溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“MySQL中的事務和MVCC原理是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“MySQL中的事務和MVCC原理是什么”文章吧。

數據庫事務指的是一組數據操作,事務內的操作要么就是全部成功,要么就是全部失敗,什么都不做,其實不是沒做,是可能做了一部分但是只要有一步失敗,就要回滾所有操作,有點一不做二不休的意思。
在 MySQL 中,事務支持是在引擎層實現的。MySQL 是一個支持多引擎的系統,但并不是所有的引擎都支持事務。比如 MySQL 原生的 MyISAM 引擎就不支持事務,這也是 MyISAM 被 InnoDB 取代的重要原因之一。
1.1 四大特性
原子性(Atomicity):事務開始后所有操作,要么全部做完,要么全部不做,不可能停滯在中間環節。事務執行過程中出錯,會回滾到事務開始前的狀態,所有的操作就像沒有發生一樣。也就是說事務是一個不可分割的整體,就像化學中學過的原子,是物質構成的基本單位。
一致性(Consistency):事務開始前和結束后,數據庫的完整性約束沒有被破壞 。比如 A 向 B 轉賬,不可能 A 扣了錢,B 卻沒收到。
隔離性(Isolation):同一時間,只允許一個事務請求同一數據,不同的事務之間彼此沒有任何干擾。比如 A 正在從一張銀行卡中取錢,在 A 取錢的過程結束前,B 不能向這張卡轉賬。
持久性(Durability):事務完成后,事務對數據庫的所有更新將被保存到數據庫,不能回滾。
1.2 隔離級別
SQL 事務的四大特性中原子性、一致性、持久性都比較好理解。但事務的隔離級別確實比較難的,今天主要聊聊 MySQL 事務的隔離性。
SQL 標準的事務隔離從低到高級別依次是:讀未提交(read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(serializable )。級別越高,效率越低。
讀未提交:一個事務還沒提交時,它做的變更就能被別的事務看到。
讀提交:一個事務提交之后,它做的變更才會被其他事務看到。
可重復讀:一個事務執行過程中看到的數據,總是跟這個事務在啟動時看到的數據是一致的。當然在可重復讀隔離級別下,未提交變更對其他事務也是不可見的。
串行化:顧名思義是對于同一行記錄,“寫” 會加 “寫鎖”,“讀” 會加 “讀鎖”。當出現讀寫鎖沖突的時候,后訪問的事務必須等前一個事務執行完成,才能繼續執行。所以種隔離級別下所有的數據是最穩定的,但是性能也是最差的。
1.3 解決的并發問題
SQL 事務隔離級別的設計就是為了能最大限度的解決并發問題:
臟讀:事務 A 讀取了事務 B 更新的數據,然后 B 回滾操作,那么 A 讀取到的數據是臟數據
不可重復讀:事務 A 多次讀取同一數據,事務 B 在事務 A 多次讀取的過程中,對數據作了更新并提交,導致事務 A 多次讀取同一數據時,結果不一致。
幻讀:系統管理員 A 將數據庫中所有學生的成績從具體分數改為 ABCDE 等級,但是系統管理員 B 就在這個時候插入了一條具體分數的記錄,當系統管理員 A 改結束后發現還有一條記錄沒有改過來,就好像發生了幻覺一樣,這就叫幻讀。
SQL 不同的事務隔離級別能解決的并發問題也不一樣,如下表所示:只有串行化的隔離級別解決了全部這 3 個問題,其他的 3 個隔離級別都有缺陷。
| 事務隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|
| 讀未提交 | 可能 | 可能 | 可能 |
| 讀已提交 | 不可能 | 可能 | 可能 |
| 可重復讀 | 不可能 | 不可能 | 可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
PS:不可重復讀的和幻讀很容易混淆,不可重復讀側重于修改,幻讀側重于新增或刪除。解決不可重復讀的問題只需鎖住滿足條件的行,解決幻讀需要鎖表
1.4 舉個栗子
這么說可能有點難以理解,舉個栗子。還是之前的表結構以及表數據
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` int(11) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 66 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
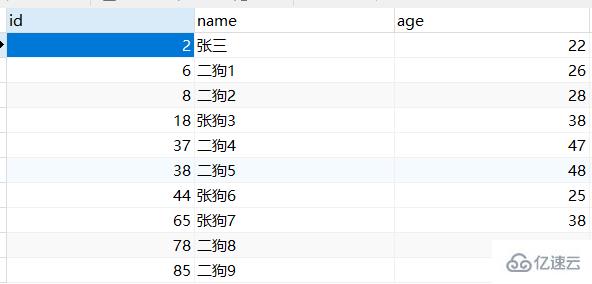
假設現在,我要同時啟動兩個食物,一個事務 A 查詢 id = 2 的學生的 age,一個事務 B 更新 id = 2 的學生的 age。流程如下,在四種隔離級別下的 X1、X2、X3 的值分別是怎樣的呢?

