溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么用python代碼實現爬取奧特曼圖片”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么用python代碼實現爬取奧特曼圖片”吧!
爬取網址:http://www.ultramanclub.com/allultraman/
使用工具:pycharm,requests
進入網頁
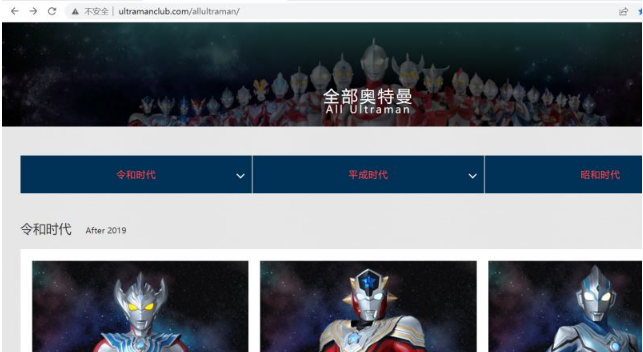
打開開發者工具
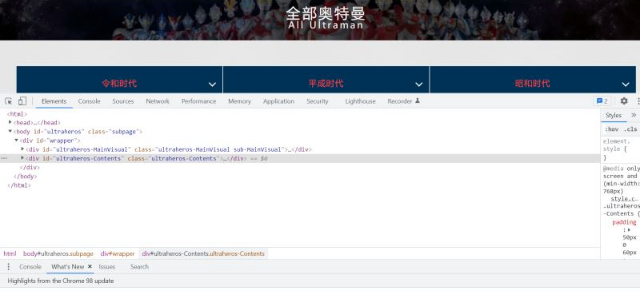
點擊 Network
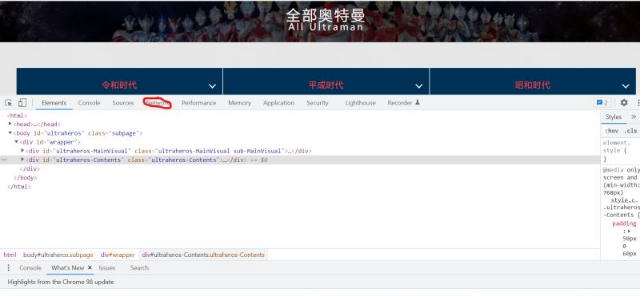
刷新網頁,獲取信息
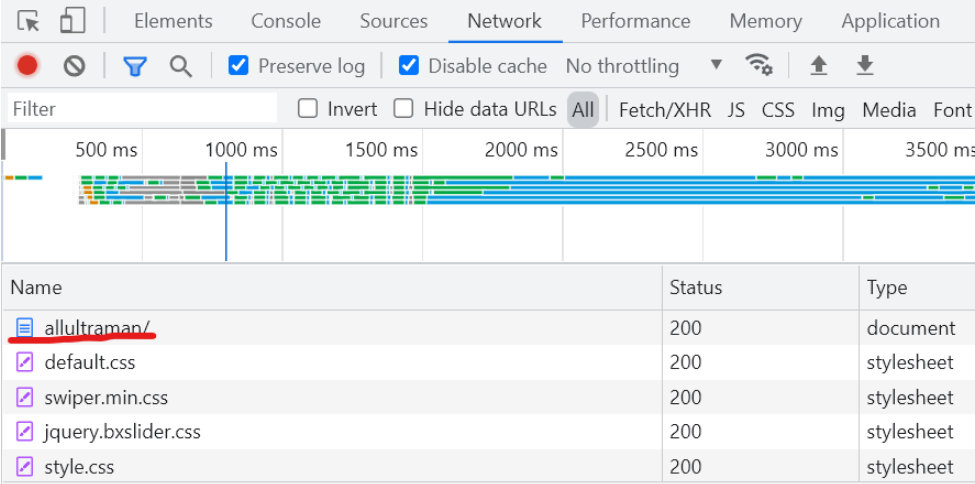
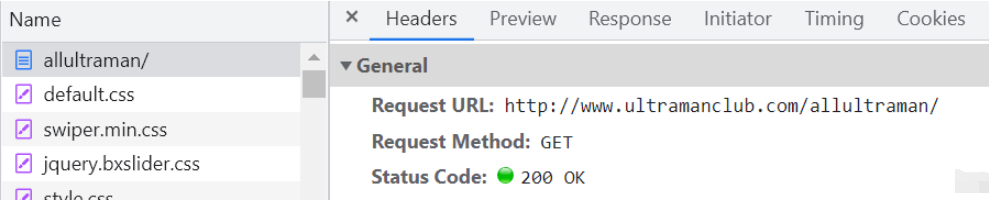
其中的Request URL就是我們所爬取的網址
滑到最下有一個User-Agent,復制
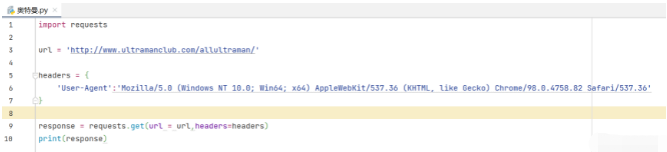
向服務器發送請求

200意味著請求成功
使用 response.text 獲取文本數據
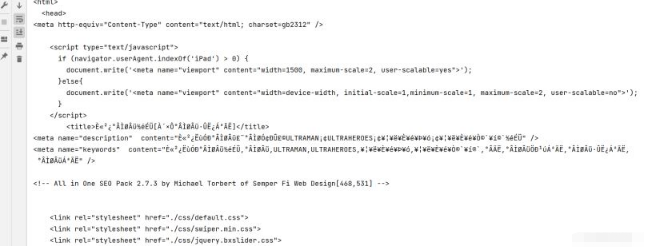
可以看到有些亂碼
使用encode轉換
import requests
url = 'http://www.ultramanclub.com/allultraman/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = url,headers=headers)
html = response.text
Html=html.encode('iso-8859-1').decode('gbk')
print(Html)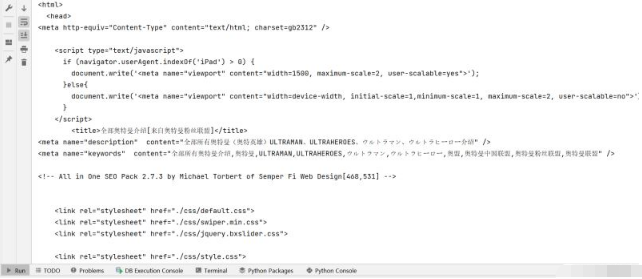
接下來開始爬取需要的數據
使用Xpath獲得網頁鏈接
要使用Xpath必須先導入parsel包
import requests
import parsel
