均值和標準差,所以往往不同的數據集這兩個值是不同的?這里再舉一個例子幫助大家理解其計算過程。同樣采用上文例子中提到的數據。
上文已經得到了經ToTensor轉換后的數據,現需要求出該數據每個通道的mean和std。
# 需要對數據進行擴維,增加batch維度 data = torch.unsqueeze(data,0) #在pytorch中一般都是(batch,C,H,W) nb_samples = 0. #創建3維的空列表 channel_mean = torch.zeros(3) channel_std = torch.zeros(3) N, C, H, W = data.shape[:4] data = data.view(N, C, -1) #將數據的H,W合并 #展平后,w,h屬于第2維度,對他們求平均,sum(0)為將同一緯度的數據累加 channel_mean += data.mean(2).sum(0) #展平后,w,h屬于第2維度,對他們求標準差,sum(0)為將同一緯度的數據累加 channel_std += data.std(2).sum(0) #獲取所有batch的數據,這里為1 nb_samples += N #獲取同一batch的均值和標準差 channel_mean /= nb_samples channel_std /= nb_samples print(channel_mean, channel_std) #結果為tensor([0.0118, 0.0118, 0.0118]) tensor([0.0057, 0.0057, 0.0057])
將上述得到的mean和std帶入公式,計算輸出。
for i in range(3): data[i] = (data[i] - channel_mean[i]) / channel_std[i] print(data)
輸出結果:

從結果可以看出,我們計算的mean和std并不是0.5,且最后的結果也沒有在[-1,1]之間。
讀到這里,這篇“pytorch中的transforms.ToTensor和transforms.Normalize怎么實現”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