讀未提交:X1 的值是 23,因為事務 B 雖然沒提交但它的更改已被 A 看到。(如果 B 后面又回滾了 X1 的值就是臟的)。X2、X3 的值也是 23,這無可厚非。
讀已提交:X1 的值是 22,因為 B 雖然改了,但 A 看不到。(如果 B 后面回滾了,X1 的值不變,解決了臟讀),X2、X3 的值是 23,沒毛病,B 提交了,A 才能看到。
可重復讀:X1、X2 都是 22,A 開啟的時刻值是 22,那么在 A 的整個過程中,它的值都是 22。(不管 B 在這期間怎么修改,只要 A 還沒提交,都是看不見的,解決了不可重復讀),而 X3 的值是 23,因為 A 提交了,能看到 B 修改的值了。
串行化:B 在執行更改期間會被鎖住,直至 A 提交。B 才能繼續執行。(A 在讀期間,B 不能寫。得保證此時數據是最新的。解決了幻讀)所以 X1、X2 都是 22,而最后的 X3 在 B 提交之后執行,它的值就是 23。
那為什么會出現這樣的結果呢?事務隔離級別到底是怎么實現的呢?
事務隔離級別是怎么是實現的呢?我在極客時間丁奇老師的課上找到了答案:
實際上,數據庫里面會創建一個視圖,訪問的時候以視圖的邏輯結果為準。在 “可重復讀” 隔離級別下,這個視圖是在事務啟動時創建的,整個事務存在期間都用這個視圖。在 “讀提交” 隔離級別下,這個視圖是在每個 SQL 語句開始執行的時候創建的。這里需要注意的是,“讀未提交” 隔離級別下直接返回記錄上的最新值,沒有視圖概念;而 “串行化” 隔離級別下直接用加鎖的方式來避免并行訪問。
1.5 設置事務隔離級別
不同的數據庫默認設置的事務隔離級別也大不一樣,Oracle 數據庫的默認隔離級別是讀提交,而 MySQL 是可重復讀。所以,當你的系統需要把數據庫從 Oracle 遷移到 MySQL 時,請把級別設置成與搬遷之前的(讀提交)一致,避免出現不可預測的問題。
1.5.1 查看事務隔離級別
# 查看事務隔離級別 5.7.20 之前 SELECT @@transaction_isolation show variables like 'transaction_isolation'; # 5.7.20 以及之后 SELECT @@tx_isolation show variables like 'tx_isolation' +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | tx_isolation | REPEATABLE-READ | +---------------+-----------------+
1.5.2 設置隔離級別
修改隔離級別語句格式是:set [作用域] transaction isolation level [事務隔離級別]
其中作用域可選:SESSION(會話)、GLOBAL(全局);隔離級別就是上面提到的 4 種,不區分大小寫。
例如:設置全局隔離級別為讀提交
set global transaction isolation level read committed;
1.6 事務的啟動
MySQL 的事務啟動有以下幾種方式:
顯式啟動事務語句, begin 或 start transaction。配套的提交語句是 commit,或者回滾語句是 rollback。
# 更新學生名字 START TRANSACTION; update student set name = '張三' where id = 2; commit;
set autocommit = 0,這個命令會將線程的自動提交關掉。意味著如果你只執行一個 select 語句,這個事務就啟動了,而且并不會自動提交。這個事務持續存在直到你主動執行 commit 或 rollback 語句,或者斷開連接。
set autocommit = 1,表示 MySQL 自動開啟和提交事務。 比如執行一個 update 語句,語句只完成后就自動提交了。不需要顯示的使用 begin、commit 來開啟和提交事務。所以當我們執行多個語句的時候,就需要手動的用 begin、commit 來開啟和提交事務。
start transaction with consistent snapshot;上面提到的 begin/start transaction 命令并不是一個事務的起點,在執行到它們之后的第一個操作 InnoDB 表的語句,事務才真正啟動。如果你想要馬上啟動一個事務,可以使用 start transaction with consistent snapshot 命令。 第一種啟動方式,一致性視圖是在執行第一個快照讀語句時創建的; 第二種啟動方式,一致性視圖是在執行 start transaction with consistent snapshot 時創建的。
理解了隔離級別,那事務的隔離是怎么實現的呢?要想理解事務隔離,先得了解 MVCC 多版本的并發控制這個概念。而 MVCC 又依賴于 undo log 和 read view 實現。
2.1 什么是 MVCC?