def get_response(html_url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = html_url,headers=headers)
return response
url = 'http://www.ultramanclub.com/allultraman/'
response = get_response(url)
html=response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(html)
period_hrefs = selector.xpath('//div[@class="btn"]/a/@href') #獲取三個時代的網頁鏈接
for period_href in period_hrefs:
print(period_href.get())
可以看到網頁鏈接不完整,我們手動給它添加上去period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()

進入其中一個網頁
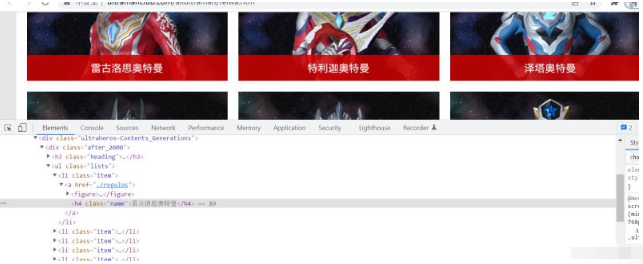
跟之前的操作一樣,用Xpath獲取奧特曼的網頁信息
for period_href in period_hrefs:
period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()
# print(period_href)
period_response = get_response(period_href).text
period_html = parsel.Selector(period_response)
lis = period_html.xpath('//div[@class="ultraheros-Contents_Generations"]/div/ul/li/a/@href')
for li in lis:
print(li.get())運行后同樣發現鏈接不完整
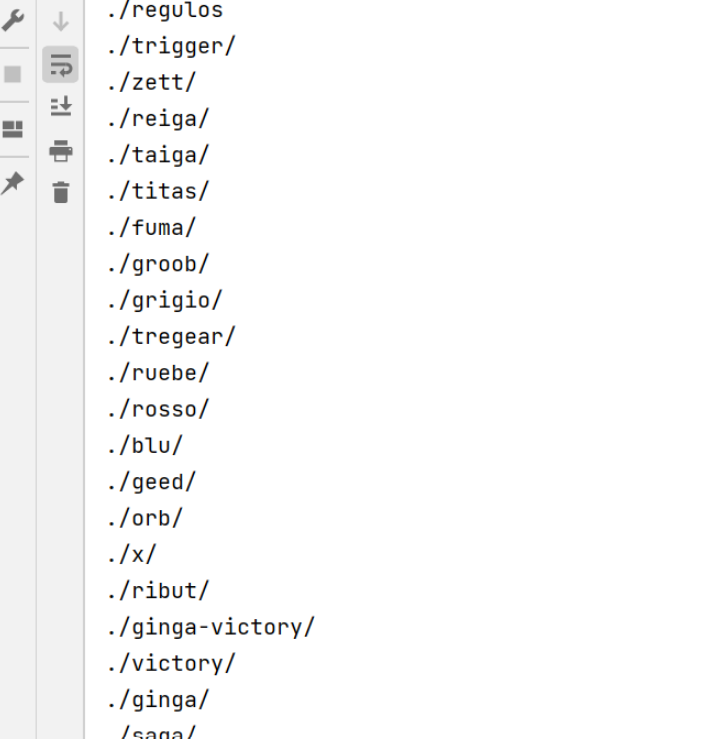
li = 'http://www.ultramanclub.com/allultraman/' + li.get().replace('./','')

