溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Apache Hudi結合Flink的示例分析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!

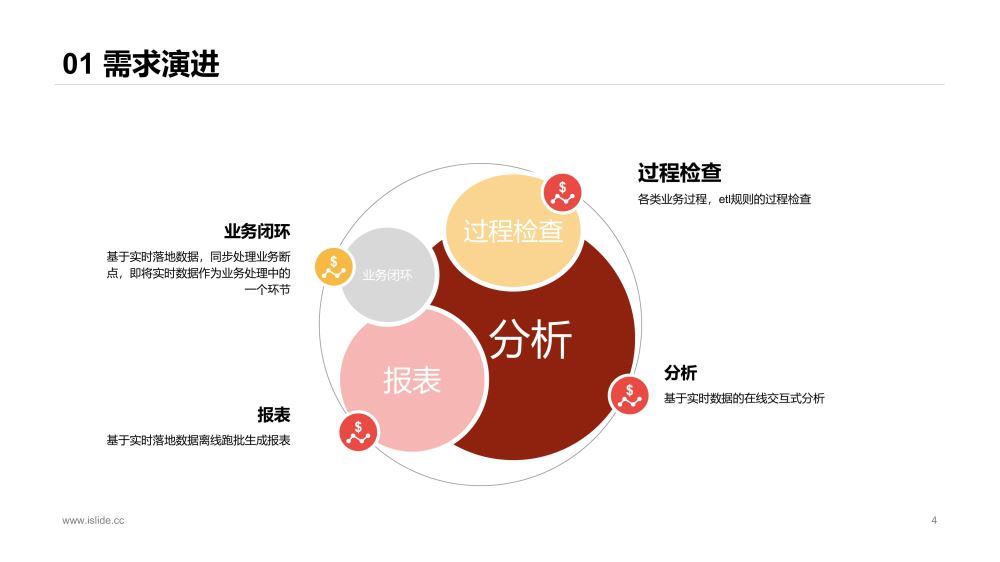
實時平臺上線后,主要需求是開發實時報表,即抽取各類數據源做實時etl后,吐出實時指標到oracle庫中供展示查詢。
隨著實時平臺的穩定及推廣開放,各種使用人員有了更廣發的需求:
對實時開發來說,需要將實時sql數據落地做一些etl調試,數據取樣等過程檢查;
數據分析、業務等希望能結合數倉已有數據體系,對實時數據進行分析和洞察,比如用戶行為實時埋點數據結合數倉已有一些模型進行分析,而不是僅僅看一些高度聚合化的報表;
業務希望將實時數據作為業務過程的一環進行業務驅動,實現業務閉環;
針對部分需求,需要將實時數據落地后,結合其他數倉數據,T - 1離線跑批出報表;
>
除了上述列舉的主要的需求,還有一些零碎的需求。
總的來說,實時平臺輸出高度聚合后的數據給用戶,已經滿足不了需求,用戶渴求更細致,更原始,更自主,更多可能的數據
而這需要平臺能將實時數據落地至離線數倉體系中,因此,基于這些需求演進,實時平臺開始了實時數據落地的探索實踐
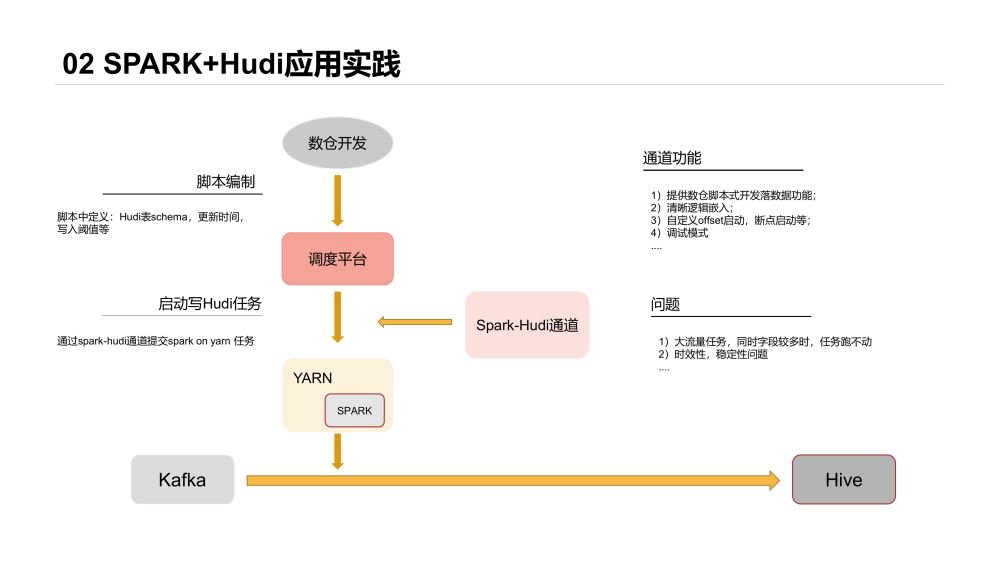
最早開始選型的是比較流行的Spark + Hudi體系,整體落地架構如下:
這套主要基于以下考慮:
數倉開發不需寫Scala/Java打Jar包做任務開發
ETL邏輯能夠嵌入落數據任務中
開發入口統一
我們當時做了通用的落數據通道,通道由Spark任務Jar包和Shell腳本組成,數倉開發入口為統一調度平臺,將落數據的需求轉化為對應的Shell參數,啟動腳本后完成數據的落地。
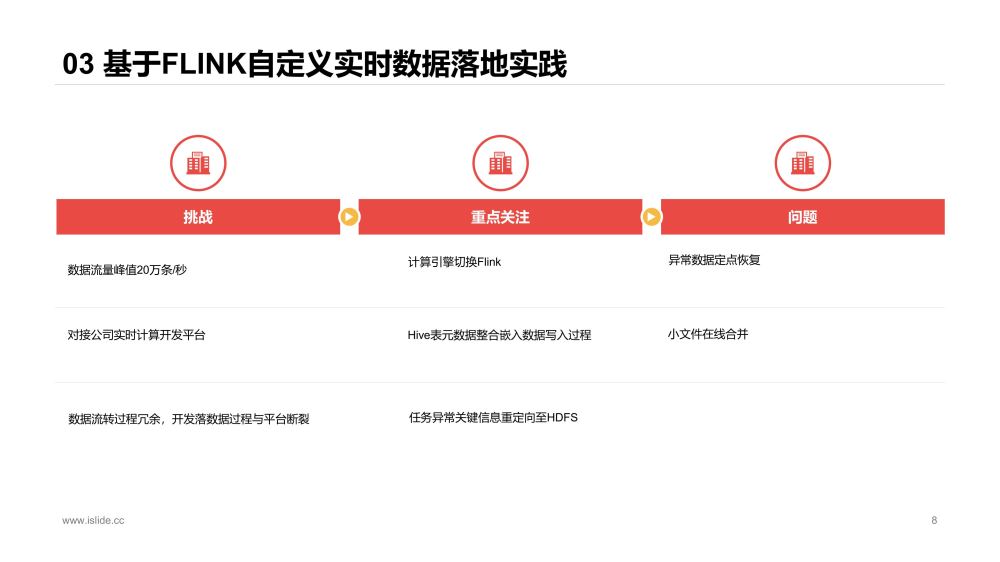
由于我們當時實時平臺是基于Flink,同時Spark+Hudi對于大流量任務的支持有一些問題,比如落埋點數據時,延遲升高,任務經常OOM等,因此決定探索Flink落數據的路徑。
當時Flink+Hudi社區還沒有實現,我們參考Flink+ORC的落數據的過程,做了實時數據落地的實現,主要是做了落數據Schema的參數化定義,使數據開發同事能shell化實現數據落地。
Hudi整合Flink版本出來后,實時平臺就著手準備做兼容,把Hudi納入了實時平臺開發內容。
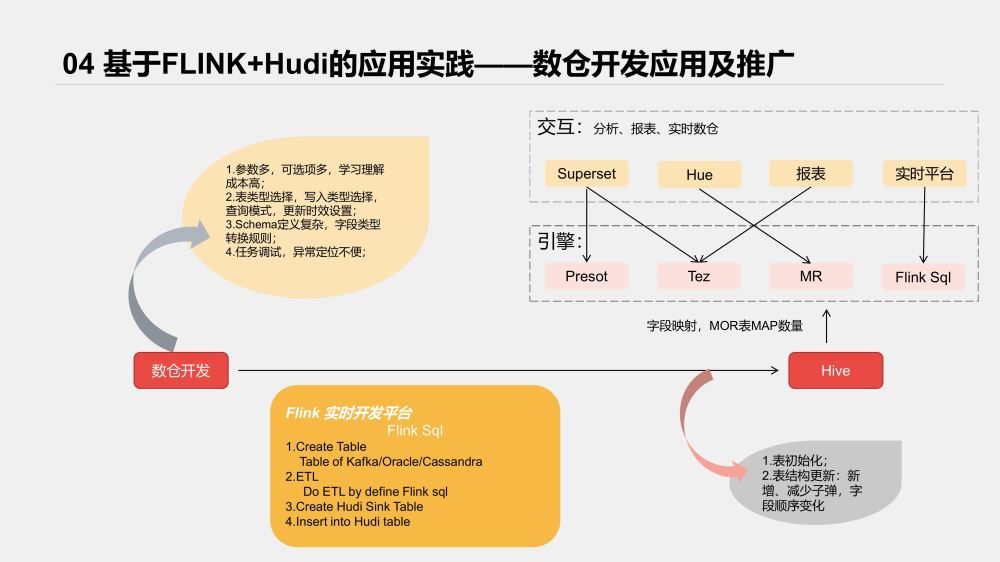
先看下接入后整體架構
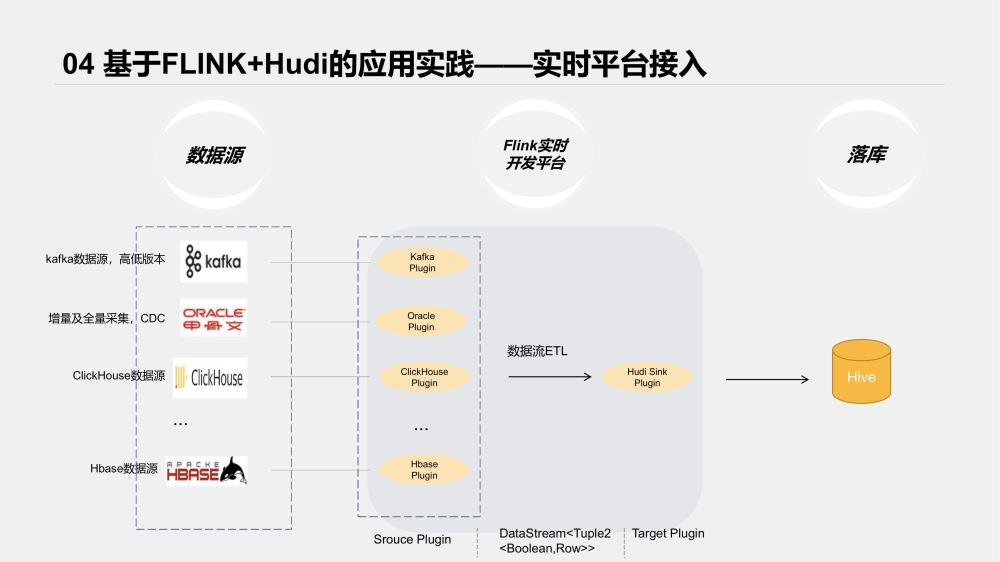
實時平臺對各類數據源及Sink端都以各類插件接入,我們參考了HudiFlinkTable的Sink流程,將Hudi接入了我們的實時開發平臺。
為了提高可用性,我們主要做了以下輔助功能;
Hive表元數據自動同步、更新;
Hudi schema自動拼接;
任務監控、Metrics數據接入等
實際使用過程如下