百度上的解釋是這樣的:
MVCC,全稱 Multi-Version Concurrency Control,即多版本并發控制。MVCC 是一種并發控制的方法,一般在數據庫管理系統中,實現對數據庫的并發訪問,在編程語言中實現事務內存。
MVCC 使得數據庫讀不會對數據加鎖,普通的 SELECT 請求不會加鎖,提高了數據庫的并發處理能力;數據庫寫才會加鎖。 借助 MVCC,數據庫可以實現 READ COMMITTED,REPEATABLE READ 等隔離級別,用戶可以查看當前數據的前一個或者前幾個歷史版本,保證了 ACID 中的 I 特性(隔離性)。
MVCC 只在 REPEATABLE READ 和 READ COMMITIED 兩個隔離級別下工作。其他兩個隔離級別都和 MVCC 不兼容 ,因為 READ UNCOMMITIED 總是讀取最新的數據行,而不是符合當前事務版本的數據行。而 SERIALIZABLE 則會對所有讀取的行都加鎖。
2.1.1 InnDB 中的 MVCC
InnDB 中每個事務都有一個唯一的事務 ID,記為 transaction_id。它在事務開始時向 InnDB 申請,按照時間先后嚴格遞增。
而每行數據其實都有多個版本,這就依賴 undo log 來實現了。每次事務更新數據就會生成一個新的數據版本,并把 transaction_id 記為 row trx_id。同時舊的數據版本會保留在 undo log 中,而且新的版本會記錄舊版本的回滾指針,通過它直接拿到上一個版本。
所以,InnDB 中的 MVCC 其實是通過在每行記錄后面保存兩個隱藏的列來實現的。一列是事務 ID:trx_id;另一列是回滾指針:roll_pt。
2.2 undo log
回滾日志保存了事務發生之前的數據的一個版本,可以用于回滾,同時可以提供多版本并發控制下的讀(MVCC),也即非鎖定讀。
根據操作的不同,undo log 分為兩種: insert undo log 和 update undo log。
2.2.1 insert undo log
insert 操作產生的 undo log,因為 insert 操作記錄沒有歷史版本只對當前事務本身可見,對于其他事務此記錄不可見,所以 insert undo log 可以在事務提交后直接刪除而不需要進行 purge 操作。
purge 的主要任務是將數據庫中已經 mark del 的數據刪除,另外也會批量回收 undo pages
所以,插入數據時。它的初始狀態是這樣的:
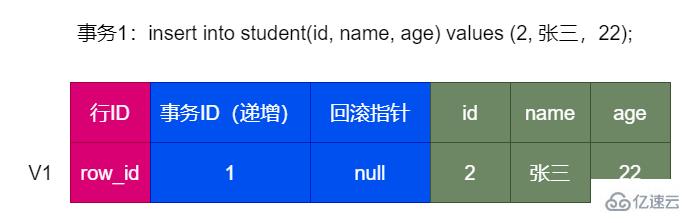
2.2.2 update undo log