拿到網址后繼續套娃操作,就可以拿到圖片數據
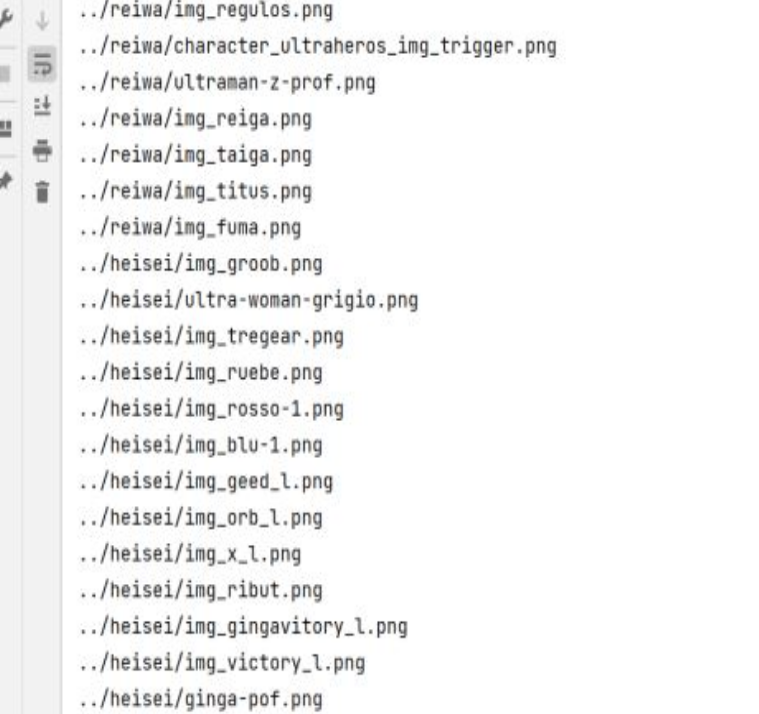
png_url = 'http://www.ultramanclub.com/allultraman/' + li_selector.xpath('//div[@class="left"]/figure/img/@src').get().replace('../','')
完整代碼
import requests
import parsel
import os
dirname = "奧特曼"
if not os.path.exists(dirname): #判斷是否存在名稱為奧特曼的文件夾,沒有就創建
os.mkdir(dirname)
def get_response(html_url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
response = requests.get(url = html_url,headers=headers)
return response
url = 'http://www.ultramanclub.com/allultraman/'
response = get_response(url)
html=response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(html)
period_hrefs = selector.xpath('//div[@class="btn"]/a/@href') #獲取三個時代的網頁鏈接
for period_href in period_hrefs:
period_href = 'http://www.ultramanclub.com/allultraman/' + period_href.get()
period_html = get_response(period_href).text
period_selector = parsel.Selector(period_html)
lis = period_selector.xpath('//div[@class="ultraheros-Contents_Generations"]/div/ul/li/a/@href')