整套體系上線后,各業務線報表開發,實時在線分析等方面都有使用,比較好的賦能了業務,上線鏈路共26條,單日數據落入約3億條左右
后續主要圍繞如下幾個方面做探索
離線報表特點是 T - 1,凌晨跑數,以及報表整體依賴鏈路長。兩個特點導致時效性不高是一個方面,另一個方面是,數據依賴鏈路長的情況下,中間數據出問題容易導致后續整體依賴延時,而很多異常需要等到報表任務實際跑的時候,才能暴露出來。并且跑批問題凌晨暴露,解決的時效與資源協調都是要降低一個等級的,這對穩定性準時性要求的報表是不可接受的,特別是金融公司來說,通過把報表遷移至實時平臺,不僅僅是提升了報表的時效性,由于抽數及報表etl是一直再實時跑的,報表數據給出的穩定性能有一個較大的提升。這是我們Hudi實時落數據要應用的規劃之一
目前僅僅做到落數據任務的監控,即任務是否正常運行,有沒有拋異常等等。但實際使用者更關心數據由上游到Hive整條鏈路的監控情況。比如數據是否有延遲,是否有背壓,數據源消費情況,落數據是否有丟失,各個task是否有瓶頸等情況,總的來說,用戶希望能更全面細致的了解到任務的運行情況,這也是后面的監控需要完善的目標
這個是和上面的監控有類似的地方,用戶希望確定,一條數據從數據源接進來,經過各個算子的處理,它的一些詳細情況。比如這個數據是否應該被過濾,處于哪個窗口,各個算子的處理時間等等,否則對于用戶,整個數據SQL處理流程是一個黑盒。
以上是“Apache Hudi結合Flink的示例分析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