UPDATE 和 DELETE 操作產生的 Undo log 都屬于同一類型:update_undo。(update 可以視為 insert 新數據到原位置,delete 舊數據,undo log 暫時保留舊數據)。
事務提交時放到 history list 上,沒有事務要用到這些回滾日志,即系統中沒有比這個回滾日志更早的版本時,purge 線程將進行最后的刪除操作。
一個事務修改當前數據:
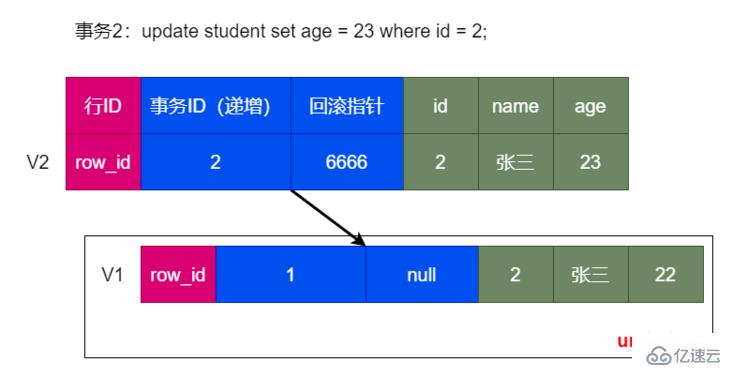
另一個事務修改數據:
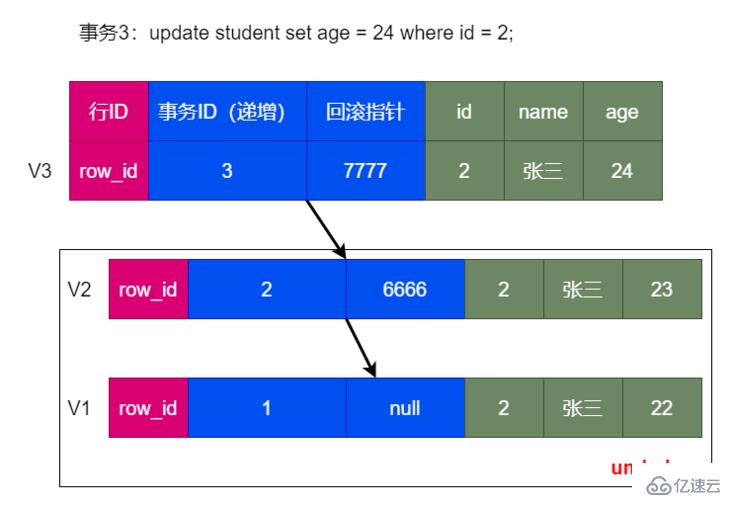
這樣的同一條記錄在數據庫中存在多個版本,就是上面提到的多版本并發控制 MVCC。
另外,借助 undo log 通過回滾可以回到上一個版本狀態。比如要回到 V1 只需要順序執行兩次回滾即可。
2.3 read-view
read view 是 InnDB 在實現 MVCC 時用到的一致性讀視圖,用于支持 RC(讀提交)以及 RR(可重復讀)隔離級別的實現。
read view 不是真實存在的,只是一個概念,undo log 才是它的體現。它主要是通過版本和 undolog 計算出來的。作用是決定事務能看到哪些數據。
每個事務或者語句有自己的一致性視圖。普通查詢語句是一致性讀,一致性讀會根據 row trx_id 和一致性視圖確定數據版本的可見性。
2.3.1 數據版本的可見性規則
read view 中主要包含當前系統中還有哪些活躍的讀寫事務,在實現上 InnDB 為每個事務構造了一個數組,用來保存這個事務啟動瞬間,當前正活躍(還未提交)的事務。
前面說了事務 ID 隨時間嚴格遞增的,把系統中已提交的事務 ID 的最大值記為數組的低水位,已創建過的事務 ID + 1記為高水位。
這個視圖數組和高水位就組成了當前事務的一致性視圖(read view)
這個數組畫個圖,長這樣:
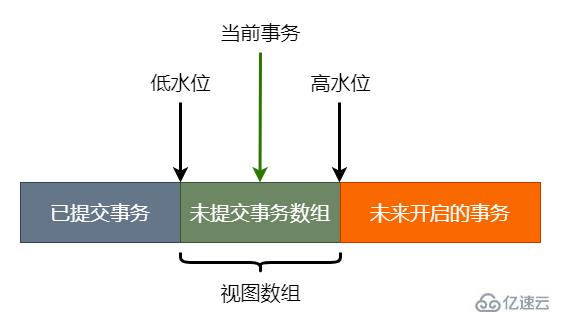
規則如下:
1 如果 trx_id 在灰色區域,表明被訪問版本的 trx_id 小于數組中低水位的 id 值,也即生成該版本的事務在生成 read view 前已經提交,所以該版本可見,可以被當前事務訪問。
2 如果 trx_id 在橙色區域,表明被訪問版本的 trx_id 大于數組中高水位的 id 值,也即生成該版本的事務在生成 read view 后才生成,所以該版本不可見,不能被當前事務訪問。
3 如果在綠色區域,就會有兩種情況:
a) trx_id 在數組中,證明這個版本是由還未提交的事務生成的,不可見
b) trx_id 不在數組中,證明這個版本是由已提交的事務生成的,可見