for li in lis:
li = 'http://www.ultramanclub.com/allultraman/' + li.get().replace('./','') #獲取每個奧特曼的網址
# print(li)
li_html = get_response(li).text
li_selector = parsel.Selector(li_html)
url = li_selector.xpath('//div[@class="left"]/figure/img/@src').get()
# print(url)
if url:
png_url = 'http://www.ultramanclub.com/allultraman/' + url.replace('.', '')
png_title =li_selector.xpath('//ul[@class="lists"]/li[3]/text()').get()
png_title = png_title.encode('iso-8859-1').decode('gbk')
# print(li,png_title)
png_content = get_response(png_url).content
with open(f'{dirname}\\{png_title}.png','wb') as f:
f.write(png_content)
print(png_title,'圖片下載完成')
else:
continue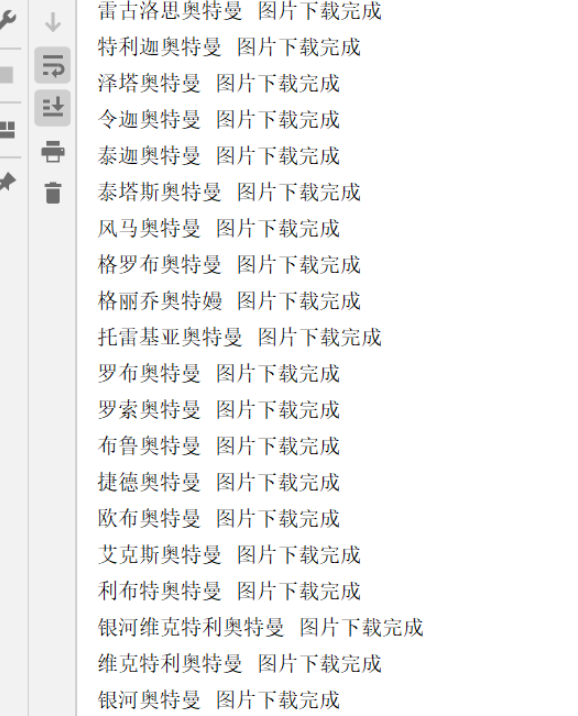
當爬到 奈克斯特奧特曼的時候,就會返回None,調了半天,也沒搞懂,所以用if url:語句跳過了奈克斯特奧特曼,有沒有大佬知道原因
url = li_selector.xpath('//div[@class="left"]/figure/img/@src').get()感謝各位的閱讀,以上就是“怎么用python代碼實現爬取奧特曼圖片”的內容了,經過本文的學習后,相信大家對怎么用python代碼實現爬取奧特曼圖片這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