第三點我在看教程的時候也有點疑惑,好在有熱心網友解答:
落在綠色區域意味著是事務 ID 在低水位和高水位這個范圍里面,而真正是否可見,看綠色區域是否有這個值。如果綠色區域沒有這個事務 ID,則可見,如果有,則不可見。在這個范圍里面并不意味著這個范圍就有這個值,比如 [1,2,3,5],4 在這個數組 1-5 的范圍里,卻沒在這個數組里面。
這樣說可能有點難以理解,我假設一個場景:三個事務對同一條數據進行查詢更新等操作,為此畫了張圖以方便理解:
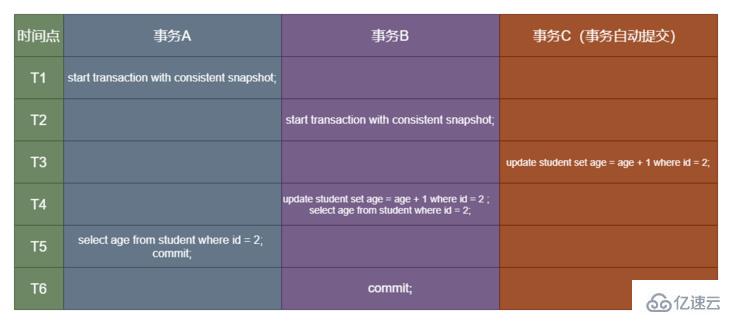
原始數據還是下圖這樣的,對 id = 2 的張三進行信息的更新:
針對上圖,我想提個問題。分別在 RC(讀提交)以及 RR(可重復讀)隔離級別下,T4 和 T5 時間點的查詢 age 值分別是多少呢?T4 更新的值又是多少呢?思考片刻,相信大家都有自己的答案。答案在文末,希望大家能帶著自己的疑問繼續讀下去。
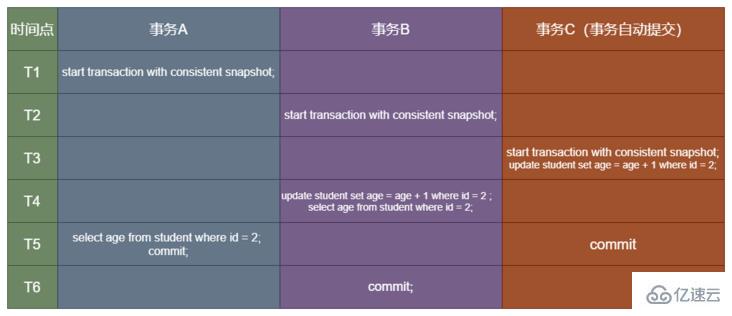
2.3.2 RR(可重復讀)下的結果
RR 級別下,查詢只承認在事務啟動前就已經提交完成的數據,一旦啟動事務就會建視圖。所以使用 start transaction with consistent snapshot 命令,馬上就會建視圖。
現在假設:
事務 A 開始前,只有一個活躍的事務,ID = 2,
已提交的事務也就是插入數據的事務 ID = 1
事務 A、B、C 的事務 ID 分別是 3、4、5
在這種隔離級別下,他們創建視圖的時刻如下:

根據上圖得,事務 A 的視圖數組是[2,3];事務 B 的視圖數組是 [2,3,4];事務 C 的視圖數組是[2,3,4,5]。分析一波:
T4 時刻,B 讀數據都是從當前版本讀起,過程是這樣的:
讀到當前版本的 trx_id = 4,剛好是自己,可見
所以 age = 24
T5 時刻,A 讀數據都是從當前版本讀起,過程是這樣的:
讀到當前版本的 trx_id = 4,比自己視圖數組的高水位大,不可見
再往上讀到 trx_id = 5,比自己視圖數組高水位大,不可見
再往上讀到 trx_id = 1,比自己視圖數組低水位小,可見
所以 age = 22
這樣執行下來,雖然期間這一行數據被修改過,但是事務 A 不論在什么時候查詢,看到這行數據的結果都是一致的,所以我們稱之為一致性讀。
其實視圖是否可見主要看創建視圖和提交的時機,總結下規律:
版本未提交,不可見
版本已提交,但在視圖創建后提交,不可見
版本已提交,但在視圖創建前提交,可見
事務 B 的 update 語句,如果按照上圖的一致性讀,好像結果不大對?
如下圖周明,B 的視圖數組是先生成的,之后事務 C 才提交。那就應該看不見 C 修改的 age = 23 呀?最后 B 怎么得出 24 了?

沒錯,如果 B 在更新之前執行查詢語句,那返回的結果肯定是 age = 22。問題是更新就不能在歷史版本更新了呀,否則 C 的更新不就丟失了?
所以,更新有個規則:更新數據都是先讀后寫(讀是更新語句執行,不是我們手動執行),讀的就是當前版本的值,叫當前讀;而我們普通的查詢語句就叫快照讀。
因此,在更新時,當前讀讀到的是 age = 23,更新之后就成 24 啦。
除了更新語句,查詢語句如果加鎖也是當前讀。如果把事務 A 的查詢語句 select age from t where id = 2 改一下,加上鎖(lock in mode 或者 for update),也都可以得到當前版本 4 返回的 age = 24
下面就是加了鎖的 select 語句:
select age from t where id = 2 lock in mode; select age from t where id = 2 for update;
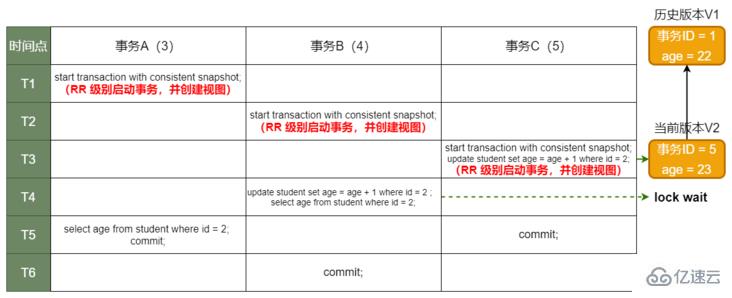
假設事務 C 不馬上提交,但是 age = 23 版本已生成。事務 B 的更新將會怎么走呢?
事務 C 還沒提交,寫鎖還沒釋放,但是事務 B 的更新必須要當前讀且必須加鎖。所以事務 B 就阻塞了,必須等到事務 C 提交,釋放鎖才能繼續當前的讀。
2.3.3 RC(讀提交)下的結果
在讀提交隔離級別下,查詢只承認在語句啟動前就已經提交完成的數據;每一個語句執行之前都會重新算出一個新的視圖。
注意:在上圖的表格中用于啟動事務的是 start transaction with consistent snapshot 命令,它會創建一個持續整個事務的視圖。所以,在 RC 級別下,這命令其實不起作用。等效于普通的 start transaction(在執行 sql 語句之前才算是啟動了事務)。所以,事務 B 的更新其實是在事務 C 之后的,它還沒真正啟動事務,而 C 已提交。
現在假設:
事務 A 開始前,只有一個活躍的事務,ID = 2,
已提交的事務也就是插入數據的事務 ID = 1
事務 A、B、C 的事務 ID 分別是 3、4、5
在這種隔離級別下,他們創建視圖的時刻如下:

根據上圖得,事務 A 的視圖數組是[2,3,4],但它的高水位是 6或者更大(已創建事務 ID + 1);事務 B 的視圖數組是 [2,4];事務 C 的視圖數組是 [2,5]。分析一波:
T4 時刻,B 讀數據都是從當前版本讀起,過程是這樣的:
讀到當前版本的 trx_id = 4,剛好是自己,可見
所以 age = 24
T5 時刻,A 讀數據都是從當前版本讀起,過程是這樣的:
讀到當前版本的 trx_id = 4,在自己一致性視圖范圍內但包含 4,不可見
再往上讀到 trx_id = 5,在自己一致性視圖范圍內但不包含 5,可見
所以 age = 23
以上就是關于“MySQL中的事務和MVCC原理是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





